Impala TPC-DS基准测试
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Impala TPC-DS基准测试相关的知识,希望对你有一定的参考价值。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
Fayson的github:https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1.文档编写目的
在前面Fayson介绍了《》,在生成的Hive基准测试数据的基础上,如何进行Impala的TPC-DS基准测试,本篇文章主要介绍如何准备Impala基准测试数据及使用99条SQL对Impala进行基准测试。
内容概述
1.环境准备
2.Impala基准测试数据准备
3.TPC-DS测试
测试环境
1.RedHat7.3
2.CM和CDH版本为5.13.1
前置条件
1.已使用hive-testbench生成好Hive的基准测试数据
2.环境准备
1.在《》文章中Fayson已生成好了2GB的测试数据,并创建好了Hive的外部表
2.登录Hue查看tpcds_text_2库下表
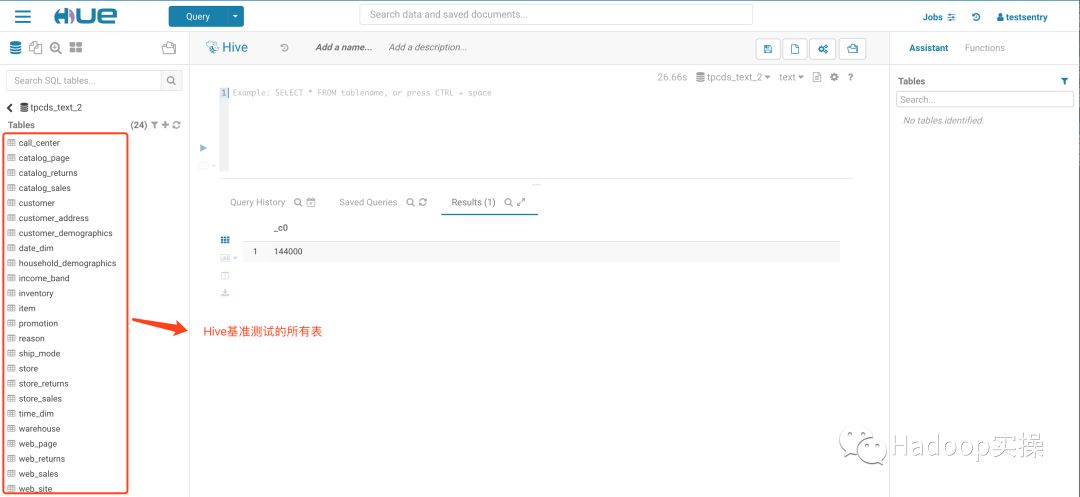
以上的环境准备具体可以参考Fayson前面的文章《》
3.准备Impala基准测试数据
我们基于hive-testbench生成的2GB的Hive基准测试数据来生成Impala Parquet格式的表,并对标执行统计分析操作,具体操作步骤及脚本如下:
1.创建SQL脚本alltables_parquet.sql用于生成parquet格式的表,内容如下
drop database if exists ${VAR:DB} cascade;
create database ${VAR:DB};
use ${VAR:DB};
set parquet_file_size=512M;
set COMPRESSION_CODEC=snappy;
drop table if exists call_center;
create table ${VAR:DB}.call_center
stored as parquet
as select * from ${VAR:HIVE_DB}.call_center;
drop table if exists catalog_page;
create table ${VAR:DB}.catalog_page
stored as parquet
