0757-6.3.3-如何配置impala自动同步HMS元数据
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了0757-6.3.3-如何配置impala自动同步HMS元数据相关的知识,希望对你有一定的参考价值。
在之前的文章中,Fayson 在《》 中提到Impala 的 Automatic Invalidate/Refresh Metadata 新功能,本文主要介绍如何配置Impala基于事件自动同步HMS元数据。
测试环境
1.CM和CDH版本为6.3.3
2.操作系统版本为RedHat 7.2
进入CM界面 > Hive > 配置 > 搜索 启用数据库中的存储通知(英文界面搜索:Enable Stored Notifications in Database),并且勾选,注意一定要勾选,配置后面的配置不生效。数据库通知的保留时间默认为2天,意味着如果事件通知没有更新超过2天事件将会丢失
在 CM界面 > Hive > 配置 > 搜索 hive-site.xml 配置如下几处
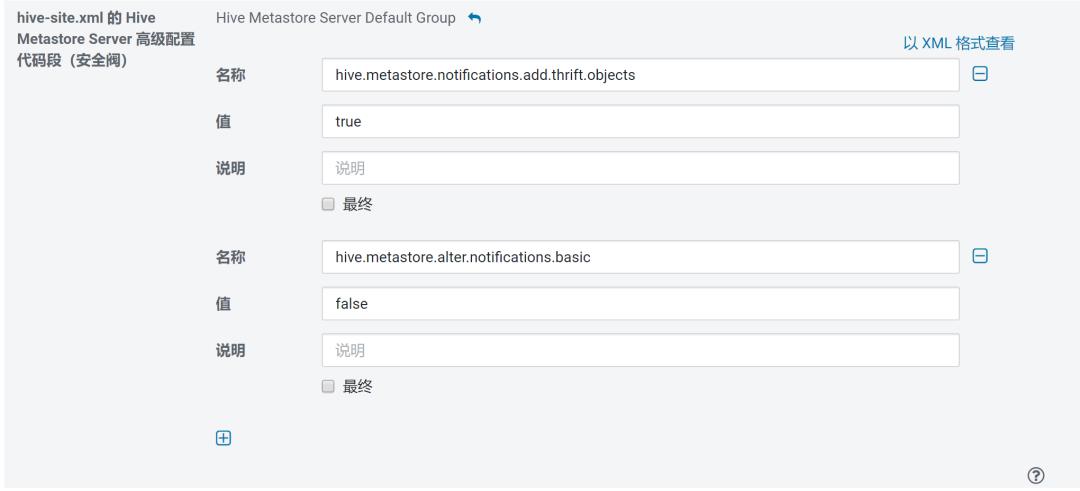
hive-site.xml 的 Hive Metastore Server 高级配置代码段(安全阀)
<property>
