Impala并发查询缓慢问题解决方案
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Impala并发查询缓慢问题解决方案相关的知识,希望对你有一定的参考价值。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
Fayson的github:
https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1.文档编写目的
在前面的文章中,我们介绍了《》,如果Parquet表是由Hive/Spark产生的,包含TIMESTAMP字段类型,并且Impala高级配置包含
--convert_legacy_hive_parquet_utc_timestamps=true
启用选项,那么使用Impala做并发查询时,随着并发的增加,查询性能会慢慢下降,并发越高,性能下降越厉害。
本文将模拟假设你的环境已经出现了这个问题,即所有的带timestamp的parquet表已经由Hive生成了,这里提供三种改造方案,并基于三种改造方案进行测试验证,最后给出方案的比较和总结。
内容概述:
1.解决方案建议
2.解决方案验证
3.解决方案比较和总结
4.附录
测试环境:
1.CM和CDH版本为5.13.1
2.操作系统版本为Redhat7.2
3.Impala已配置负载均衡
4.采用root用户进行操作
2.解决方案建议
2.1.问题解决思路
之前提到过,必须同时具备下列三个条件才会影响Impala并发查询,那么只要使下列三个条件任意一个不成立,即可解决由于 Linux 本地的时间转换函数(localtime_r)给进程加上全局锁导致Impala并发查询性能差的问题。
1.Parquet 表包含 TIMESTAMP 字段;
2.Parquet 文件由 Hive 或者 Spark 生成;
3.Impala Daemon命令行参数高级配置代码段(安全阀)包含以下配置:
--convert_legacy_hive_parquet_utc_timestamps=true
2.2.解决方案建议
基于上述的问题解决思路,可提出三种问题解决方案,详细内容如下:
1.将所有TIMESTAMP改为STRING类型,这个选项对业务系统的影响是最大的,相当于客户前端的ETL程序,Hive/Spark的所有程序都要改写,包括以后业务用户通过Impala使用这些表的方式也需要修改。但是管理和维护成本是最低的,一次改造之后,无须再考对业务系统进行修改。
2.将由Hive/Spark生成的所有涉及TIMESTAMP的Parquet表/分区的数据全部由Impala再次生成一下,该方法的好处是不影响已有的业务系统,坏处是需要占用集群的额外资源,选取合适的时间来做这个转换,还需要考虑每日的增量处理的方式等。
3.在受影响的表之上再构建一个视图,该视图的TIMESTAMP带上UTC和CST时区的offset。该方法的好处是不用对已有的作业造成影响,相较第二点,也不用占用集群的额外资源来重新生成数据表,但是对于业务和开发用户来说使用方式可能要变化,另外就是多了很多视图,造成更多的管理成本。