as select * from ${VAR:HIVE_DB}.catalog_page;
drop table if exists catalog_returns;
create table ${VAR:DB}.catalog_returns
stored as parquet
as select * from ${VAR:HIVE_DB}.catalog_returns;
drop table if exists catalog_sales;
create table ${VAR:DB}.catalog_sales
stored as parquet
as select * from ${VAR:HIVE_DB}.catalog_sales;
drop table if exists customer_address;
create table ${VAR:DB}.customer_address
stored as parquet
as select * from ${VAR:HIVE_DB}.customer_address;
drop table if exists customer_demographics;
create table ${VAR:DB}.customer_demographics
stored as parquet
as select * from ${VAR:HIVE_DB}.customer_demographics;
drop table if exists customer;
create table ${VAR:DB}.customer
stored as parquet
as select * from ${VAR:HIVE_DB}.customer;
drop table if exists date_dim;
create table ${VAR:DB}.date_dim
stored as parquet
as select * from ${VAR:HIVE_DB}.date_dim;
drop table if exists household_demographics;
create table ${VAR:DB}.household_demographics
stored as parquet
as select * from ${VAR:HIVE_DB}.household_demographics;
drop table if exists income_band;
create table ${VAR:DB}.income_band
stored as parquet
as select * from ${VAR:HIVE_DB}.income_band;
drop table if exists inventory;
create table ${VAR:DB}.inventory
stored as parquet
as select * from ${VAR:HIVE_DB}.inventory;
drop table if exists item;
create table ${VAR:DB}.item
stored as parquet
as select * from ${VAR:HIVE_DB}.item;
drop table if exists promotion;
create table ${VAR:DB}.promotion
stored as parquet
as select * from ${VAR:HIVE_DB}.promotion;
drop table if exists reason;
create table ${VAR:DB}.reason
stored as parquet
as select * from ${VAR:HIVE_DB}.reason;
drop table if exists ship_mode;
create table ${VAR:DB}.ship_mode
stored as parquet
as select * from ${VAR:HIVE_DB}.ship_mode;
drop table if exists store_returns;
create table ${VAR:DB}.store_returns
stored as parquet
as select * from ${VAR:HIVE_DB}.store_returns;
drop table if exists store_sales;
create table ${VAR:DB}.store_sales
stored as parquet
as select * from ${VAR:HIVE_DB}.store_sales;
drop table if exists store;
create table ${VAR:DB}.store
stored as parquet
as select * from ${VAR:HIVE_DB}.store;
drop table if exists time_dim;
create table ${VAR:DB}.time_dim
stored as parquet
as select * from ${VAR:HIVE_DB}.time_dim;
