网易严选案例:基于Alluxio+Impala深度融合架构的BI系统性能优化实践
Posted Alluxio
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网易严选案例:基于Alluxio+Impala深度融合架构的BI系统性能优化实践相关的知识,希望对你有一定的参考价值。
编者按—作者简介:耿昕,网易严选数据平台及风控部工程师,负责严选内部Alluxio与网易BI系统(网易有数)及Apache Impala系统的融合架构落地。
1
背景介绍
网易严选是网易旗下原创生活类电商品牌,秉承网易一贯的严谨态度,从源头全程严格把控商品生产环节,力求帮消费者甄选到优质的商品。作为一个数据驱动的电商品牌,网易严选依赖高效的BI系统、数据存储系统和查询引擎。本文深入介绍我们在网易严选BI产品中Alluxio与Apache Impala系统的深度融合架构方面的工作,以及落地过程中的具体实践和思考。通过引入Alluxio,我们有效地提升了原来Apache Impala系统的查询性能和稳定性。下面,首先简要介绍一下网易有数、Apache Impala和Alluxio。
1.1 网易有数
网易有数(见参考链接1)是网易公司开发的一款优秀的BI数据产品,用户可以通过友好便捷的可交互界面操作快速生成多样的数据分析报告、实时数据大屏等。
1.2 Apache Impala
Apache Impala(见参考链接2)是网易内部广泛使用的开源高性能MPP分析引擎之一,该系统在网易内部由网易数据科学中心负责持续的技术跟踪和改进(见参考链接3)。

1.3 Alluxio
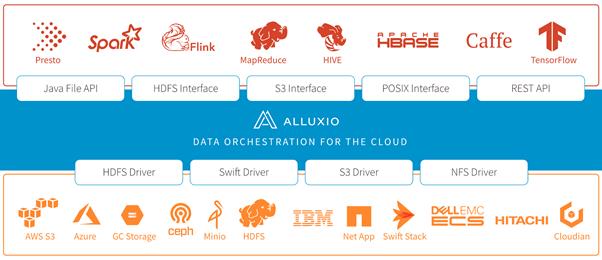
Alluxio(见参考链接4)是面向混合环境的开源数据编排系统。通过为底层文件系统提供统一的挂载命名空间、多层缓存和应用接口,Alluxio可以很好的支持大规模数据在各种环境(私有集群、混合云、公有云)中的高效访问。
2
Alluxio在网易严选BI场景的挑战分析
Alluxio的部署和使用方式非常简单,然而在大规模数据的BI场景中不经调优地直接使用Alluxio,性能结果与预想的存在一定差距。具体原因分析如下:
-
Alluxio并不像我们最初设想的那样,只是一个单纯的缓存服务。Alluxio首先是一个分布式的虚拟文件系统,有完整的元数据管理、块数据管理、UFS管理(底层文件系统的简称)以及健康检查机制,尤其是它的元数据管理实现比很多底层文件系统更加强大。这些功能是Alluxio的优点和特色,但也意味着如果每次都完整地使用Alluxio的全部功能,完成整个读操作的链路额外开销要比从一个单纯的代理服务、或支持自动Load的缓存服务要高。 -
对于大数据场景,内存缓存容量相对于计算引擎需要读取的数据量之间的比例常常是很低的。以严选为例,计算引擎每天需要读取的数据量在30TB左右,对比之下我们提供的1TB内存盘就显得捉襟见肘。低缓存量会导致低命中率和频繁逐出(Cache Eviction)开销,此时无论使用LRU、LRFU还是其他缓存策略,都无法带来明显改善。
3
基于Alluxio深度融合优化的BI系统架构
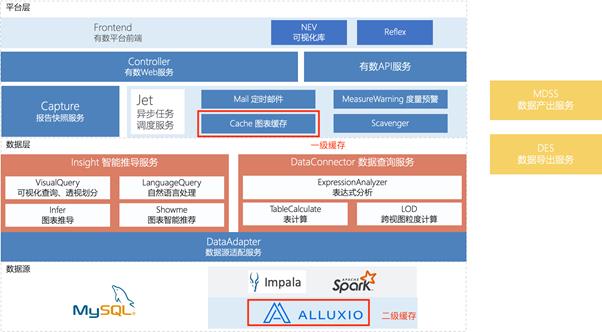
在使用Alluxio之前,网易有数系统已经使用Redis开发了内部的图表缓存功能(即下图中的一级缓存),用于主动缓存相对稳定或相对重要的图表数据。对于非稳定的图表,仍然需要通过Impala进行Adhoc查询,为了提升性能和稳定性,我们使用Alluxio作为Impala和HDFS之间的二级缓存。进一步,我们根据严选BI场景实践,提出并使用了以下几个主要的优化点:
3.1 提升元数据刷新效率
按需刷新元数据
由于在我们的场景中,Alluxio只供BI系统读数据使用,数据写操作仍然直接发生在HDFS上,所以会出现Alluxio与HDFS元数据不一致的情况,需要进行元数据同步(刷新)。这种不一致问题的常见处理方式是使用观察者模式,即在底层数据出现变化时被动触发Alluxio中对应path的元数据刷新,我们使用的也是这种方式。
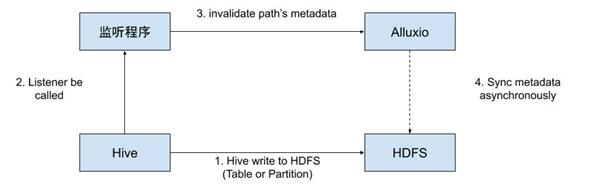
用invalidate替代refresh
3.2提升缓存性能
只尝试缓存“缓存价值”高的数据
在第2章中提到,由于我们的场景下缓存空间/数据量比例很小且数据的热度普遍不高,因此直接使用LRU等缓存策略的效果和性能不理想。我们的解决思路是将需要缓存的数据量减少,高效利用缓存,具体方式是只缓存最有“缓存价值”的数据。