注:红色字体内容是方案的坏处,绿色字体内容是方案的好处。
3.解决方案验证
3.1.Timestamp转String类型
3.1.1.前置条件
1.Impala配置参数:
--convert_legacy_hive_parquet_utc_timestamps=true
2.将包含时间戳的字段“statsdate”类型更改为STRING后,用Hive生成Parquet表
3.1.2.测试准备
1.生成Parquet表语句如下:
[root@cdh4 scripts]# cat string_type.sql
ues iot_test;
create table hive_table_parquet2 (
ordercoldaily BIGINT,
smsusedflow BIGINT,
gprsusedflow BIGINT,
statsdate STRING,
custid STRING,
groupbelong STRING,
provinceid STRING,
apn STRING )
PARTITIONED BY ( subdir STRING )
STORED AS PARQUET;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table hive_table_parquet2 partition (subdir) select * from hive_table_test
(可左右滑动)
执行./hivesql_exec.sh string_type.sql命令,生成Parquet表
2.在beeline中查看数据总数
执行select count(*) from hive_table_parquet2;命令
3.测试SQL语句如下
[root@cdh4 scripts]# cat b.sql
use iot_test;
SELECT
nvl(A.TOTALGPRSUSEDFLOW,0) as TOTALGPRSUSEDFLOW, nvl(A.TOTALSMSUSEDFLOW,0) as TOTALSMSUSEDFLOW, B.USEDDATE AS USEDDATE
FROM ( SELECT SUM(GPRSUSEDFLOW) AS TOTALGPRSUSEDFLOW, SUM(SMSUSEDFLOW) AS TOTALSMSUSEDFLOW, cast(STATSDATE as timestamp) AS USEDDATE
FROM hive_table_parquet2 SIMFLOW
WHERE SIMFLOW.subdir = '10' AND SIMFLOW.CUSTID = '10099'
AND cast(SIMFLOW.STATSDATE as timestamp) >= to_date(date_sub(current_timestamp(),7))
