Impala原理探索
Posted xingoo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Impala原理探索相关的知识,希望对你有一定的参考价值。
导读
Cloudera Imapala是一款开源的MPP架构的SQL查询引擎,它提供在hadoop环境上的低延迟、高并发的BI/数据分析。本篇源自于Impala的设计论文,主要从使用的角度描述Impala的架构设计与主要组件以及一些重要特性,尤其是statestore和catalog的设计原理。
1 介绍
Impala是一款开源、与Hadoop高度集成,灵活可扩展的查询分析引擎,目标是基于SQL提供高并发的即席查询。第一版是在2012年10月开放的,目前还有很多公司在使用它作为核心查询引擎,比如神策。几年前公司想要做用户行为分析的产品,对标的就是神策的那套架构。
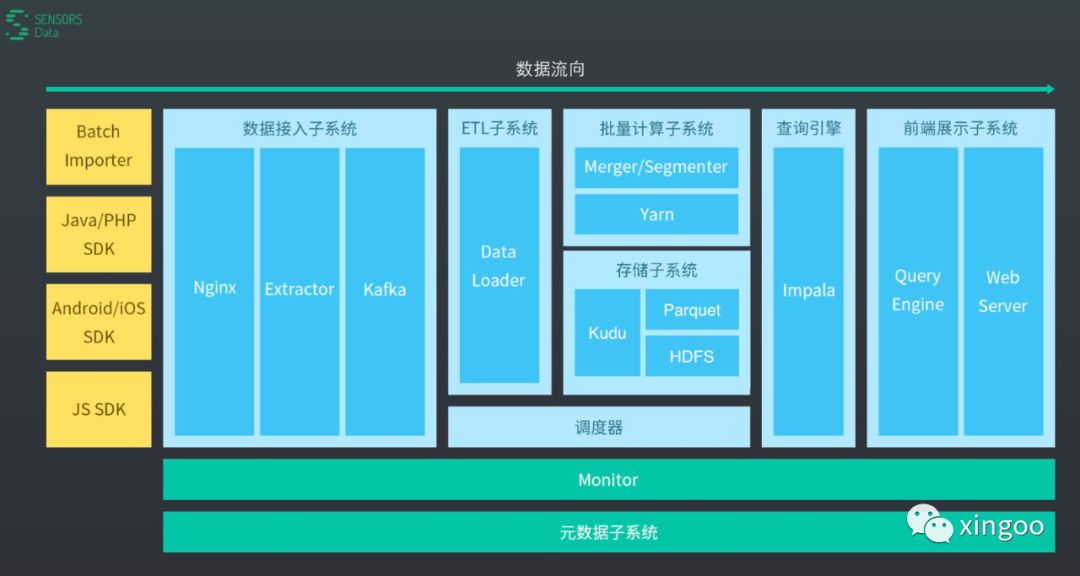
神策就是基于Impala作为核心的查询引擎,后面对接Kudu、hdfs实现Lambda架构的实时分析。不过现在Lambda不再那么流行,Flink感觉要一统江湖,所以这套架构现在看来不是那么先进了。
再说回Impala,跟其他的查询引擎系统(如presto、spark sql、hive sql)不同,Impala基于C++和Java编写,支持Hadoop生态下的多种组件集成(如HDFS、HBase、Metastore、YARN、Sentry等),支持多种文件格式的读写(如Parqeut、Avro、RCFile等)。关于Impala为什么会查询那么快,跟其他的查询引擎有什么区别,后面会另开一篇来说。
2 从使用的视角说
在平时的使用当中,Impala能跟很多Hadoop的组件集成,实现类似数据库查询的功能,但是底层其实还是有很大区别的。也可以通过create table来创建一个表的逻辑结构,并配置对应的存储的文件格式、hdfs存储的目录等。
2.1 关于物理视图
当创建一个表时,可以通过hive的标准语法创建,并指定分区列:
create table t() paritioned by (day int, month in)localtion xxx stored as parquet;
如果是未分区的表,那么就直接存储在默认的hdfs路径下。
对于分区表,文件存储在分区值对应的子目录下。注意分区后的数据并不一定存储在一台机器,他们底层都是由Block组成,存储在多个节点上。对于底层存储的格式也非常灵活,甚至不同的分区可以设置不同的文件格式。一个典型的应用场景就是点击流的数据存储:当天的数据用csv,历史数据用parquet 这样就完成了一套最简单的Lambda架构。
2.2 关于SQL
impala支持大部分Sql92的预发,以及sql2003的分析方法;支持丰富的类型,如string,char,varchar,timestamp,38精度的decimal等;也支持基于java和c++的udf,但是udaf只支持c++。
由于hdfs存储上的限制,Impala不支持update或者delete,但是支持基于insert into ... select...这种语法,在HBase中则是Insert into ... values ... 更为高效。不像传统的数据库,impala支持用户直接使用Hdfs命令拷贝数据文件到对应的目录下,也可以使用Load data这种语法。也支持直接删除某个分区alter table drop partition。