<name>hive.metastore.notifications.add.thrift.objects</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.alter.notifications.basic</name>
<value>false</value>
</property>
如果你想在使用Spark和其他应用程序将数据插入现有表和分区时会生成事件,需要在hive-site.xml 的 Hive 服务高级配置代码段(安全阀)以及hive-site.xml 的 Hive 客户端高级配置代码段(安全阀)添加配置
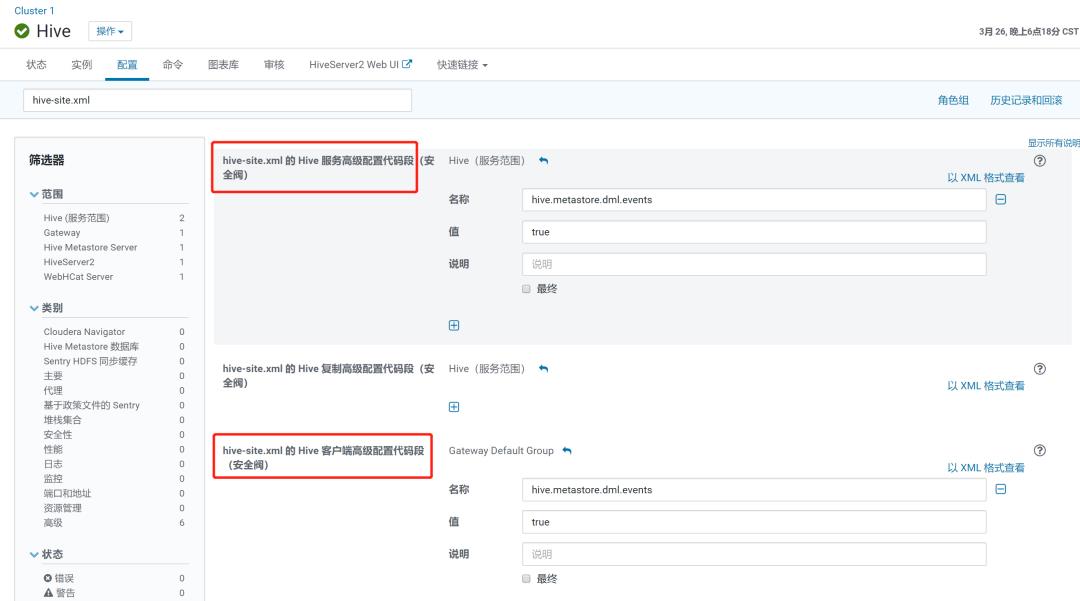
<property>
<name>hive.metastore.dml.events</name>
<value>true</value>
</property>
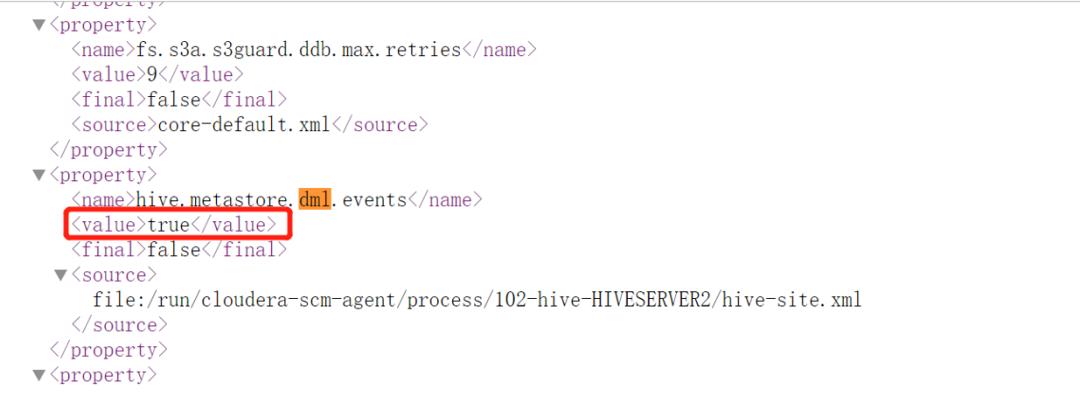
保存上述配置,并重启Hive 是配置生效,可以在webui 界面确认参数是否生效
然后在CM > Impala > 配置 > 搜索 catalog 命令行参数 添加如下配置,注意前面为两个英文中划线符号。
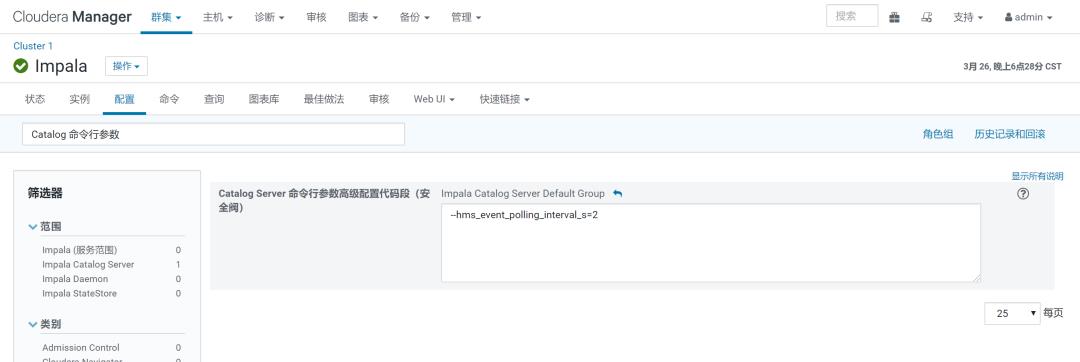
--hms_event_polling_interval_s=2