AND cast(SIMFLOW.STATSDATE as timestamp) < to_date(current_timestamp())
GROUP BY STATSDATE ) A
RIGHT JOIN (
SELECT to_date(date_sub(current_timestamp(),7)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),1)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),2)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),3)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),4)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),5)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),6)) AS USEDDATE
) B on to_date(A.USEDDATE) = to_date(B.USEDDATE) ORDER BY B.USEDDATE
(可左右滑动)
3.1.3.并发测试
1.测试1个并发查询
第一次测试:0.67秒返回查询结果
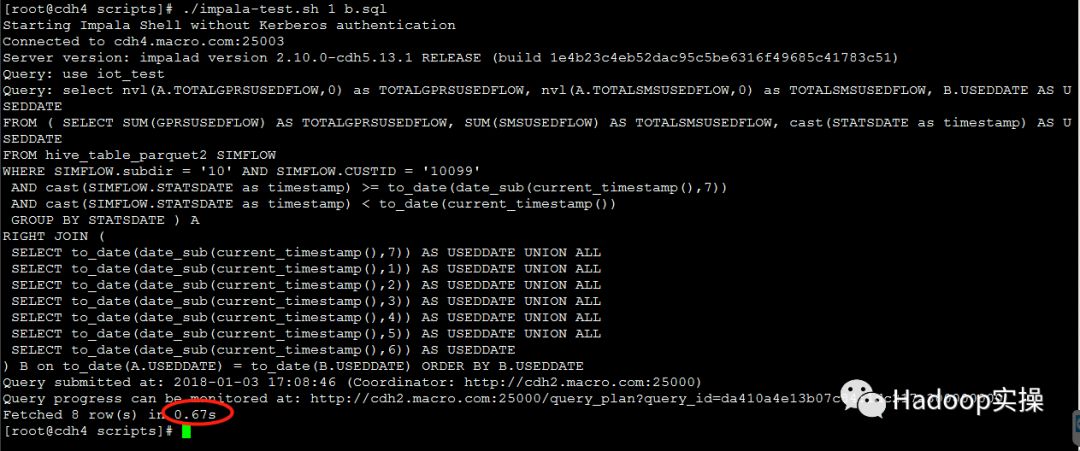
第二次测试:0.67秒返回查询结果
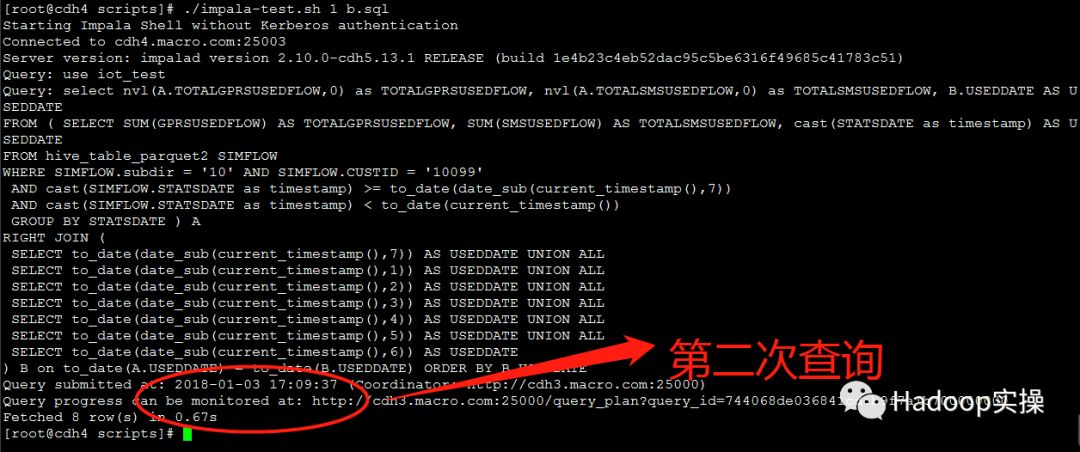
第三次测试:0.66秒返回查询结果
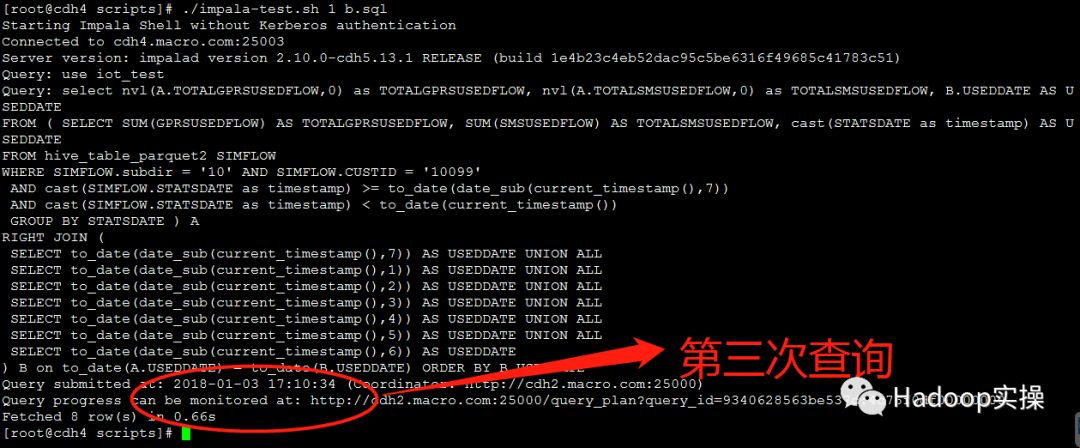
2.测试10个并发查询
第一次测试:所有并发查询均在1.5秒内完成
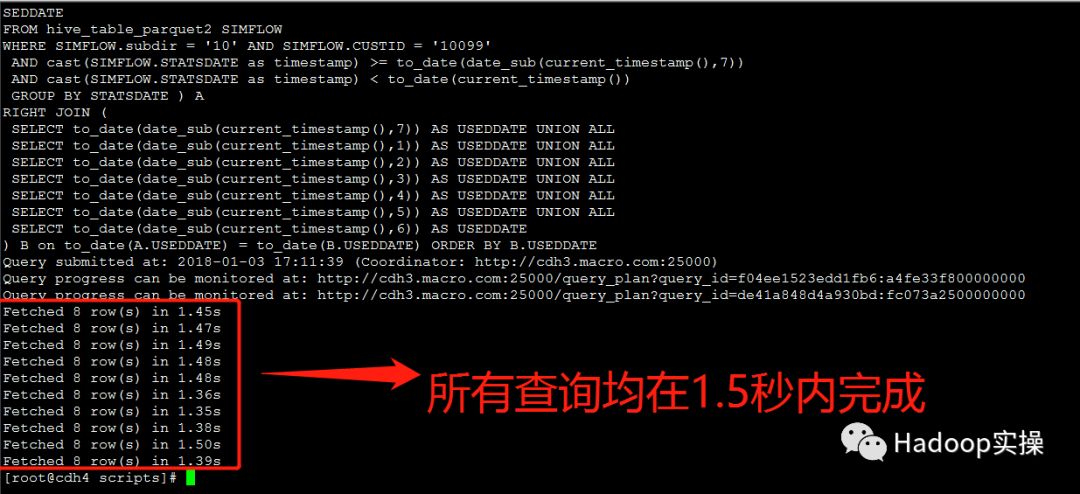
第二次测试:所有并发查询均在1.6秒内完成
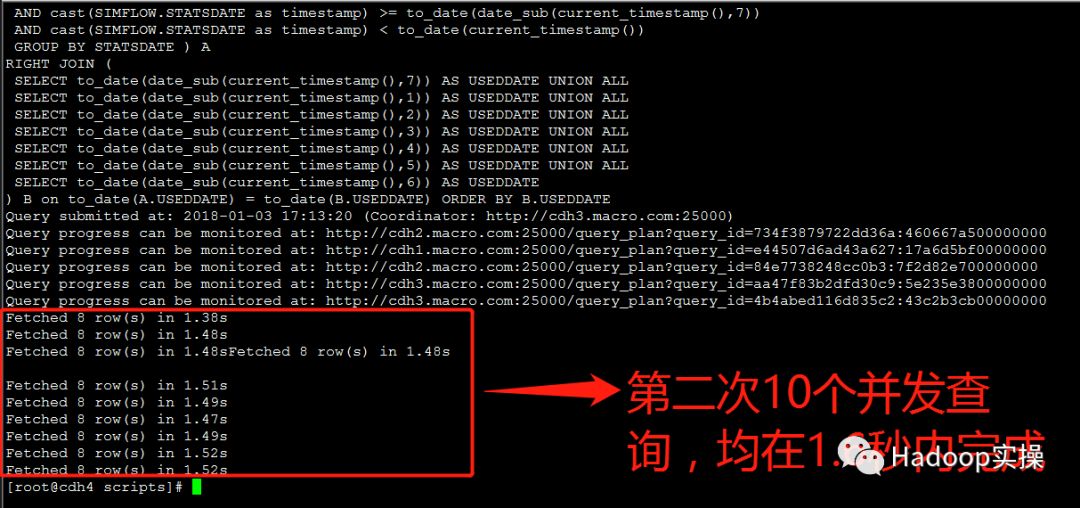
第三次测试:所有并发查询均在1.6秒内完成
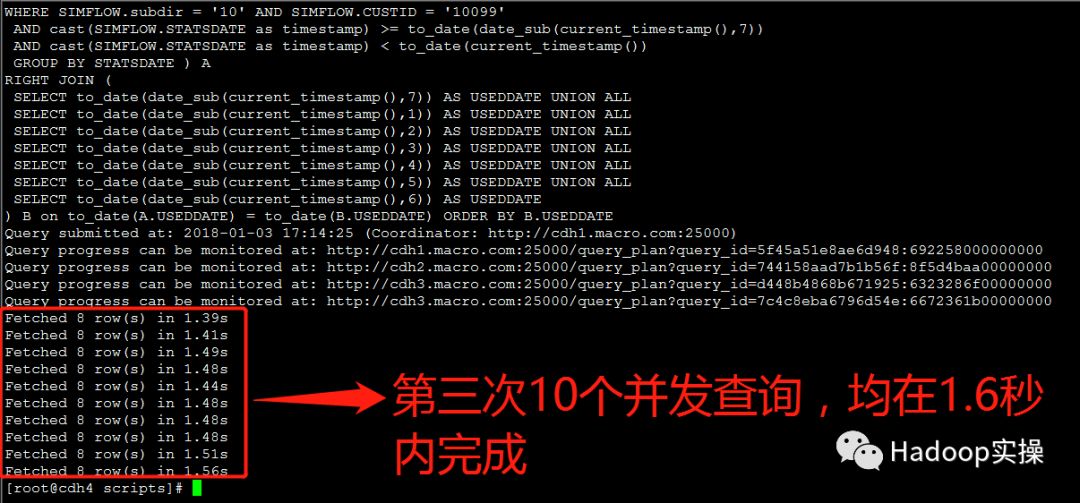
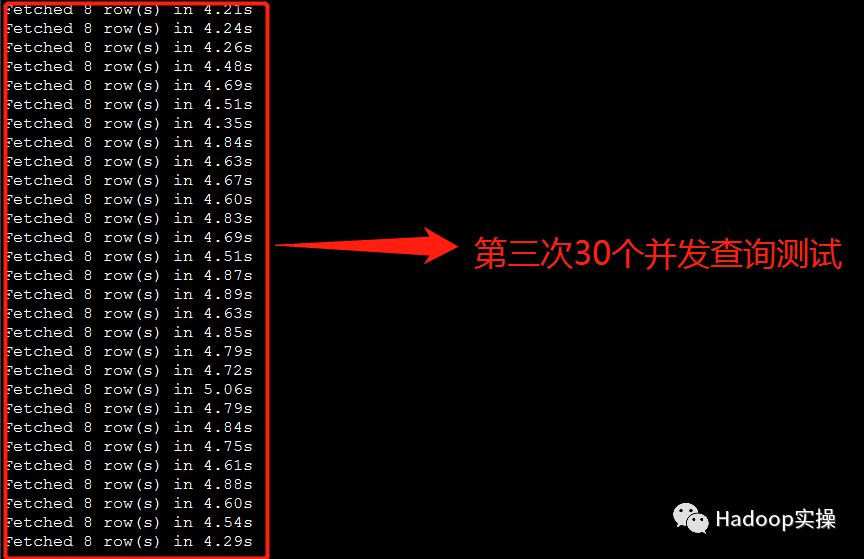
3.测试30个并发查询:
第一次测试:所有并发查询均在5秒内完成
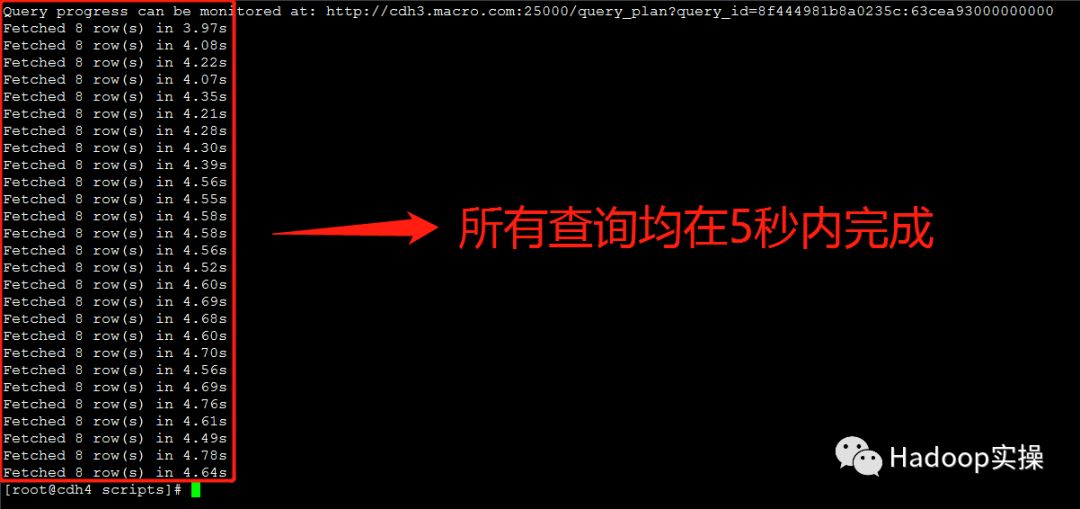
第二次测试:所有并发查询均在5秒内完成
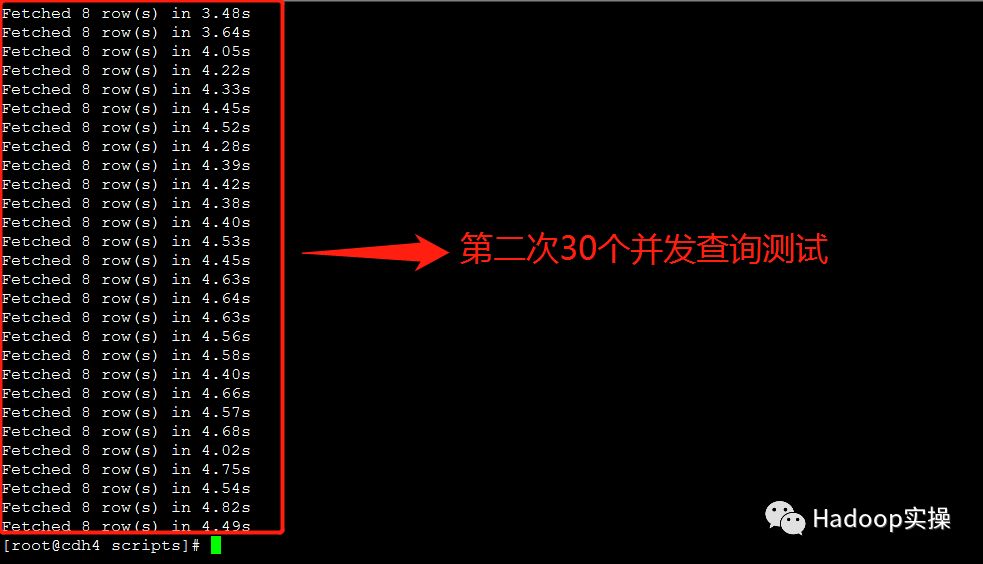
第三次测试:所有并发查询均在5秒内完成
3.2.Impala重新生成Parquet文件
3.2.1.前置条件
Impala配置参数:
--convert_legacy_hive_parquet_utc_timestamps=true
3.2.2.测试准备
1.使用Impala创建Parquet表
建表脚本如下:
[root@cdh4 scripts]# cat impalasql_exec.sh