数据块的缓存价值=节省的IO时间=(数据块大小 / 平均IO速度+读取数据块的额外时间开销)*数据块的读取次数
分区/表的缓存价值 = 该分区/表中所有数据块的缓存价值之和
3.3关于性能优化的更多建议
Alluxio文档(见参考链接5)中已经提供了非常丰富的性能优化建议,很多对于我们的优化也很有效。这里,我们进一步地根据我们在网易严选的实践经验总结出一些额外的建议。
注意Worker的Block锁带来的开销
AlluxioWorker中对数据块的大多数操作都需要加锁,而Alluxio源代码中加锁操作的实现不少地方还比较重量级,例如一次BlockLockManager.lockBlock的调用需要执行3次以上的各种类型的加锁操作(synchronized、ReadWriteLock、Semphore等),大量的加锁和解锁操作在并发较高时会带来不小的开销,因此建议在使用时注意结合代码检查是否有可以避免的加锁操作。
例如,如果你只使用了内存缓存,没有用到多级缓存,那么可以将alluxio.user.file.readtype.default设置为CACHE以避免moveBlock操作带来的加锁开销,替换默认的CACHE_PROMOTE(参考BlockReadHandler.openBlock方法)。
注意异步缓存请求发出的时机
当使用Parquet(见参考链接6)等列式存储格式时,上层计算引擎常常只读取数据块的一小部分,这时Alluxio为避免额外开销,并不会在worker同步缓存该数据块,而是做异步缓存。异步缓存的请求由Client在关闭Block流时发出,这会与Impala的文件缓存机制冲突。因为在Impala中为了降低重复打开文件的开销,会长时间(长达几个小时)缓存已打开的文件句柄,导致Alluxio client的异步缓存请求只有在句柄超时后才会发出,而此时缓存的意义已经不大。
事实上,如果监控到AsyncCacheRequests数量较少,或者跟数据计算的高峰时间不匹配,可以尝试降低Impala文件句柄的缓存时间,或者改为由worker端(非Client端)发出异步缓存请求(我们采用的是第二种方式,需要对worker的代码进行一些修改)。
HDFS C API异常
4
性能优化效果
4.1软硬件环境
Impala 2.12 & Alluxio1.8.2
我们将Impala和Alluxio同置部署在5台计算型物理机。每台物理机有40核、377GB内存,分别部署两个Impalaexecutor进程和一个Alluxio worker进程,每台机器上分配200GB内存作为Alluxio内存缓存。
HDFS 2.9.2
4.2 IO总量
在使用Alluxio之后,HDFS的IO总量明显下降。例如下图中,9月1日0点到9月2日0点之间,BytesReadLocal(短路读)增长约12TB,BytesReadAlluxio(从远程Worker读)增长约1TB,BytesReadUfsAll(从HDFS读)增长约3.6TB。计算得到当天的IO总量中只有21%穿透到了HDFS,剩余79%全部命中Alluxio缓存,而命中缓存的IO请求有91%是短路读。
4.3整体执行时间(SQL)
5
总 结
在本文中,我们总结了Alluxio在BI系统中落地的挑战点,以及我们在网易严选BI系统中落地和优化Alluxio的实践。进一步地,我们介绍了如何提升Alluxio元数据刷新和缓存性能,并给出了一些当前官方文档还没有记录的关于性能优化的建议(尤其是和Impala结合使用场景)。最后,我们实现的基于Alluxio优化的Impala查询方案能将整理SQL性能提升20%,且极大的降低了底层HDFS的数据读取量。
6
致 谢
感谢网易严选小伙伴祝佳俊、李宇航、杨周智以及网易数据中心小伙伴徐洲在本文相关工作中的贡献和支持。
参考链接:
链接1:https://youdata.163.com/
链接2:https://impala.apache.org/
链接3:https://bigdata.163yun.com/new/20
链接4:https://www.alluxio.io/
链接5:
https://docs.alluxio.io/os/user/stable/en/advanced/Performance-Tuning.html#worker-tuning
链接6:http://parquet.apache.org/
链接7:https://github.com/Alluxio/alluxio/pull/9920
·end·
—如果喜欢,快分享给你的朋友们吧—
以上是关于网易严选案例:基于Alluxio+Impala深度融合架构的BI系统性能优化实践的主要内容,如果未能解决你的问题,请参考以下文章