该参数表示启用hms 滚动事件功能并以秒为单位设置轮询频率,建议该值小于5秒,参数默认值为0 ,表示不启用。配置该参数前需要确认hive-site.xml 的 Hive Metastore Server 高级配置代码段(安全阀)的配置已经生效,否则重启impala 时,Catalog Server 将无法正常启动。
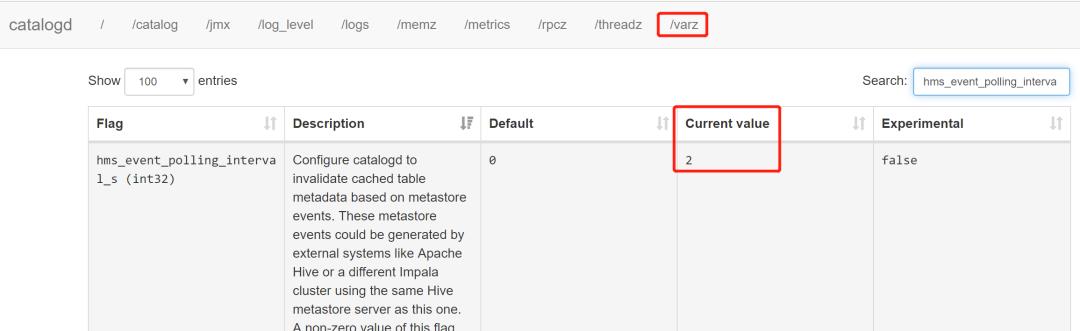
验证配置是否生效可以在Catalog Server WebUI 界面中 /varz 下查看
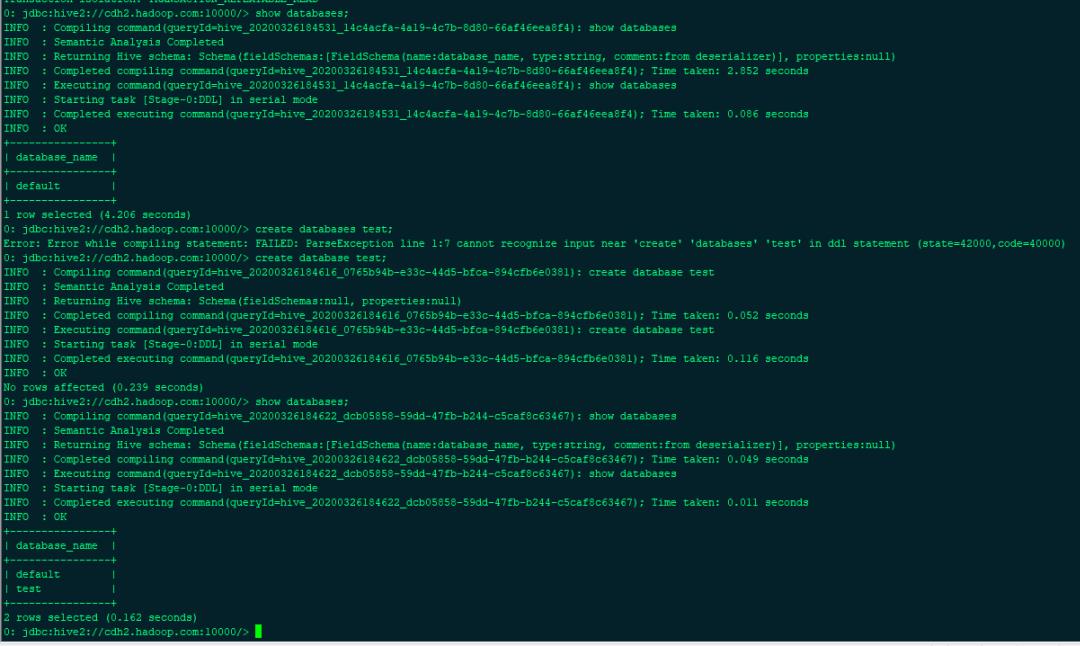
使用beeline 进入hive 中创建一个库,并查看
[root@cdh1 ~]# beeline
beeline> !connect jdbc:hive2://cdh2.hadoop.com:10000/
0: jdbc:hive2://cdh2.hadoop.com:10000/> show databases;
0: jdbc:hive2://cdh2.hadoop.com:10000/> create database test;
0: jdbc:hive2://cdh2.hadoop.com:10000/> show databases;
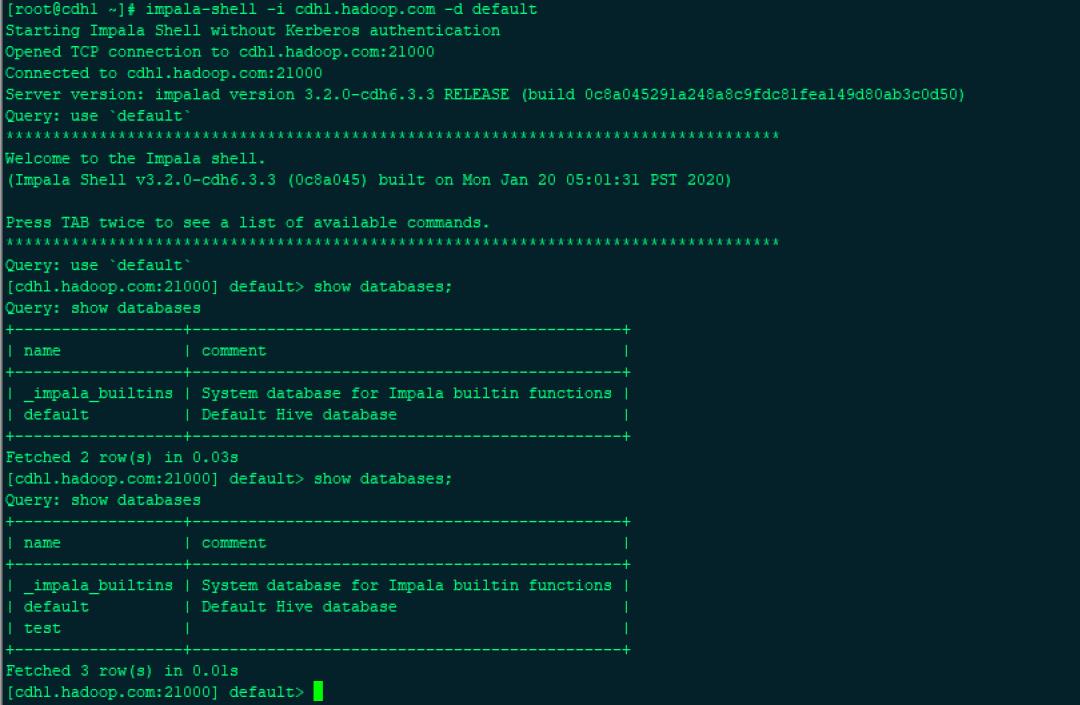