impala-shell -B -i cdh4.macro.com:25003 -u hive -f $1 &
(可左右滑动)
生成Parquet表语句如下:
[root@cdh4 scripts]# cat timestamp_type.sql
use iot_test;
create table if not exists impala_table_parquet (
ordercoldaily BIGINT,
smsusedflow BIGINT,
gprsusedflow BIGINT,
statsdate TIMESTAMP,
custid STRING,
groupbelong STRING,
provinceid STRING,
apn STRING )
PARTITIONED BY ( subdir STRING )
STORED AS PARQUET;
insert overwrite table impala_table_parquet partition (subdir) select * from hive_table_parquet
(可左右滑动)
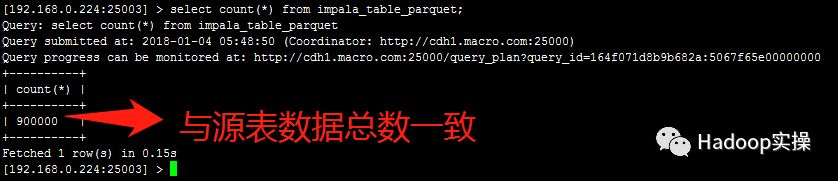
2.在impala中查看数据总数
执行select count(*) from impala_table_parquet;命令
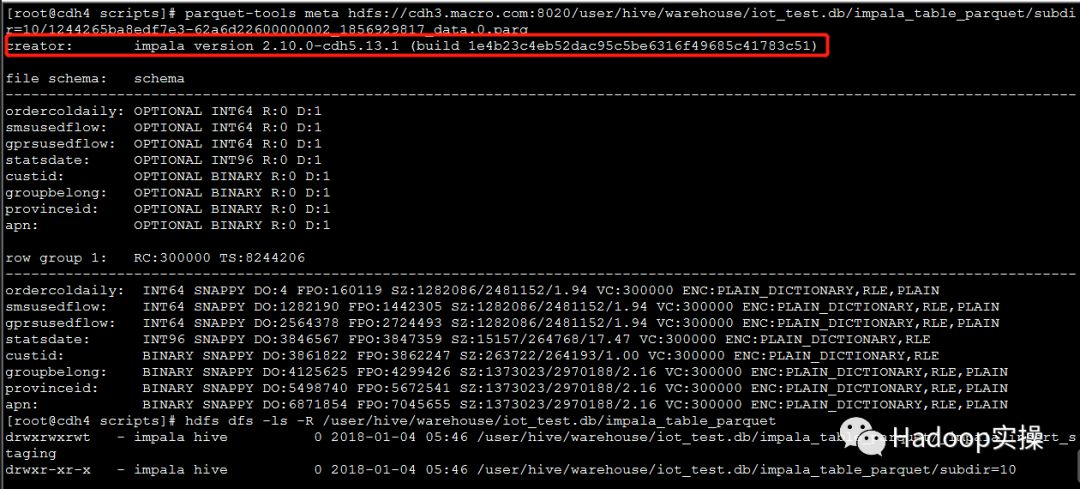
3.验证Parquet文件是否由Impala生成
root@cdh4 scripts]# hdfs dfs -ls -R /user/hive/warehouse/iot_test.db/impala_table_parquet
(可左右滑动)

[root@cdh4 scripts]# parquet-tools meta hdfs://cdh3.macro.com:8020/user/hive/warehouse/iot_test.db/impala_table_parquet/subdir=10/1244265ba8edf7e3-62a6d22600000002_1856929817_data.0.parq
creator: impala version 2.10.0-cdh5.13.1 (build 1e4b23c4eb52dac95c5be6316f49685c41783c51)
(可左右滑动)
4.测试SQL语句如下
[root@cdh4 scripts]# cat c.sql
use iot_test;
SELECT
nvl(A.TOTALGPRSUSEDFLOW,0) as TOTALGPRSUSEDFLOW, nvl(A.TOTALSMSUSEDFLOW,0) as TOTALSMSUSEDFLOW, B.USEDDATE AS USEDDATE
FROM ( SELECT SUM(GPRSUSEDFLOW) AS TOTALGPRSUSEDFLOW, SUM(SMSUSEDFLOW) AS TOTALSMSUSEDFLOW, cast(STATSDATE as timestamp) AS USEDDATE