drop table if exists warehouse;
create table ${VAR:DB}.warehouse
stored as parquet
as select * from ${VAR:HIVE_DB}.warehouse;
drop table if exists web_page;
create table ${VAR:DB}.web_page
stored as parquet
as select * from ${VAR:HIVE_DB}.web_page;
drop table if exists web_returns;
create table ${VAR:DB}.web_returns
stored as parquet
as select * from ${VAR:HIVE_DB}.web_returns;
drop table if exists web_sales;
create table ${VAR:DB}.web_sales
stored as parquet
as select * from ${VAR:HIVE_DB}.web_sales;
drop table if exists web_site;
create table ${VAR:DB}.web_site
stored as parquet
as select * from ${VAR:HIVE_DB}.web_site;
(可左右滑动)
注意:在脚本中使用了${VAR:variable_name}动态传参的方式指定Hive数据库及Impala的数据库。
2.在Impala Daemon节点执行如下命令,生成Impala基准测试数据
[root@ip-172-31-30-69 ~]# impala-shell -i ip-172-31-30-69.ap-southeast-1.compute.internal --var=DB=tpcds_parquet_2 --var=HIVE_DB=tpcds_text_2 -f alltables_parquet.sql
(可左右滑动)
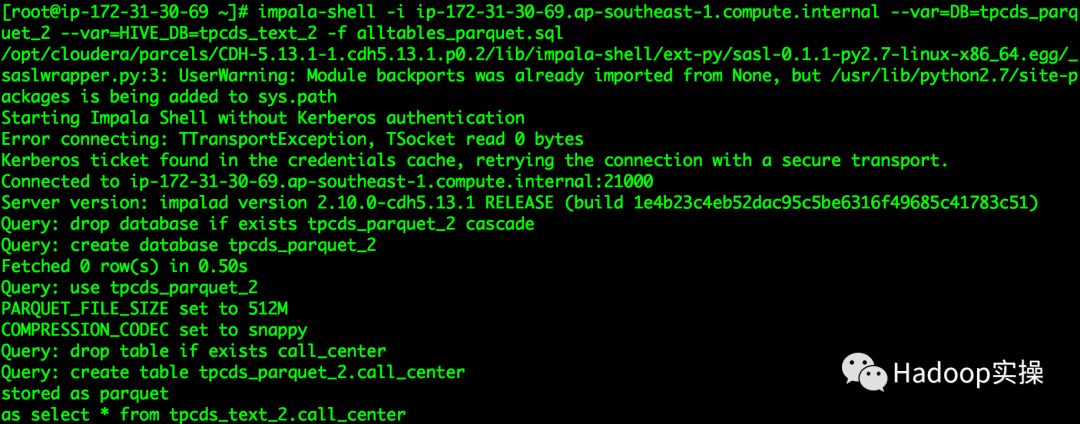
等待命令执行成功,登录Impala查看数据库及对应的表是否创建成功
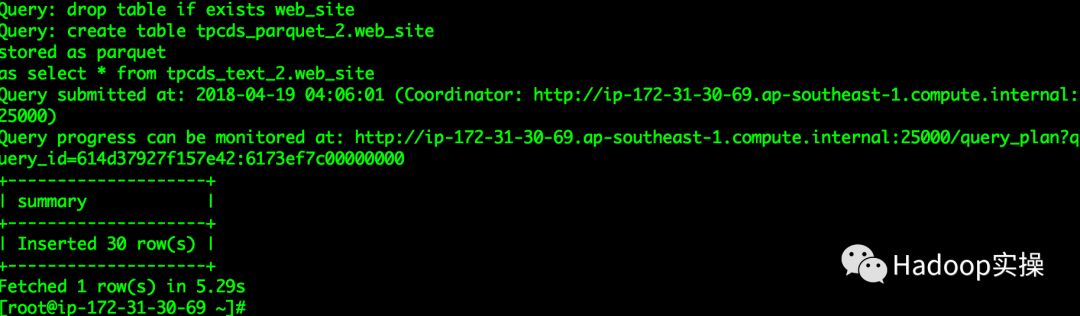
tpcds_parquet_2的数据库已创建
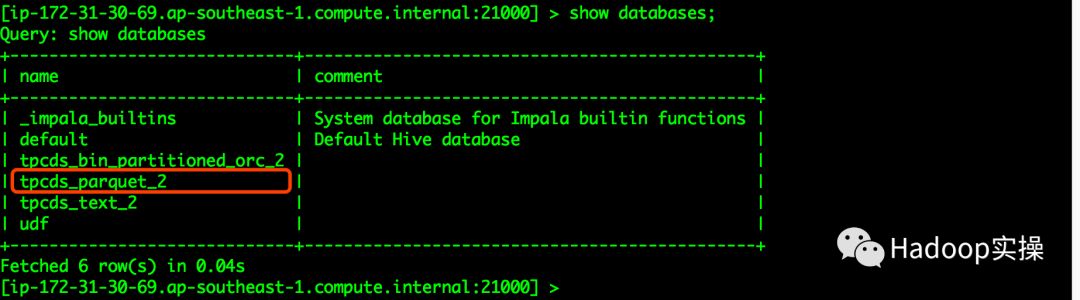
tpcds_parquet_2库中的表与tpcds_text_2库中表一致,数据量一致。
