《Impala实战》—— 读后总结
Posted xingoo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Impala实战》—— 读后总结相关的知识,希望对你有一定的参考价值。
导读
关于Impala书籍很少,也能看出这项技术的流行程度一般般 。但是出于HBase查询方便的角度,还是硬着头皮看看这本过时很久的书籍。好在Impala更新的不是很多,所以还具有一定的参考价值。书籍内容大多来自官方文档,推荐指数只能给2星:★★☆☆☆
。但是出于HBase查询方便的角度,还是硬着头皮看看这本过时很久的书籍。好在Impala更新的不是很多,所以还具有一定的参考价值。书籍内容大多来自官方文档,推荐指数只能给2星:★★☆☆☆
1 背景
Impala是Cloudera开源的实时查询项目,目标是基于统一的SQL快速查询各种存储系统,如HDFS、Kudu、HBase等。Impala原意为高角羚,该项目的特点就是快速。Impala舍弃MapReduce,基于C++实现针对硬件做了很多的优化,支持数据本地性。

2 组件角色
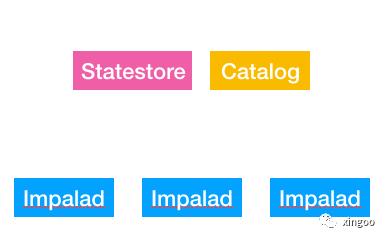
在Impala中有三种角色的组件:
Impalad:Impala的核心组件,用于sql的解析、任务分发、执行。
Statestore:检测节点是否故障,如果有故障,那么impalad在分发任务时会忽略该节点。
Catalog:同步元数据变化,正常每个impalad都缓存一份hive元数据,当数据变更时,通过该服务同步给所有的Imaplad。
读写时,每个Impalad都可以作为接收者。详细的流程如下:
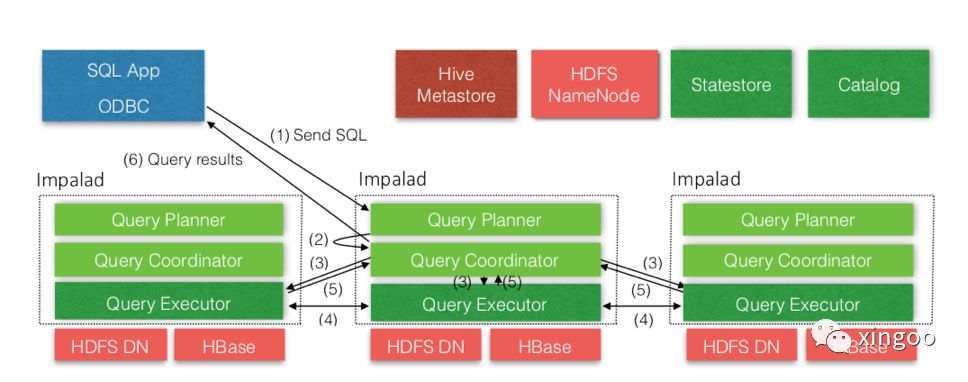
通过jdbc等驱动发送查询sql
imaplad接收到请求,解析sql,生成查询计划
impalad变成coordinator角色,分发查询计划到各个impalad节点
impalad接收其他的coordinator发过来的查询请求,执行本地查询