FROM impala_table_parquet SIMFLOW
WHERE SIMFLOW.subdir = '10' AND SIMFLOW.CUSTID = '10099'
AND cast(SIMFLOW.STATSDATE as timestamp) >= to_date(date_sub(current_timestamp(),7))
AND cast(SIMFLOW.STATSDATE as timestamp) < to_date(current_timestamp())
GROUP BY STATSDATE ) A
RIGHT JOIN (
SELECT to_date(date_sub(current_timestamp(),7)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),1)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),2)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),3)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),4)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),5)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),6)) AS USEDDATE
) B on to_date(A.USEDDATE) = to_date(B.USEDDATE) ORDER BY B.USEDDATE
(可左右滑动)
3.2.3.并发测试
1.测试1个并发查询
第一次测试:0.68秒返回查询结果
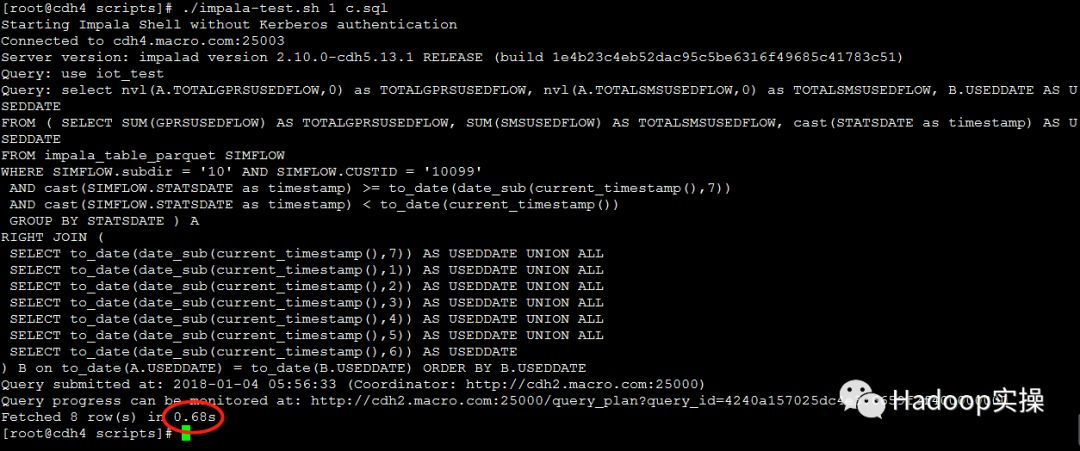
第二次测试:0.66秒返回查询结果
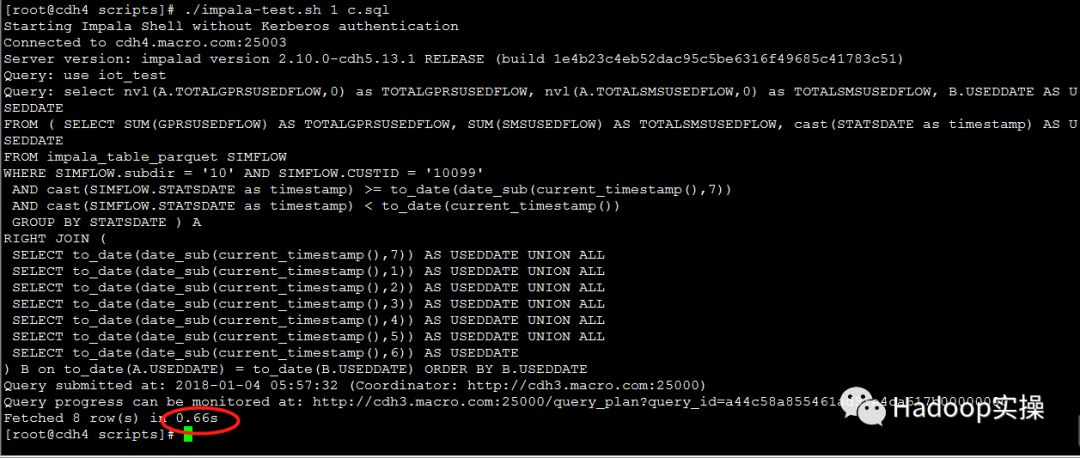
第三次测试:0.67秒返回查询结果
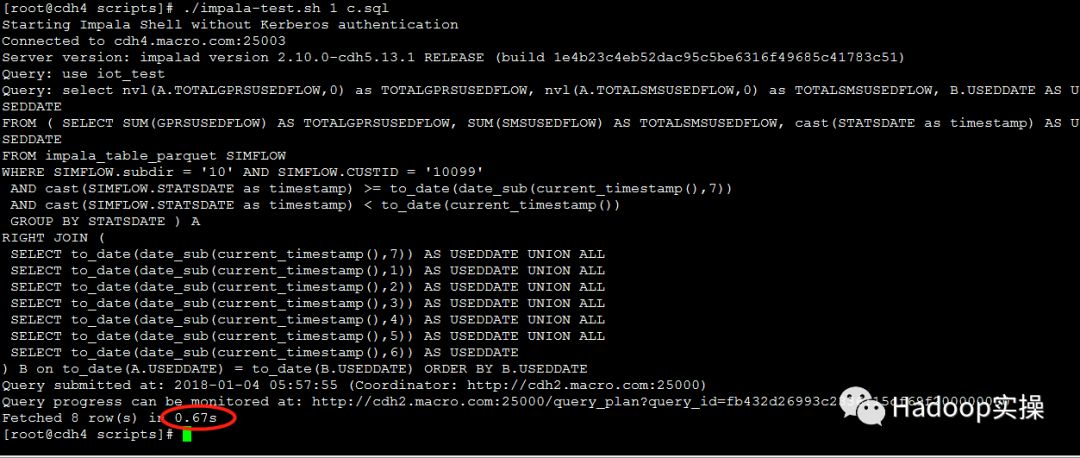
2.测试10个并发查询
第一次测试:所有并发查询均在1.5秒内完成
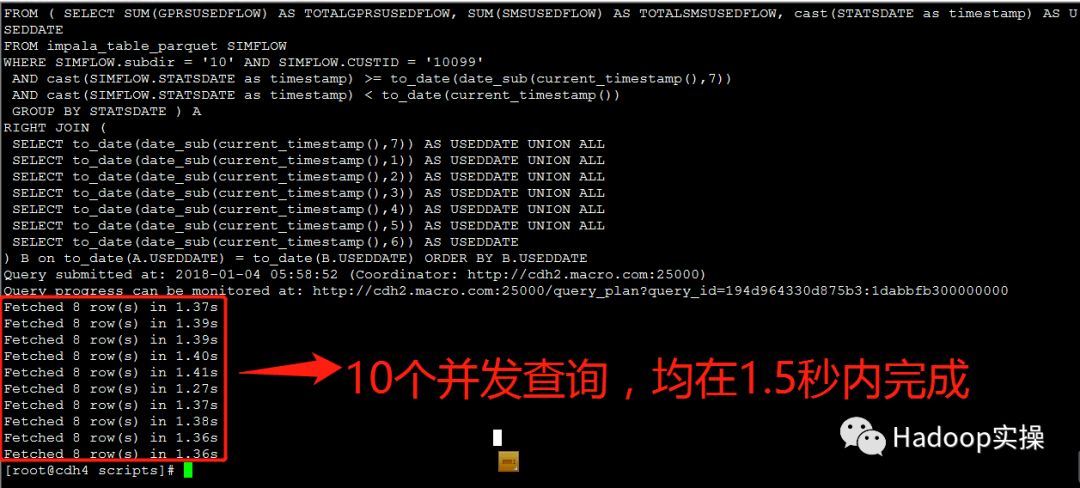
第二次测试:所有并发测试均在1.7秒内完成
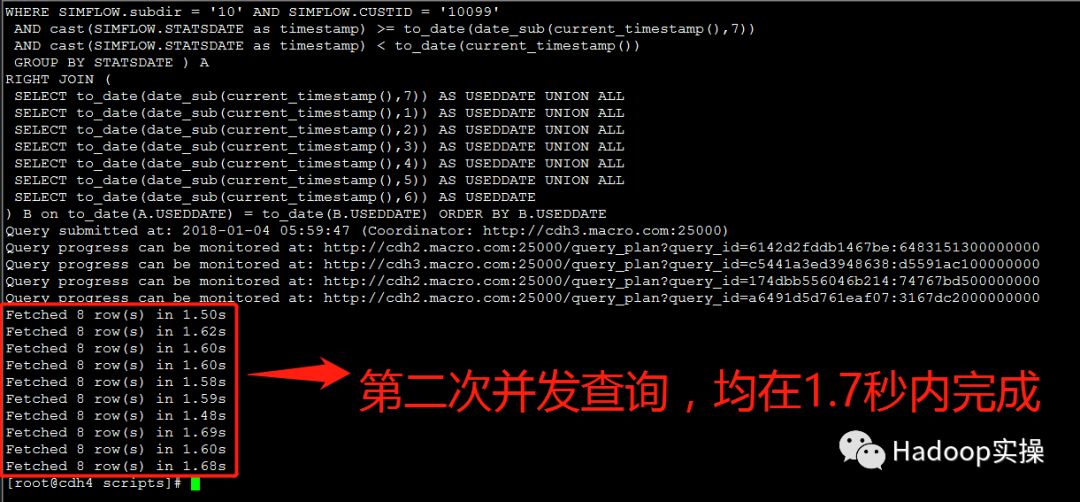
第三次测试:所有并发测试均在1.7秒内完成
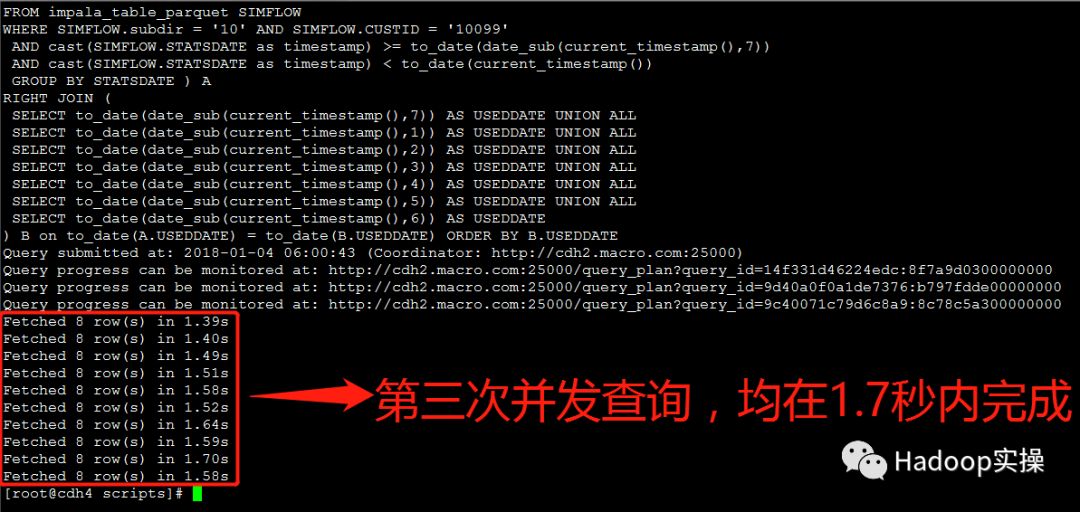
3.测试30个并发查询:
第一次测试:所有并发测试均在5秒内完成
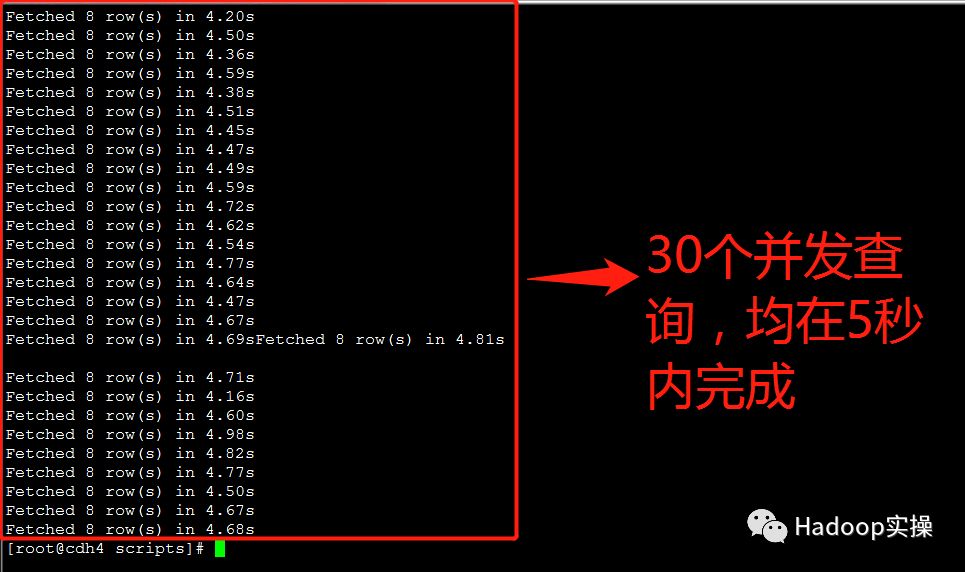
第二次测试:所有并发测试均在5秒内完成