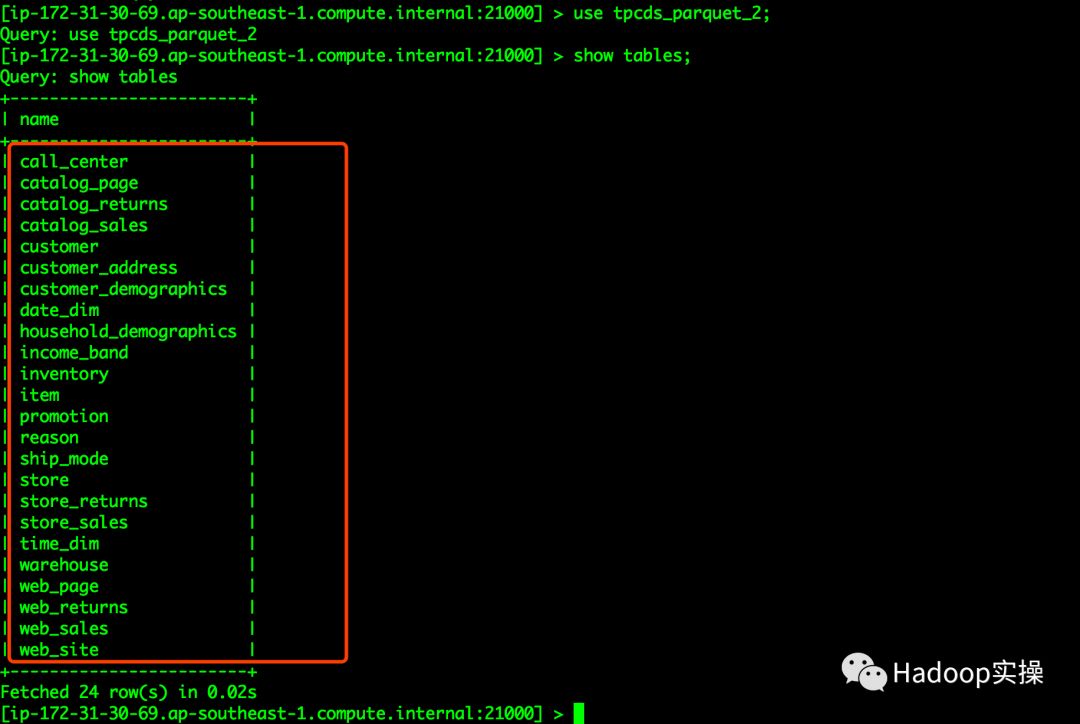
3.创建analyze.sql,用于统计分析Impala的表
use ${VAR:DB};
compute stats call_center ;
compute stats catalog_page ;
compute stats catalog_returns ;
compute stats catalog_sales ;
compute stats customer_address ;
compute stats customer_demographics ;
compute stats customer ;
compute stats date_dim ;
compute stats household_demographics ;
compute stats income_band ;
compute stats inventory ;
compute stats item ;
compute stats promotion ;
compute stats reason ;
compute stats ship_mode ;
compute stats store_returns ;
compute stats store_sales ;
compute stats store ;
compute stats time_dim ;
compute stats warehouse ;
compute stats web_page ;
compute stats web_returns ;
compute stats web_sales ;
compute stats web_site ;
(可左右滑动)
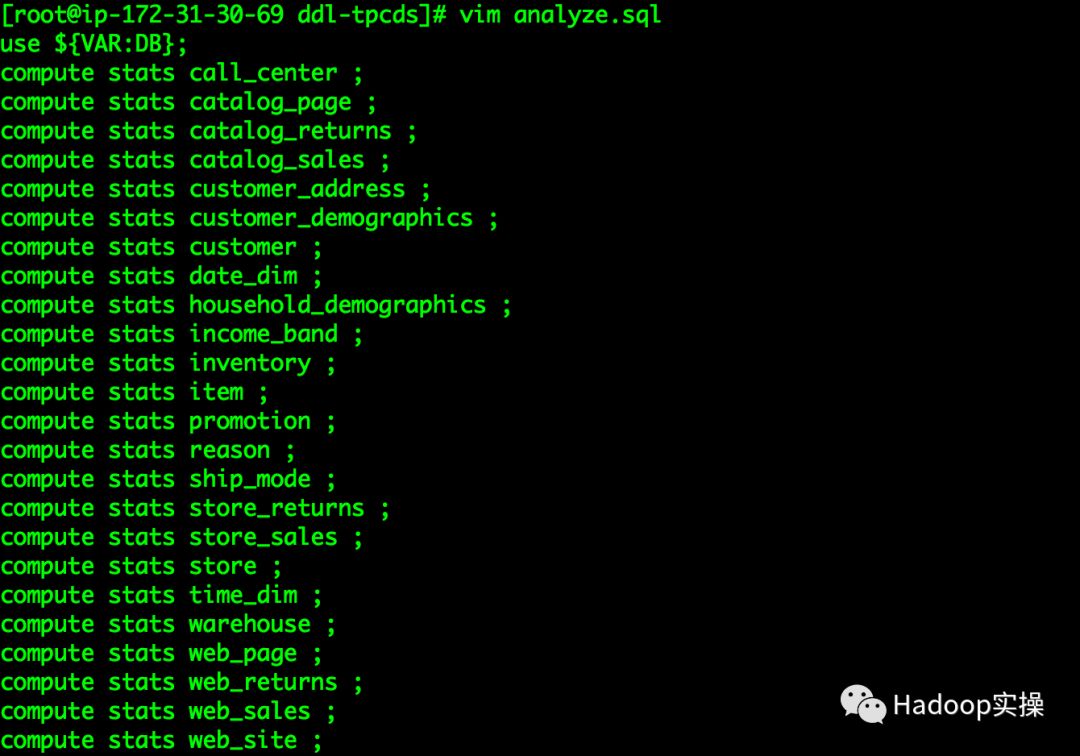
4.执行如下命令对Impala的表进行统计分析
[root@ip-172-31-30-69 ddl-tpcds]# impala-shell -i ip-172-31-30-69.ap-southeast-1.compute.internal --var=DB=tpcds_parquet_2 -f analyze.sql
(可左右滑动)
至此已完成Impala基准测试的环境准备。
4.TPC-DS测试
1.准备好TPC-DS的99条SQL语句,这里的99条SQL就不贴出来了Fayson会放到GitHub上
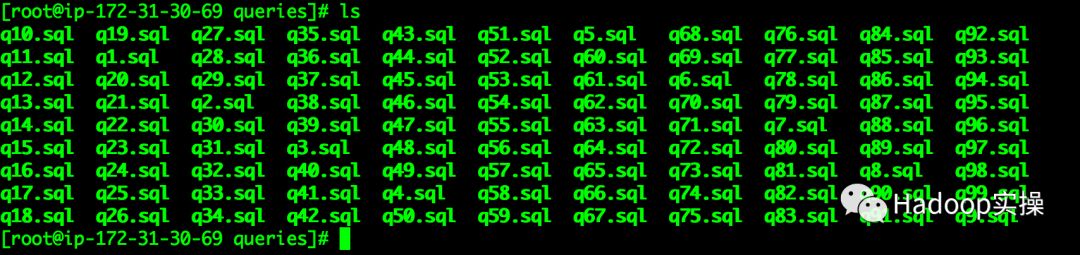
2.编写批量运行脚本run_all_queries.sh,将结果输出到日志文件