在Impala 中查看,显示已及时更新
[root@cdh1 ~]# impala-shell -i cdh1.hadoop.com -d default
[cdh1.hadoop.com:21000] default> show databases;
create table测试
0: jdbc:hive2://cdh2.hadoop.com:10000/> use test;
0: jdbc:hive2://cdh2.hadoop.com:10000/> create table test1(a string);
0: jdbc:hive2://cdh2.hadoop.com:10000/> create table test1(a string);
0: jdbc:hive2://cdh2.hadoop.com:10000/> show tables;
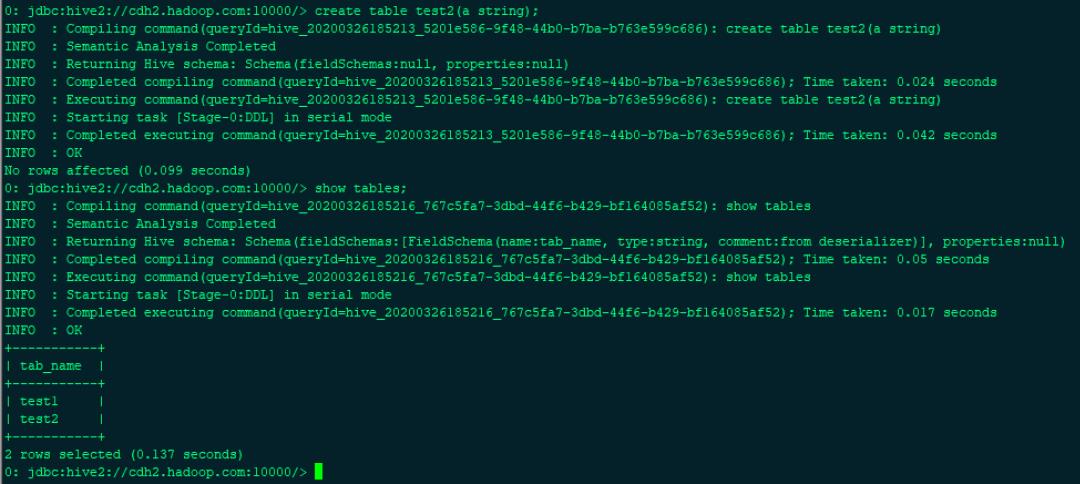
在impala 中查看
0: jdbc:hive2://cdh2.hadoop.com:10000/> use test;
0: jdbc:hive2://cdh2.hadoop.com:10000/> create table test1(a string);
0: jdbc:hive2://cdh2.hadoop.com:10000/> create table test1(a string);