由于数据其实是存储在hdfs上的,因此在Impala不支持对某一部分进行更新,一般可以通过读取某个分区到内存后删除该分区,再重新创建新的分区来实现更新的效果(先删后插)。一般来说,如果有比较大的底层数据变化,最好执行一下compute stats语法,这样可以在后面的查询优化中起到很关键的作用。
3 架构设计
impala是标准的mpp架构,massively-parallel query execution engine,支持在上百台机器的Hadoop集群上执行快速查询。他对底层的存储系统解耦,不像数据库要求那么严格,不同的底层存储都可以联合查询。
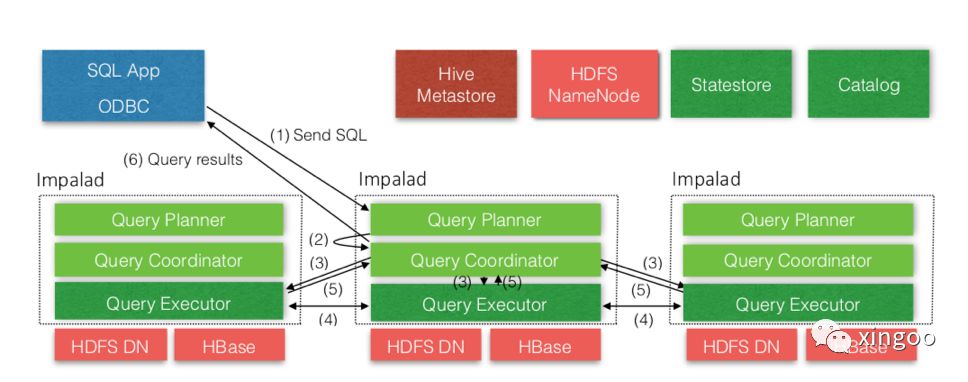
上图是impala整体的架构图,可以简单的把impala集群看成三种角色服务。
impalad用于接收查询请求并分解成查询任务、组织并完成集群中的数据查询、汇总完成数据的整合关联。如果Impala用于调度查询请求的时候,一般会把它称为调度者(Coordinator)。在Impala中Impalad是对等的,也就是说每个进程内部的角色都一样,都可以作为调度者接收请求,这样即有助于容错,又可以做到负载均衡。一般每个数据节点都要安装一个imapald进程,这样impala可以查询本机的数据,实现数据本地性,减少网络IO。
statestored进程用于维护特定消息的发布订阅服务,用于在集群中广播一些消息。这个服务是单点的。
最后是catalogd,它主要负责维护元数据的读取查询。当执行DDL操作时,会同步到catalog,然后通过statestore广播给其他的节点。
3.1 分布式状态
在MPP架构中一个比较大的挑战就是如何在上百个节点中进行协同工作,同步集群的元数据,impala是一种p2p的架构设计,即没有主从的概念,每个节点都可以接收或者执行查询请求,因此所有的节点需要及时同步更新最新的元数据信息以及节点状态。
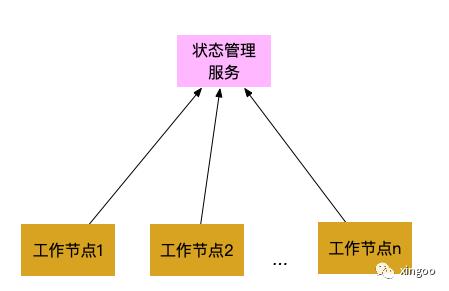
一种解决的思路是部署一个单独的集群管理服务,每个节点跟这个服务连接,通过这个服务了解集群的状态。但是这种通信方式势必会造成大量的rpc调用,如果使用TCP来实现,网络负载会比较高。
因此impala基于发布订阅模式,实现了集群状态的管理(这就是statestore)。
可以看一下impala的statestore ui中:
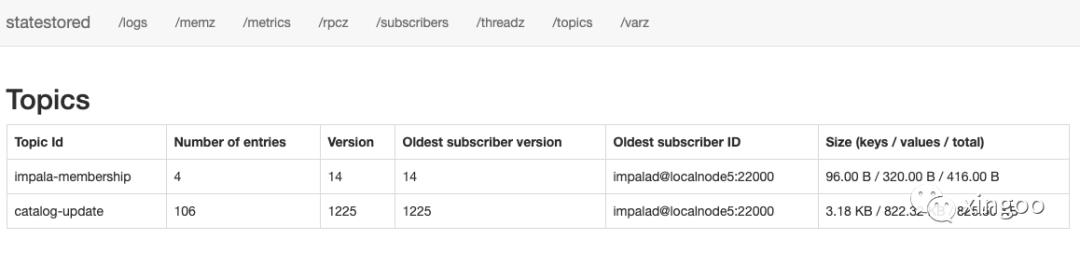
看图可知,当前statestore中有两个主题(其中impala-membership维护了节点状态,catalog-update则维护了catalog中元数据变化)。
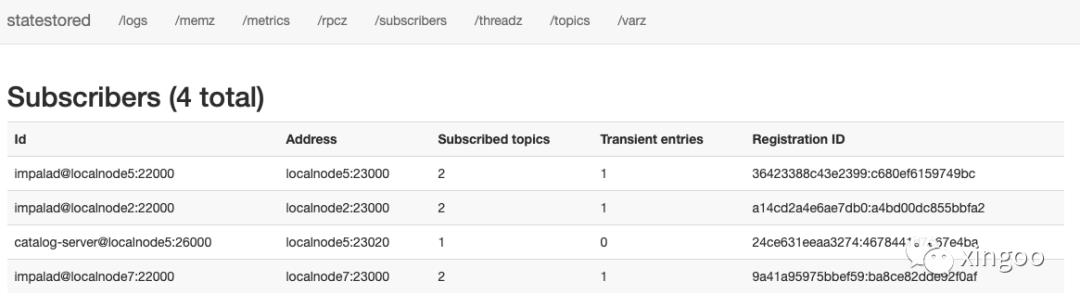
订阅者可以看到有三个Impalad和一个catalog,当数据有变化时,每个订阅者会获取对应的变更信息同步到对应的节点。
因此,statestore其实就是一个发布订阅服务而已,内部维护了一个主题列表,列表中的信息包含三个主要的字段:<key,value,version>,statestore其实不需要关心内部的数据到底是什么样的,topic信息也只存在于statestore中生命周期内,一旦服务重启数据就会丢失。其中订阅者就是对某个主题感兴趣的服务。
注册完成后,statestore会周期性的向订阅者发送两个消息,update和keepalive。