[root@ip-172-31-30-69 impala-tpcds]# vim run_all_queries.sh
#!/bin/bash
impala_demon=ip-172-31-30-69.ap-southeast-1.compute.internal
database_name=tpcds_parquet_2
current_path=`pwd`
queries_dir=${current_path}/queries
rm -rf logs
mkdir logs
for t in `ls ${queries_dir}`
do
echo "current query will be ${queries_dir}/${t}"
impala-shell --database=$database_name -i $impala_demon -f ${queries_dir}/${t} &>logs/${t}.log
done
echo "all queries execution are finished, please check logs for the result!"
(可左右滑动)
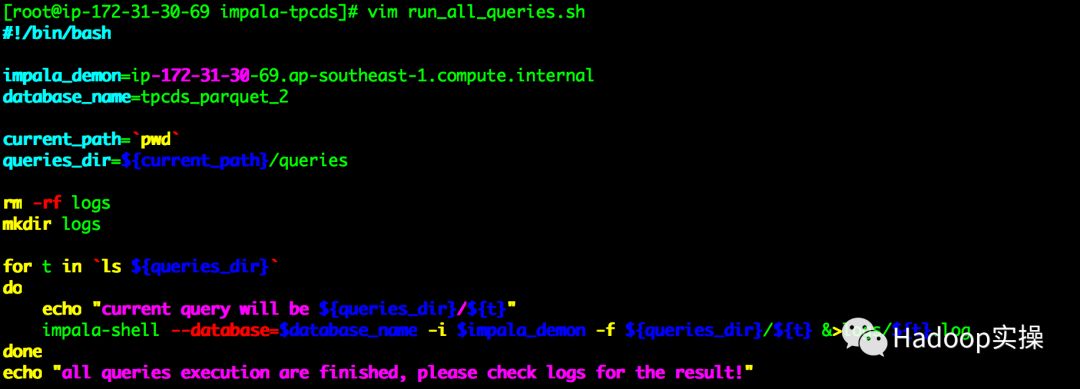
将脚本中impala_daemon和database_name修改为你自己环境的配置即可。
3.脚本执行成功后可以在logs目录下查看执行结果及运行时间
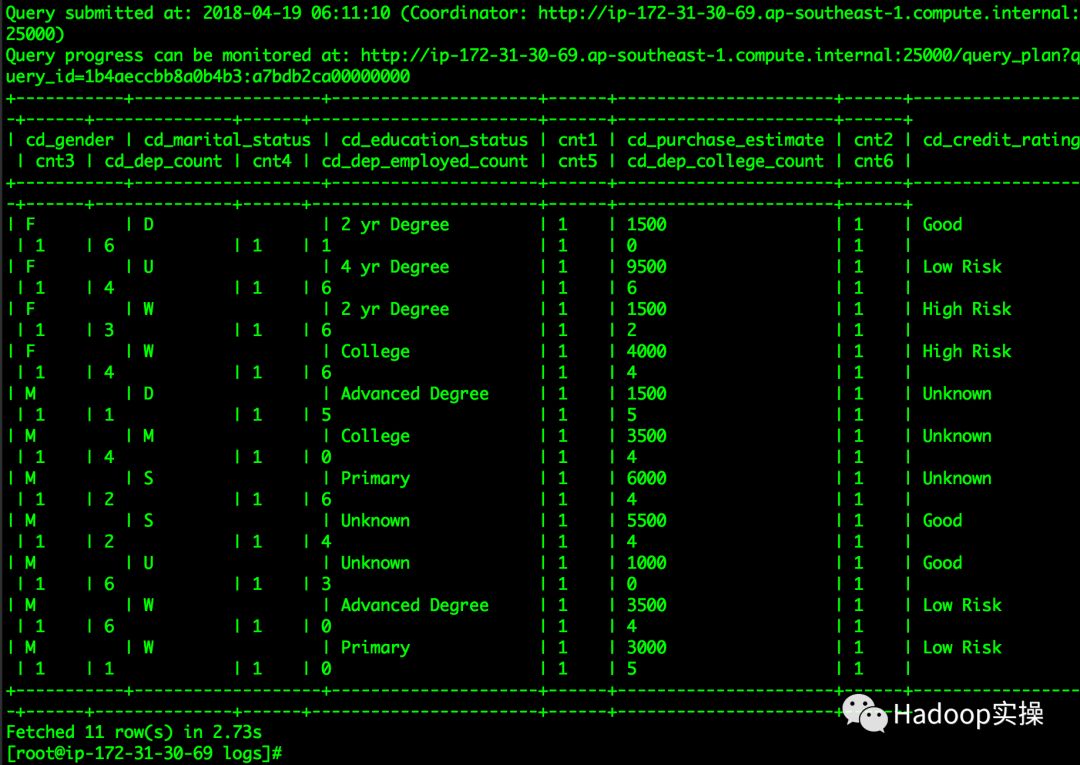
SQL执行结果
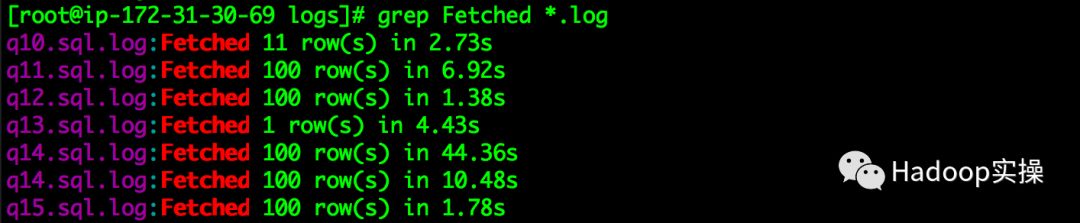
4.通过logs目录下的log文件可以查看每条SQL的执行结果和执行时间
5.总结
Fayson这里只是介绍了如何进行TPC-DS来实现Impala的基准测试,以2GB的测试数据为例来说明。
https://github.com/fayson/cdhproject/tree/master/impala-tpcds
目录结构说明
init.sh脚本用于初始化impala基准测试表、数据及统计分析。
run_all_queries.sh脚本用于执行99条SQL并输出日志目录
logs目录主要存放执行的SQL结果
ddl-tpcds目录创建Impala基准测试表的SQL文件。
queries目录存放了99条基准测试的SQL。
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于Impala TPC-DS基准测试的主要内容,如果未能解决你的问题,请参考以下文章