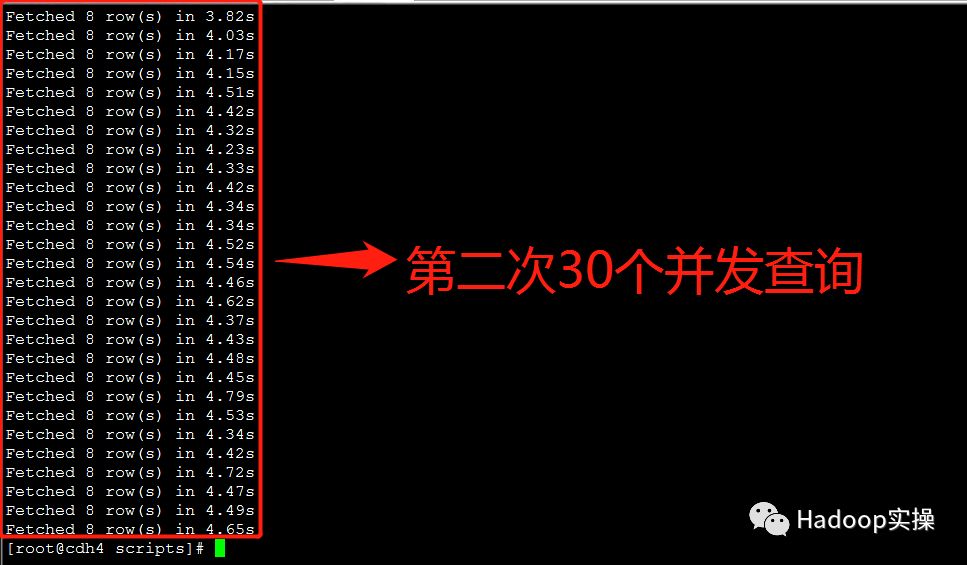
第三次测试:所有并发测试均在5秒内完成
3.3.构建Impala视图
3.3.1.前置条件
Impala配置参数:
--convert_legacy_hive_parquet_utc_timestamps=false
3.3.2.测试准备
1.修改Impala配置参数
Impala Daemon高级配置:删除
-convert_legacy_hive_parquet_utc_timestamps
,恢复默认。
重启Impala服务
2.使用Impala创建视图
建立视图SQL语句如下:
[root@cdh4 scripts]# cat view_type.sql
use iot_test;
CREATE VIEW IF NOT EXISTS impala_view AS SELECT ordercoldaily,smsusedflow,gprsusedflow,hours_add(statsdate,8) as statsdate,custid,groupbelong,provinceid,apn,subdir FROM hive_table_parquet;
(可左右滑动)

3.在impala中查看数据总数
执行select count(*) from impala_view;命令
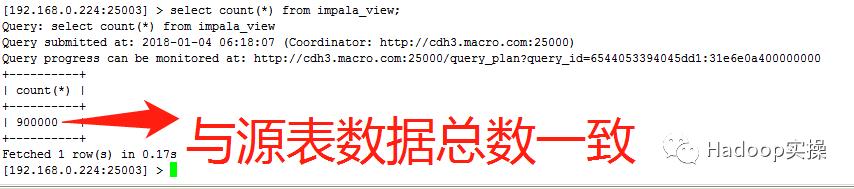
4.测试SQL语句如下
[root@cdh4 scripts]# cat d.sql
use iot_test;
SELECT
nvl(A.TOTALGPRSUSEDFLOW,0) as TOTALGPRSUSEDFLOW, nvl(A.TOTALSMSUSEDFLOW,0) as TOTALSMSUSEDFLOW, B.USEDDATE AS USEDDATE
FROM ( SELECT SUM(GPRSUSEDFLOW) AS TOTALGPRSUSEDFLOW, SUM(SMSUSEDFLOW) AS TOTALSMSUSEDFLOW, cast(STATSDATE as timestamp) AS USEDDATE
FROM impala_view SIMFLOW
WHERE SIMFLOW.subdir = '10' AND SIMFLOW.CUSTID = '10099'
AND cast(SIMFLOW.STATSDATE as timestamp) >= to_date(date_sub(current_timestamp(),7))
AND cast(SIMFLOW.STATSDATE as timestamp) < to_date(current_timestamp())
GROUP BY STATSDATE ) A
RIGHT JOIN (