其中update有新增、修改、删除的topic。每个订阅者都维护了一个最新版本的标识,只会订阅对应版本的消息。在消息更新的返回内容里面,还会加上这个节点希望同步给其他节点的内容。这些内容会在下一次发送更新消息的时候进行更新。
第二种就是keepalive消息,用于保证订阅者之间的连接正常,从而了解哪些订阅者超时下线。之前版本的statestore只用一种消息实现这两个功能,但是有的时候一些元数据变化可能返回很慢,结果statestore会误认为连接超时,因此后来就变成两个独立的消息类型了。
如果statestore发现有订阅者超时失败,就会停止发送更新消息。一些主题内容也会标记为'transient',如果对应的消费者失败,他们会被删除掉。这里我的理解就是,如果有某个更新消息,对应的订阅者订阅消费完成,那么就清理掉;如果订阅失败,则标记为trasient,后面可能还会尝试消费;如果订阅者直接掉线或者宕机,那么这个消息直接删除就可以了。
statestore其实只能提供比较弱的同步机制,因为订阅者消费这些数据(更新元数据)的频率是不一样的,有的机器性能好进行元数据变更就会快,因此同一时间可能看到的数据还是不同的。不过由于Impala只是在本地使用这些信息,并不会通过它来做分布式的一些协调,因此不会有什么影响。比如正常一个Impalad进程接收到请求后,会根据本地的元数据进行sql任务的拆分,然后把计算传给其他的节点;其他节点会使用自己本地的元数据进行下一步的查询。
尽管statestore是单点的,但是仍然能支持中型甚至大型的集群。因为它内部维护的消息既不存储在磁盘中,同时还只发送给存活的节点,因此内部的消息不会很多。所以当statestore重启时,它的状态可以在注册的时候再次同步(这里不太理解,个人理解应该是当statestore重启后,会重新拉取一波元数据并打上新的版本,从而订阅者会重新消费更新本地的数据)。如果整个statestore所在的机器挂掉,那就只能在另一个节点上启动这个服务了。此时订阅者可能会订阅失败,一般使用个DNS服务重定向一下就行。
3.2 catalog服务
catalog通过statestore广播元数据的变更或者DDL操作。catalog服务也会从第三方元数据存储比如metastore拉取元数据,把他们转成impala自己的结构。这种架构就使得impala可以比较灵活的处理不同的组件,比如hbase。同时也让impala很方便的扩展自定义函数,即把函数信息发送到catalog中,其他的节点就能知道该函数。
由于catalog可能会很大,因此服务启动的时候只会加载一些通用信息,等到真正使用的时候才会加在详细信息。当一个请求发现某个表的元数据信息还不够时,就会以阻塞的形式先去加载元数据,然后回头再来执行查询。
4 总结
这次主要是针对整体的架构,介绍statestore和catalog的设计理念与实现机制,内容都是通过阅读设计论文理解而来。想要研究具体的实现过程,还需要阅读相关的源码才行。粗略的翻看了下源码,可以总结点经验:
主要的代码都在be中,如catalog、statelog、impalad等,fe中则是java的一些实现,如预发解析树啊、接口调用啊等等。粗略的扫了下HBase查询,应该是通过Java进行语法解析,然后通过C++转成thrift请求,直接查询HRegionServer。
论文中还有一部分很重要的内容,就是Impala本身的一些优化技术手段,由于篇幅过长,改天再整理成文。
往期推荐:
xingoo
专注大数据与机器学习
以上是关于Impala原理探索的主要内容,如果未能解决你的问题,请参考以下文章