分布式训练框架IMPALA 开启智能体训练新时代
Posted 郑大创新创业基地北校区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式训练框架IMPALA 开启智能体训练新时代相关的知识,希望对你有一定的参考价值。
1
分布式训练框架IMPALA
开启智能体训练新时代

最近,DeepMind 推出一个全新的分布式智能体训练框架 IMPALA,它具有高度可扩展性,将学习和执行分开,使用了名为 V-trace 的离策略修正算法,具有显著的加速性能,极高的效率。具体如何呢,其原文编译整理如下:
深度强化学习 在一系列任务如机器人的连续控制问题、玩围棋等游戏中都取得很显著的成果。目前为止,人们看到的这些成果仅限于单一任务,每个任务都要单独对智能体进行调参和训练。
在最近的工作中,还研究了在多个任务中训练单个智能体。今天这是一组横跨很多挑战的新任务,在视觉统一的环境中,有着普通的行动空间。想训练好一个在许多任务上都有良好表现的智能体,需要大量的吞吐量并有效利用每个数据点。
为此,人们开发了一种高度可扩展的、全新的分布式智能体训练框架 IMPALA即重点加权行动-学习器框架,它使用了一种名为 V-trace 的离策略修正算法。


DMLab-30 是通过开源强化学习环境 DeepMind Lab 设计的一系列任务。任何深度强化学习的研究人员都能够在大范围的有趣任务中测试系统,支持单独测试和多任务环境测试。这些任务有着不同的目标,它们的视觉效果也各不相同,环境设置也不同,这里都存在着。
一些环境中还有“机器人”,他们会执行以目标为导向的行为。同样重要的是,任务不同,目标和奖励也会有所不同,比如遵循语言指令、使用钥匙开门、采摘蘑菇、绘制和跟踪一条复杂的不能回头的路径这些任务,最终目的和奖励都会有所不同。 然而,就行动空间和观察空间来说,任务的环境是一样的。可以在每个环境中对智能体进行训练。
为了在 DMLab-30 中训练那些挑战性的任务,人们开发了一个名为 IMPALA 的分布式智能体框架,它利用 TensorFlow 中高效的分布式框架来使数据吞吐量最大化。IMPALA 的灵感来自 A3C 框架,去使用多个分布式 actor 来学习智能体参数。在该模型中,每个 actor 都使用策略参数的克隆在环境中行动。actor 会周期性的暂停探索一个中央参数服务器计算的,会实时更新的共享梯度。
在 IMPALA 中,它不会用 actor 来计算梯度。它们只是用来收集经验去传递给计算梯度的中央学习器,从而得到一个拥有独立 actor 和 learner 的模型。
现代计算系统有诸多优势,IMPALA 可以利用其优势,用单个 learner 或多个 learner 进行同步更新。以这种方式将学习和行动分离,有助于提高整个系统的吞吐量,因为 actor 不再需要执行诸如Batched A2C 框架中的等待学习步骤。这使我们在环境中训练 IMPALA 时不会受到框架渲染时间的变动或任务重新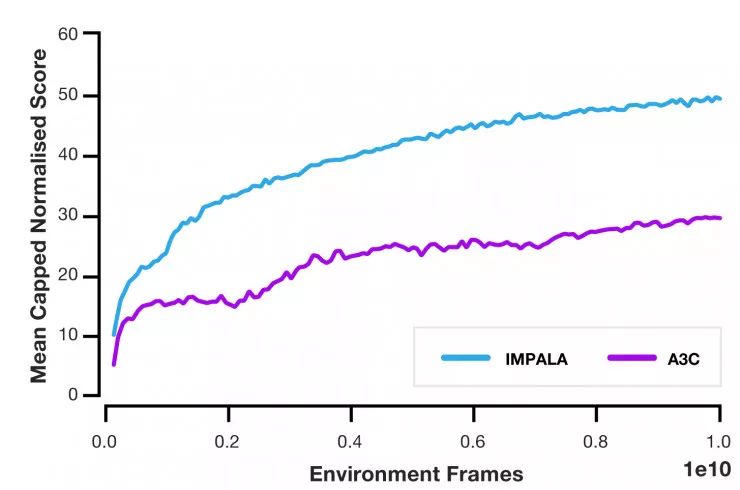
IMPALA 中的优化模型相对于类似智能体,能多处理 1 到 2 个数量级的经验,这使得在极具挑战的环境中进行学习成为可能。
人们将 IMPALA 与几个流行的 actor-critic 的方法进行了比较,发现它具有显著的加速效果。此外,使用 IMPALA 的情况下,随着 actor 和 learner 的增长,吞吐量几乎是按线性增长的。这表明,分布式智能体模型和 V-trace 算法都能支持极大规模的实验,支持的规模甚至可以达到上千台机器。
当在 DMLab-30 上进行测试时,与 A3C 相比,IMPALA 的数据效率提高了 10 倍,最终得分达到后者的两倍。此外,与单任务训练相比,IMPALA 在多任务环境下的训练呈正迁移趋势。

WE WISH YOU HAPPY
NEW YEAR
2018

编辑:晁嘉琳
摘自:CCF技术要闻
以上是关于分布式训练框架IMPALA 开启智能体训练新时代的主要内容,如果未能解决你的问题,请参考以下文章