SELECT to_date(date_sub(current_timestamp(),7)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),1)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),2)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),3)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),4)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),5)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),6)) AS USEDDATE
) B on to_date(A.USEDDATE) = to_date(B.USEDDATE) ORDER BY B.USEDDATE
(可左右滑动)
3.3.3.并发测试
1.测试1个并发查询
第一次测试:0.72秒返回查询结果
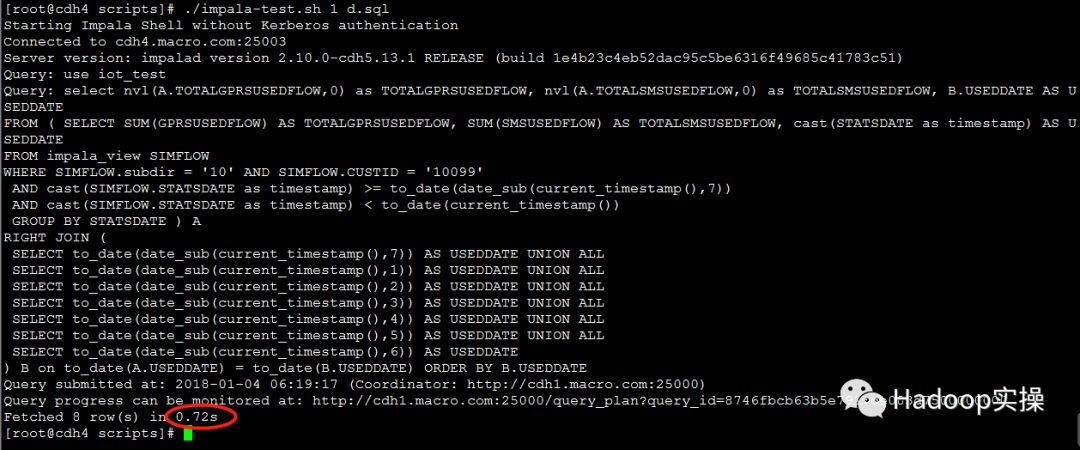
第二次测试:0.49秒返回查询结果
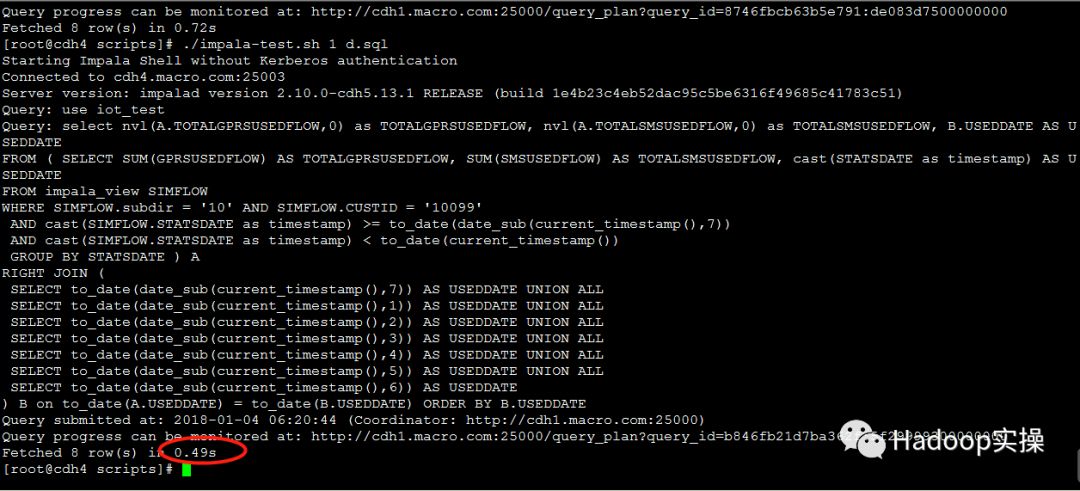
第三次测试:0.48秒返回查询结果
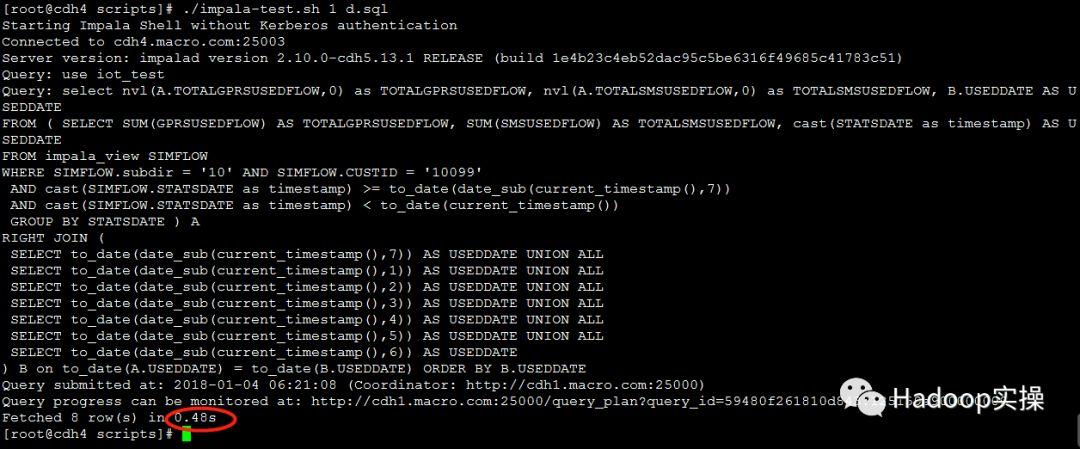
2.测试10个并发查询:
第一次测试:所有并发查询均在1.3秒内完成
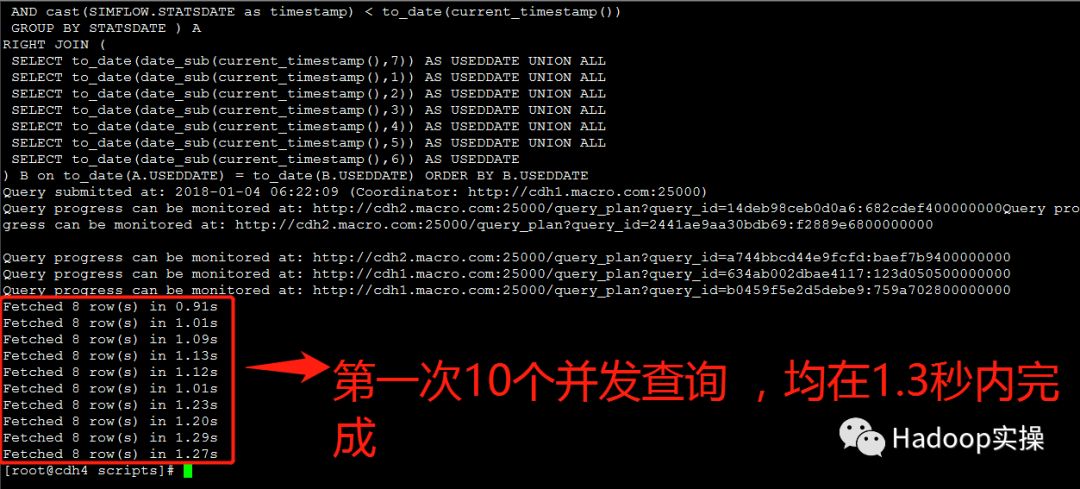
第二次测试:所有并发查询均在1.4秒内完成
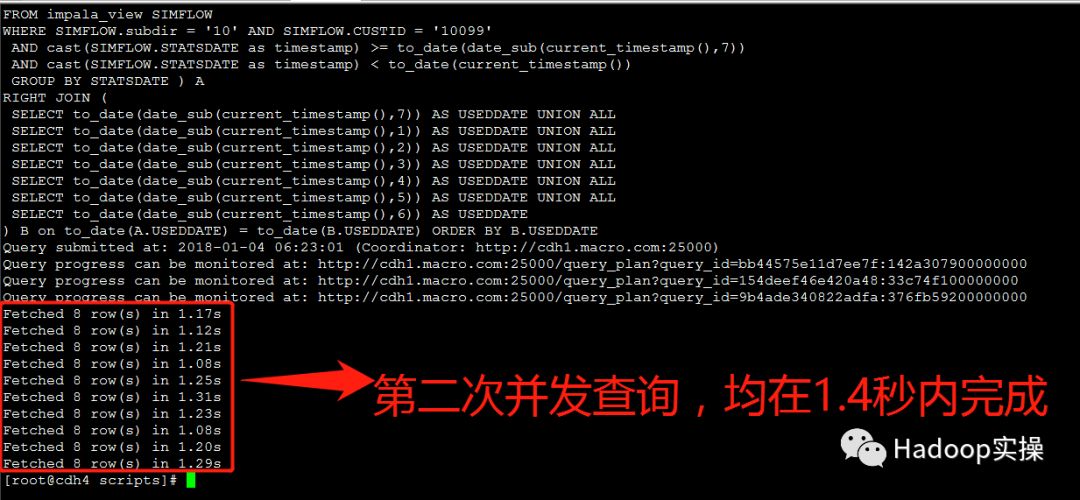
第三次测试:所有并发查询均在1.4秒内完成
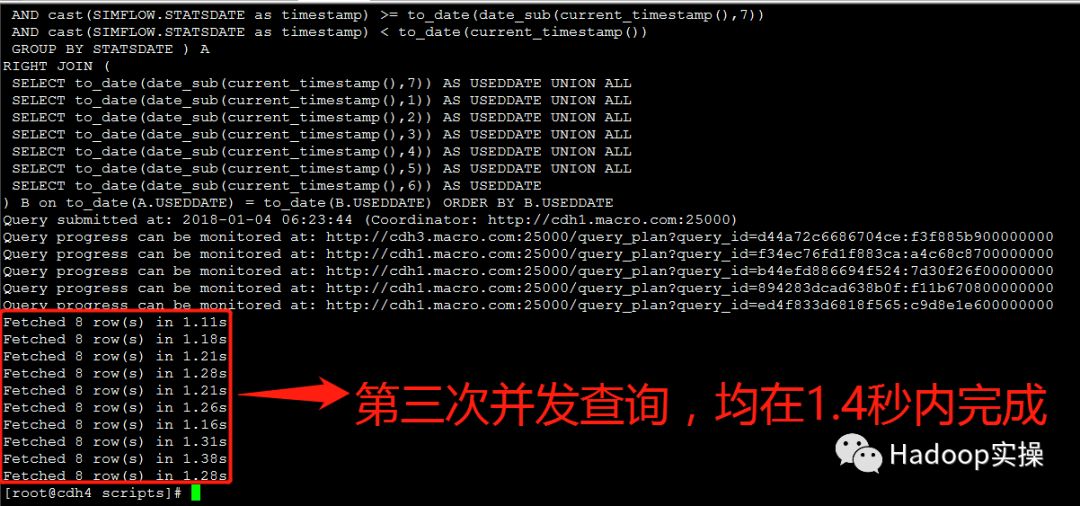
3.测试30个并发查询:
第一次测试:所有并发查询均在3.8秒内完成
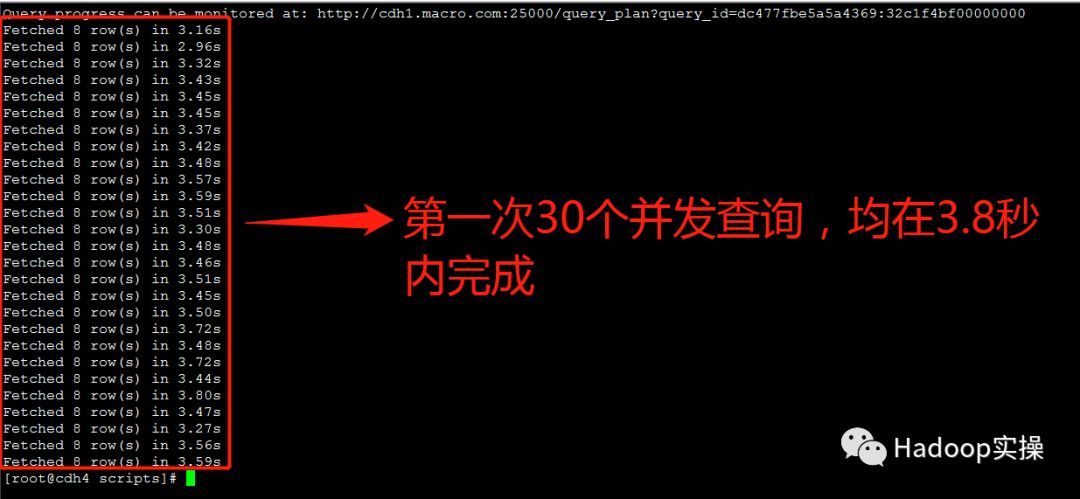
第二次测试:所有并发查询均在3.9秒内完成
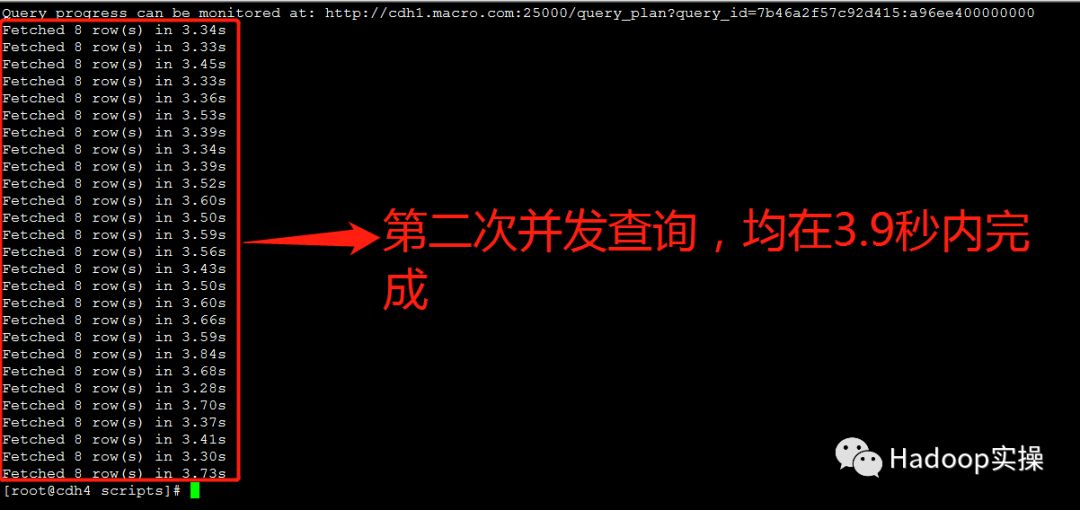
第三次测试:所有并发查询均在3.9秒内完成
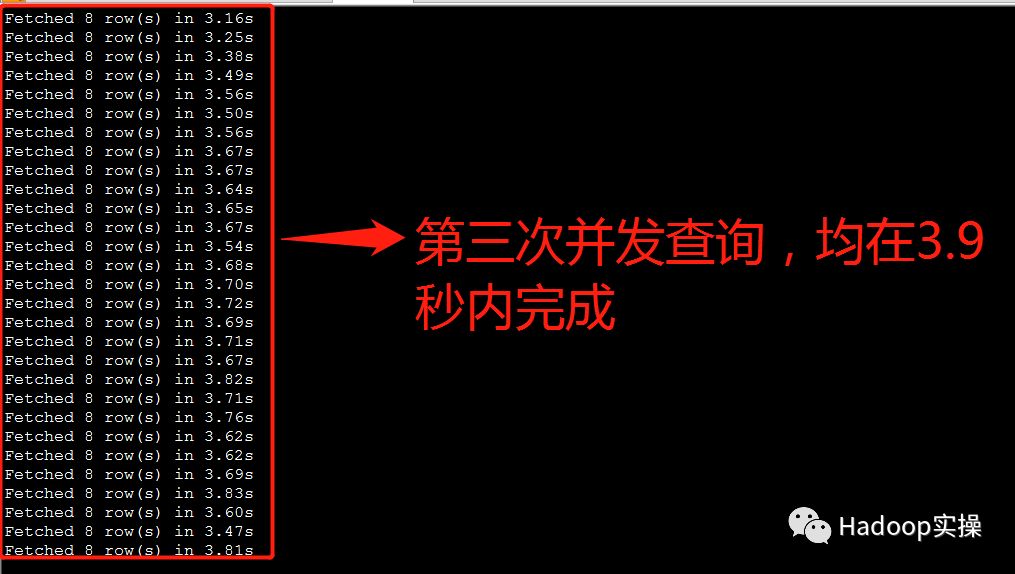
4.解决方案比较和总结
1.“TIMESTAMP转STRING类型”风险最高,改造最彻底,对业务系统影响最大,但是管理和维护成本最低;
2.“Impala重新生成Parquet文件”风险较小,需要额外占用集群资源并且需要考虑后续数据的处理,比较麻烦,可能需要定期做数据转换,管理和维护成本最高,但是对业务系统影响最小;
3.使用“构建Impala视图”的方式,管理和维护成本相对较高,会稍微对业务系统的使用产生影响,是比较折衷的问题解决方案,是改造时间最短的方案;
4.“构建Impala视图”需要设置Impala Daemon命令行高级配置参数:
--convert_legacy_hive_parquet_utc_timestamps=false