0: jdbc:hive2://cdh2.hadoop.com:10000/> show tables;
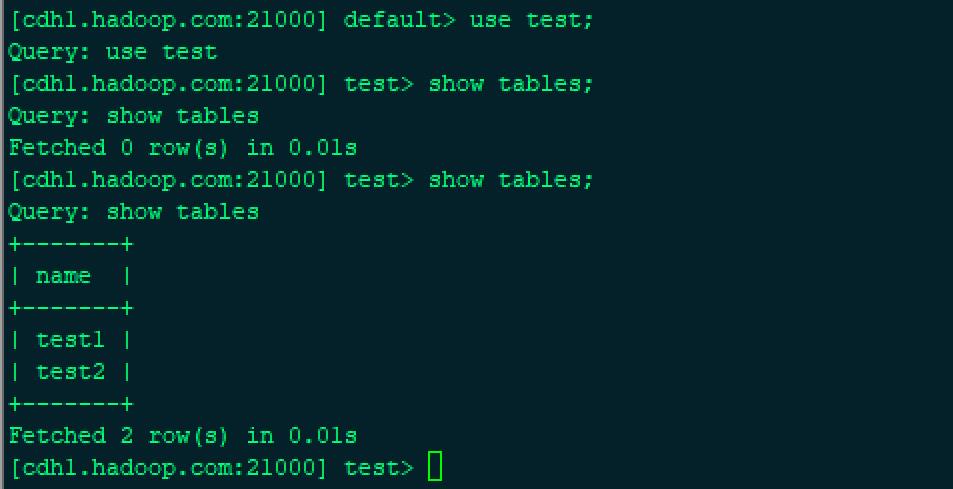
drop table 测试
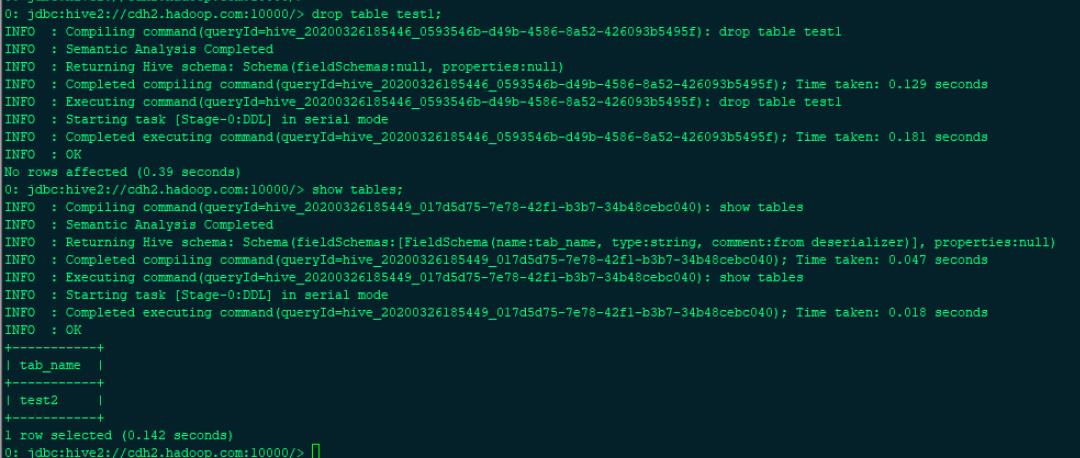
0: jdbc:hive2://cdh2.hadoop.com:10000/> drop table test1;
0: jdbc:hive2://cdh2.hadoop.com:10000/> show tables;
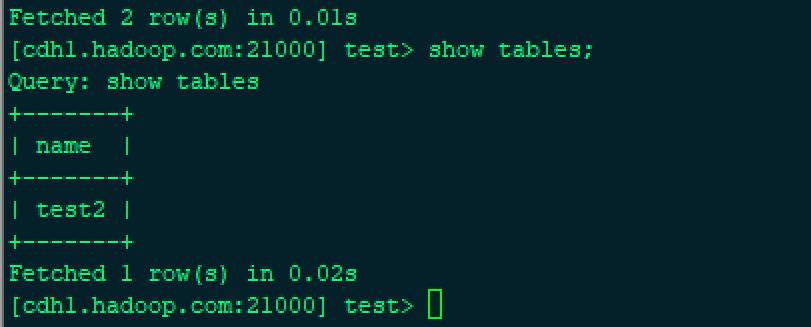
在impala 中查看
[cdh1.hadoop.com:21000] test> show tables;
另外HMS 支持表单独禁用impala 自动刷新元数据功能,但是impala 中不支持database 的单独禁用该功能
如果 'impala.disableHmsSync'='true',表示事件将被忽略,并且不会与HMS同步。
如果设置 'impala.disableHmsSync'='false' 或者 impala.disableHmsSync 未设置,则启用与HMS的自动同步,- -hms_event_polling_interval_s 全局标志设置为非零。
0: jdbc:hive2://cdh2.hadoop.com:10000/> CREATE TABLE disabletest (s1 string ,s2 string) TBLPROPERTIES ('impala.disableHmsSync'='true');
单独禁用表的自动更新元数据后在impala就无法查询刚刚创建的表
在日常使用如Hive和Spark之类的工具来处理Hive表中的原始数据时,会生成新的HMS元数据(数据库、表、分区)和文件系统元数据(现有分区/表中的新文件)。在以前的Impala版本中,为了获取最新元数据信息,Impala需要手动执行INVALIDATE 或者 REFRESH 命令。随着impala 功能的不断完善,impala 的元数据同步问题终于在impala3.2得到有效的解决,并且该配置在CDP7.0.3中默认已经集成。
参考文档:
https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/impala_metadata.html以上是关于0757-6.3.3-如何配置impala自动同步HMS元数据的主要内容,如果未能解决你的问题,请参考以下文章
hadoop生态系统学习之路hbase与hive的数据同步以及hive与impala的数据同步