impalad执行本地扫描,然后把结果返回给coordinator
coordinator汇总结果,返回给client客户端
3 安装部署
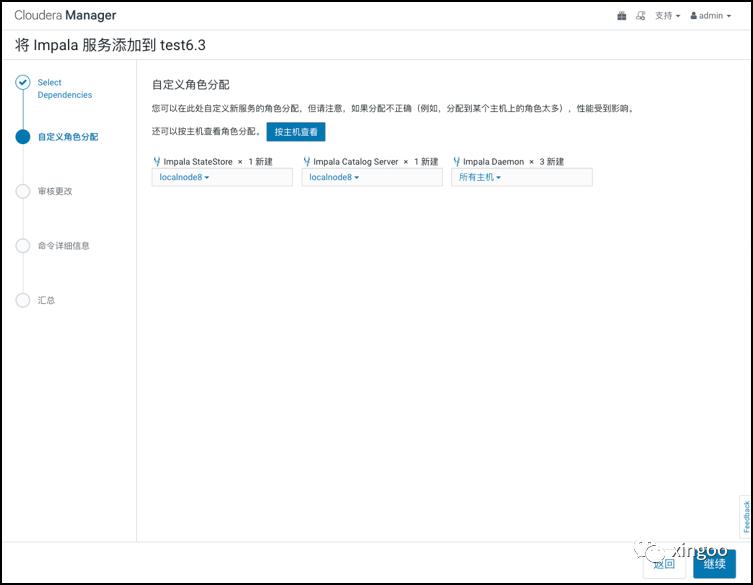
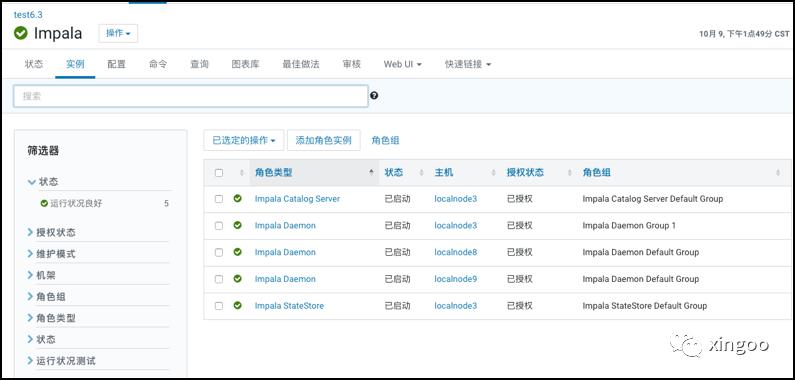
在CM中安装Impala非常简单,添加服务后,选中对应的角色主机即可。如果只想查询HBase,那么每台RegionServer的主机上部署一个Impalad即可。statestore和catalog可以部署在另一个节点上。
4 使用优化
Impala的使用跟Hive其实没什么两样,都是标准的sql语法,就不再啰嗦了。可以再总结下相关的优化经验:
4.1 查询的时候一定要尽可能减少返回的数据量,可以设置limit大小
4.2 如果查询HBase一定要充分利用HBase的rowkey,缩小扫描范围
4.3 可以使用explain命令分析查询计划
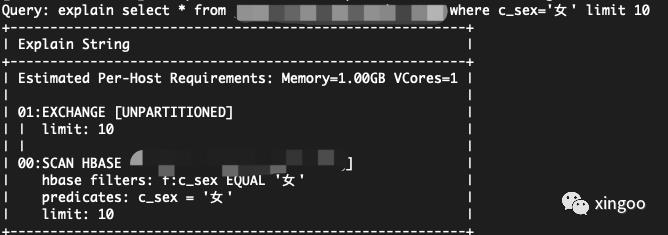
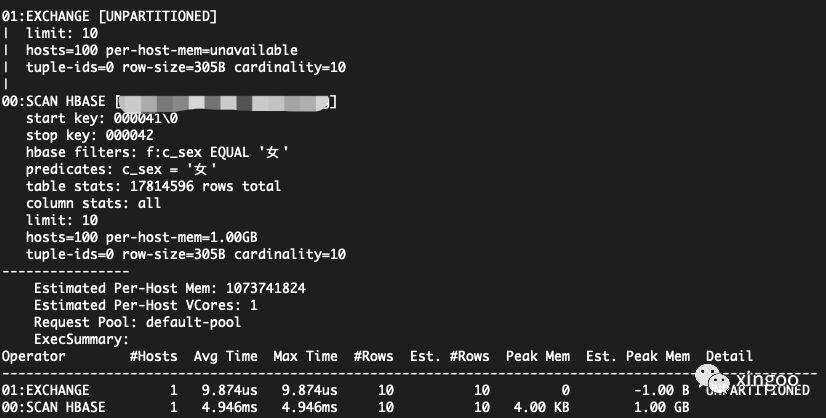
4.4 可以使用profile命令分析上一个sql的耗时情况
比如下面的场景,就可以观察到scan的耗时
4.5 通过CM的静态服务资源池限制Impala的资源使用,避免干扰其他组件
5 参考资料
5.1 官方文档
https://www.cloudera.com/documentation/enterprise/5-7-x/topics/impala_tutorial.html
5.2 唯一的一本书,其实就是翻译的官方文档:
https://item.jd.com/1470868681.html
5.3 原理论文
http://cidrdb.org/cidr2015/Papers/CIDR15_Paper28.pdf
往期相关推荐:
1
2
xingoo
专注大数据与机器学习
以上是关于《Impala实战》—— 读后总结的主要内容,如果未能解决你的问题,请参考以下文章