,这意味着所有涉及到TIMESTAMP字段的值都会延后8小时(UTC和CST时区的offset),如果要保证业务系统数据准确可用,那么需要为所有受影响的Parquet构建Impala视图,管理和维护成本较高,风险最小,对业务系统影响较小,但是不需要额外占用集群资源。如果不想更改业务查询系统,可以将Parquet表重命名,然后创建的视图使用对应Parquet表的原名,需要注意的是,更改表名后,如果写入数据涉及到表名,那么数据入库程序需要做相应变更。除此之外,因为是使用视图的方式校正时间戳,所以如果使用Hive查询视图的话,时间会提前8小时。建议Hive查询原表,Impala查询视图。
5.附录
1.设置
--convert_legacy_hive_parquet_utc_timestamps=false
的影响
修改配置参数之前,所有表/视图的同一条数据时间戳字段的值一致,均为2017-02-02 01:20:00
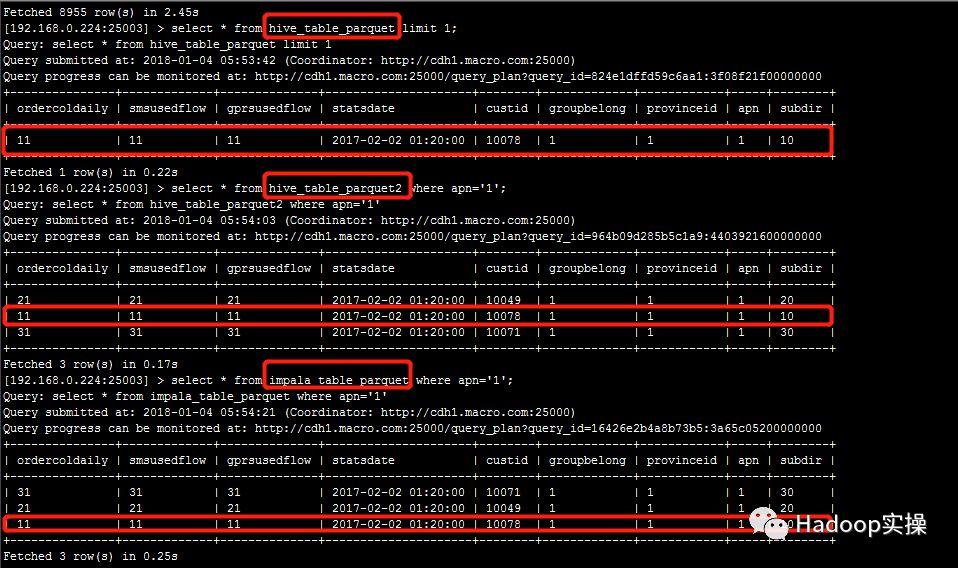
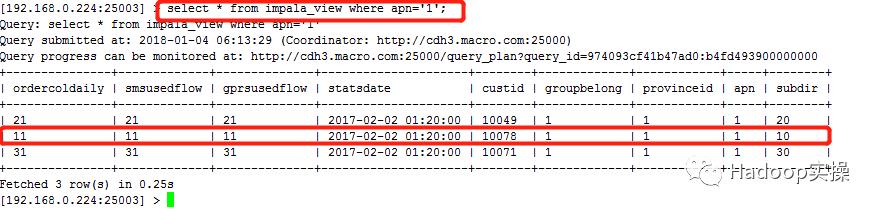
修改配置参数后,源Parquet表的同一条数据时间戳字段的值延后8小时,为2017-02-01 17:20:00,而其他表/视图的值为2017-02-02 01:20:00
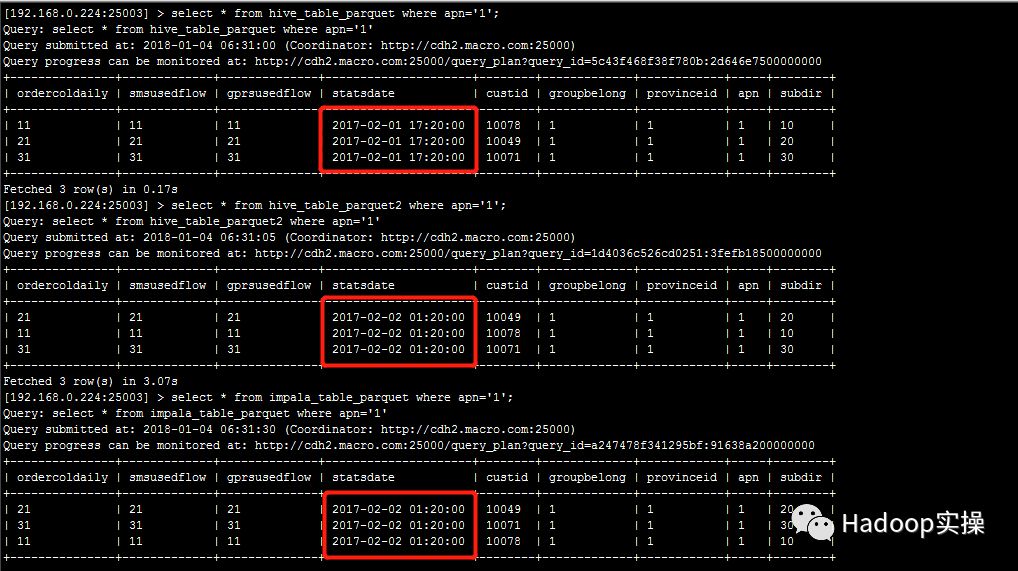
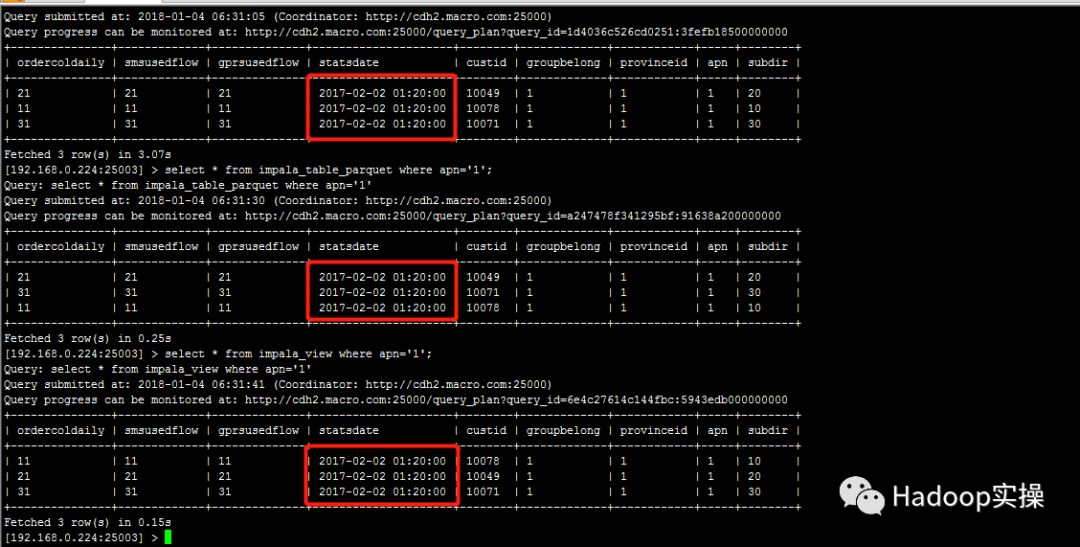
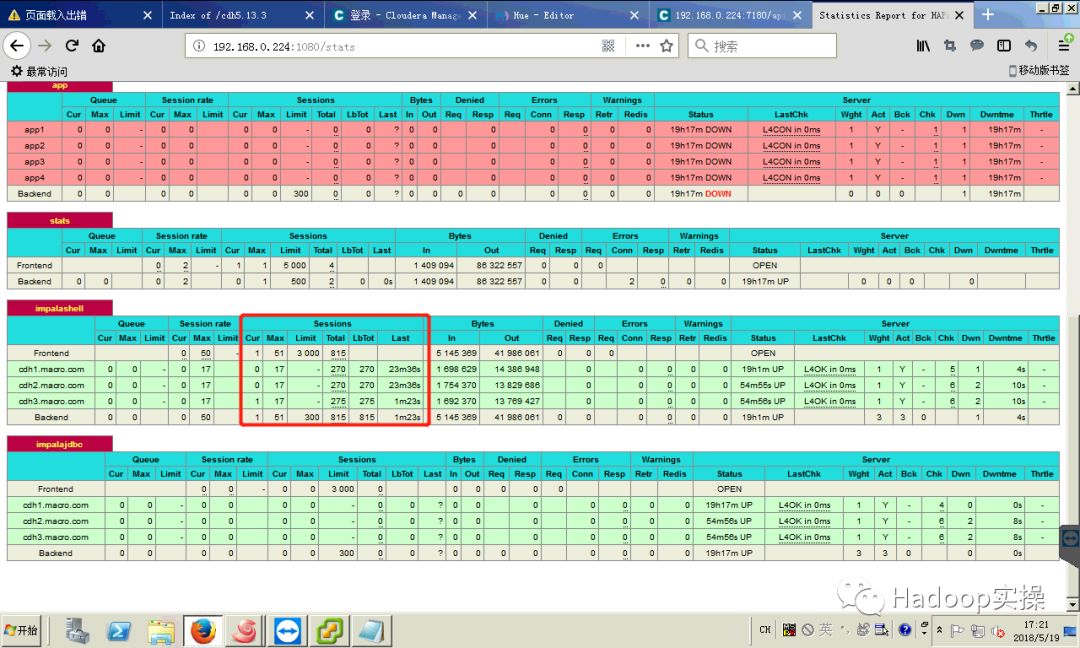
2.Impala负载均衡截图
做完所有并发测试后,查看Impala负载均衡,查询基本均匀分布在不同Impala Daemon上
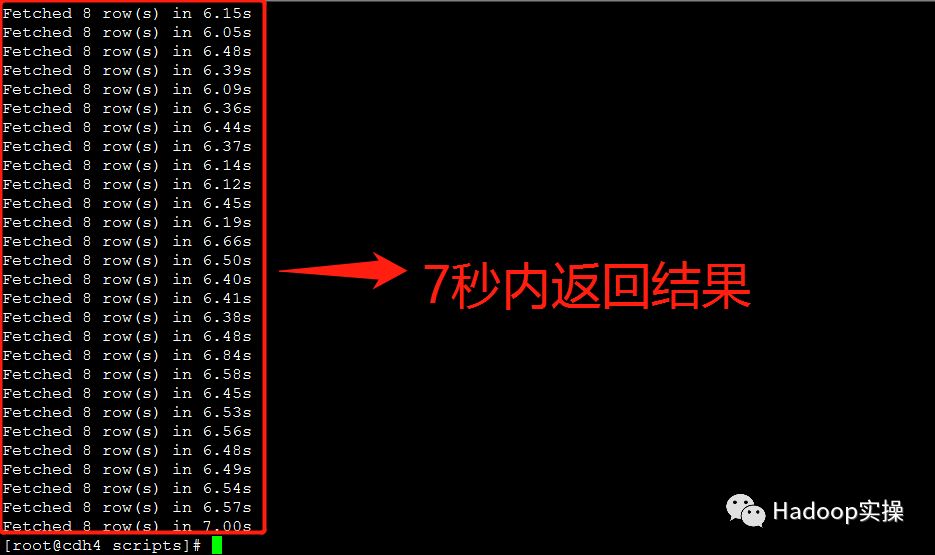
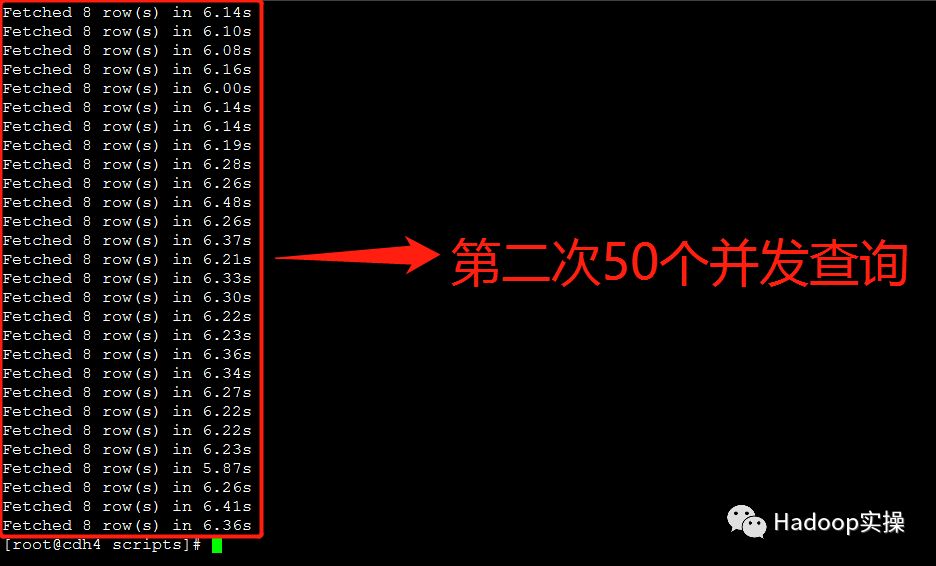
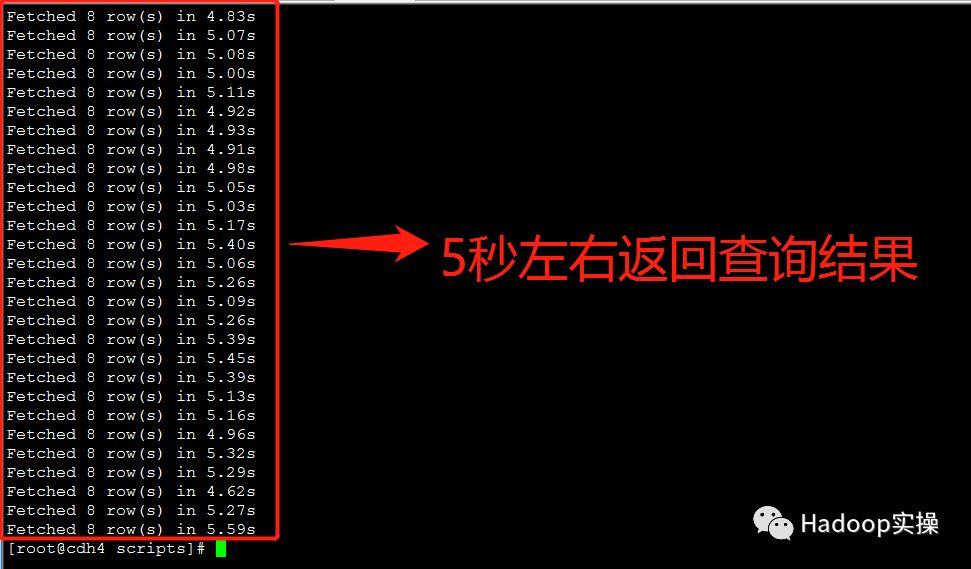
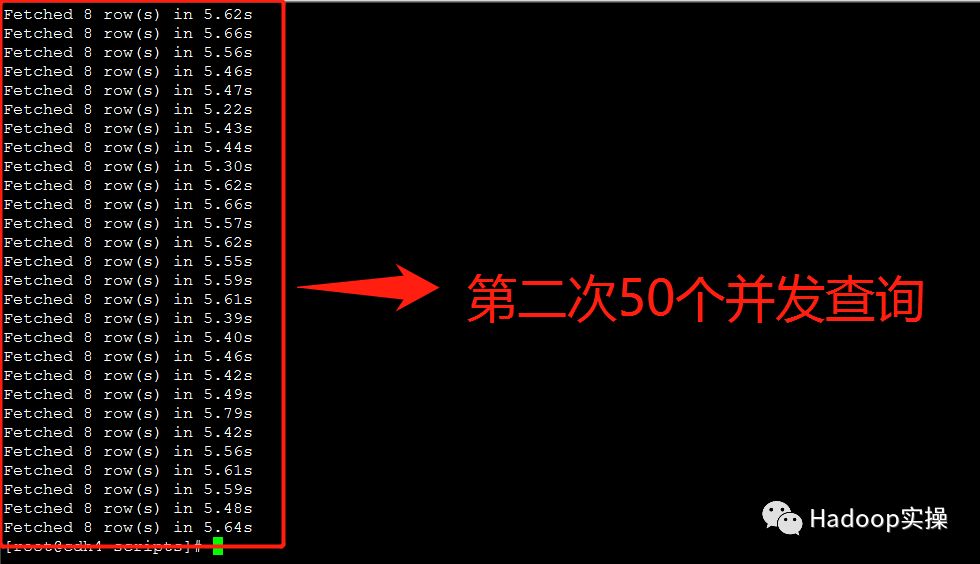
3.额外测试三种问题解决方案在50个并发查询情况下的返回结果
“TIMESTAMP转STRING类型”的方式基本在7秒左右返回查询结果
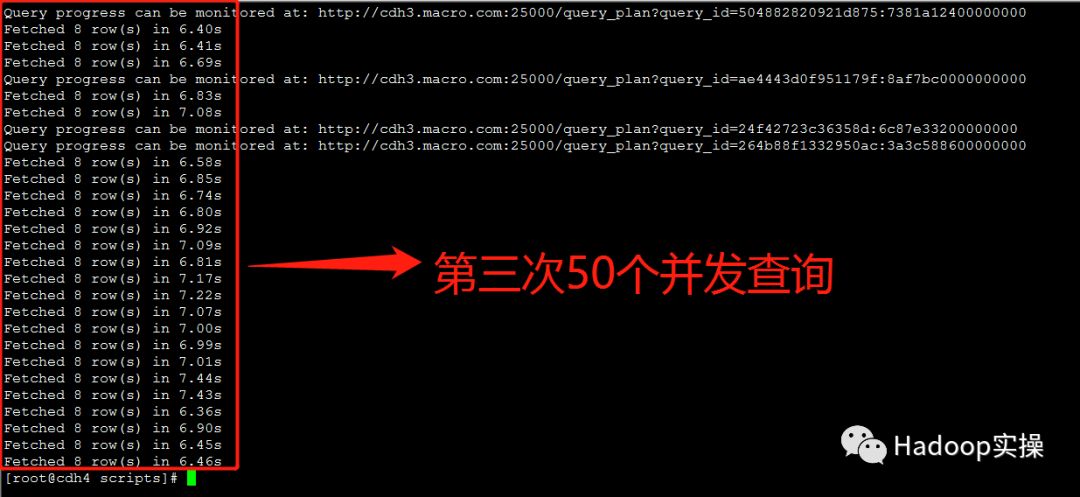
“Impala重新生成Parquet文件”的方式基本在6秒左右返回查询结果
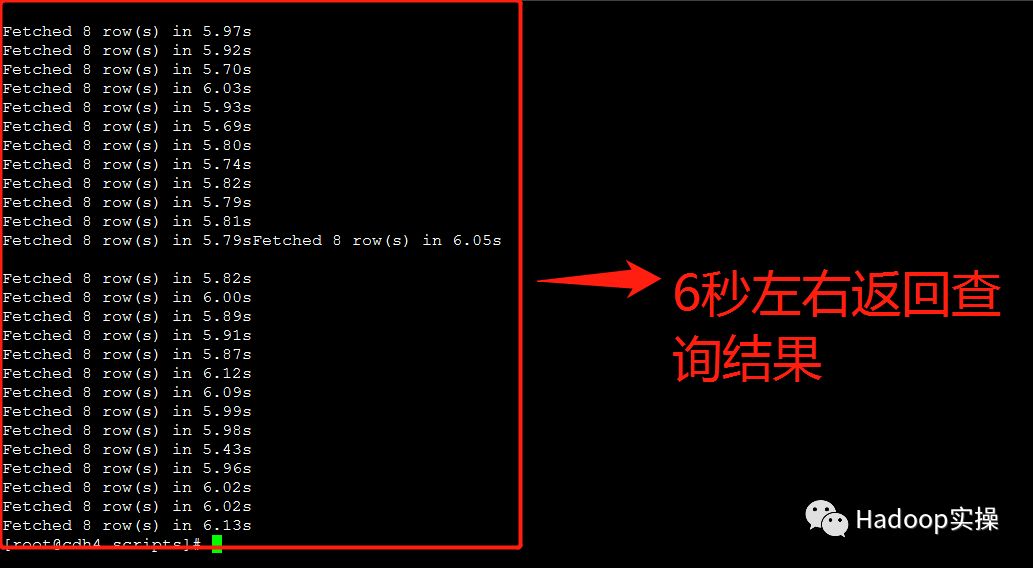

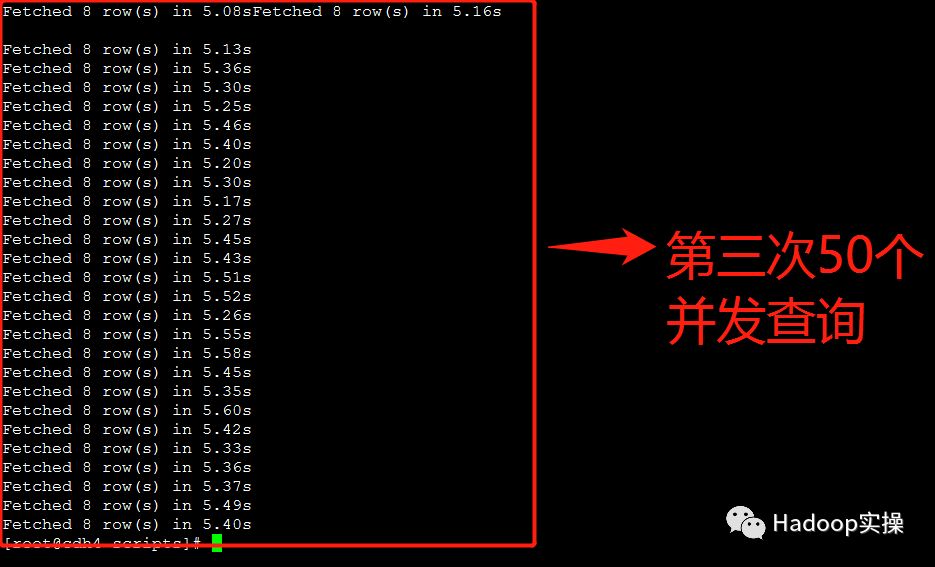
“构建Impala视图”的方式基本在5-6秒返回查询结果
测试脚本源码:
https://github.com/fayson/cdhproject/tree/master/ScriptFiles
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于Impala并发查询缓慢问题解决方案的主要内容,如果未能解决你的问题,请参考以下文章