如何为Impala Daemon服务配置Executor和Coordinator角色
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何为Impala Daemon服务配置Executor和Coordinator角色相关的知识,希望对你有一定的参考价值。
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
Fayson的github:
https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1.文档编写目的
默认情况下,CDH集群中的Impala Daemon又可以充当查询的coordinator,也可以作为executor来执行查询本身,coordinator类似一个查询作业的管理角色一样负责协调各个Impala Daemon上的executor。在大规模集群中,Impala作业比较多的情况下,一个Impala Daemon既作为coordinator又作为executor是比较常见的,这就不可避免的会带来一些问题:
1.coordinator与executor会互相干扰带来性能问题。对于较大或者复杂的查询的时候,coordinator会带来大量的网络和CPU开销。每个coordinator都会缓存所有表分区和数据文件的元数据,同时作为executor它还需要处理join,聚合或者其他操作,这些都需要大量内存。
2.将大量主机都作为coordinator会造成不必要的网络开销,甚至是timeout错误,因为每个coordinator都需要与statestore进程通信以进行元数据更新。
3.当有大量查询负载较重的Impala Daemon作为coordinator时,会更容易超过admission control所设置的"soft limits"。
所以从CDH5.12开始,Impala支持分离coordinator与executor,可以明确指定哪些主机只作为coordinator,而不作为executor。这些节点不会参与I/O密集型操作比如扫描,或者CPU密集型操作比如聚合。同时你也可以指定哪些主机只作为executor,而不作为coordinator,它们依旧会与statestore进程进行通信,但是不会从statestore获取元数据,你不能通过impala-shell客户端或者BI工具连接到这些主机。
本篇文章Fayson主要介绍如何为Impala Daemon服务配置Coordinator和Executor角色,从而解决大规模集群下Impala查询性能瓶颈问题。
测试环境
1.CM5.14.3/CDH5.14.2
2.RedHat7.4
前置条件
1.集群已启用Kerberos
2.集群已集成Sentry服务
3.Impala已配置HAProxy负载
2.配置Impala服务的Coordinator和Executor
这里以Fayson的测试环境为例,选择集群的两个节点cdh02和cdh03节点的ImpalaDaemon作为Coordinator角色,cdh04和cdh04节点的Impala Daemon作为Executor角色进行配置说明。
1.登录Cloudera Manager界面进入Impala服务,点击“配置”
2.进入角色组界面,新建Coordinator角色组,将一部分Impala Daemon节点划分为Coordinator Group角色组
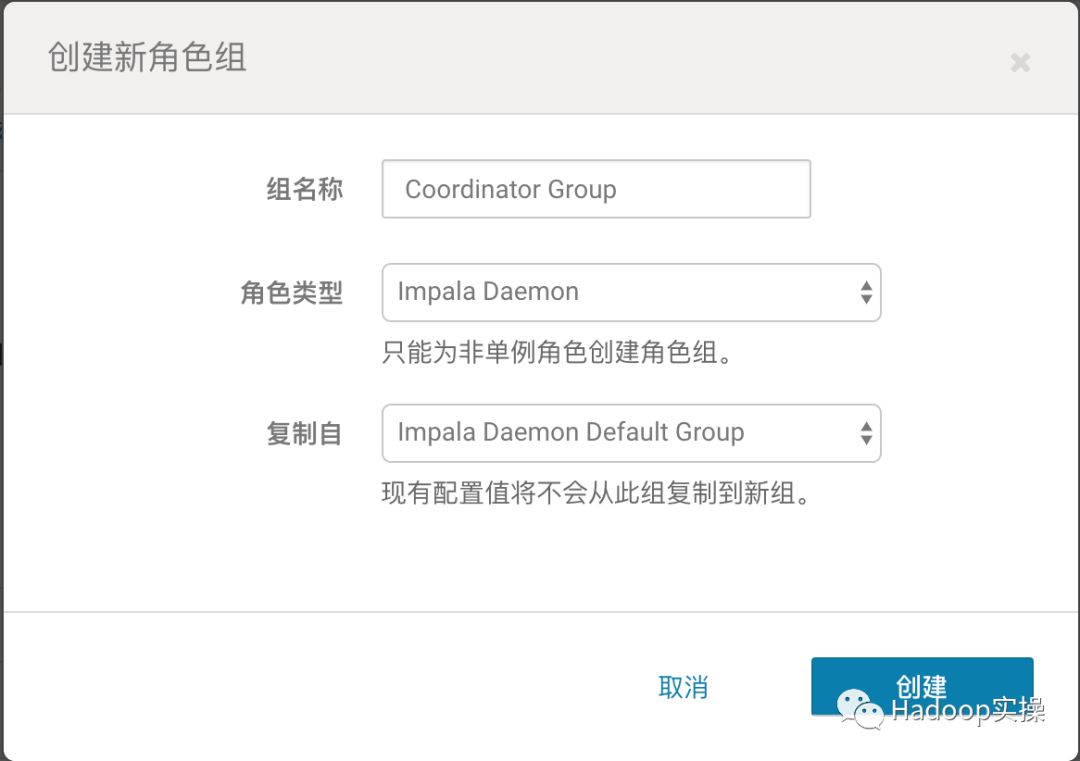
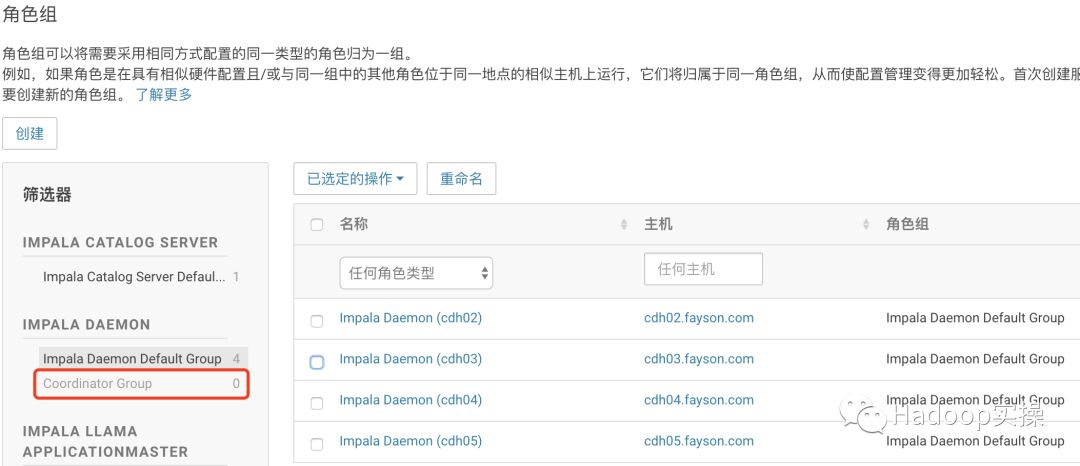
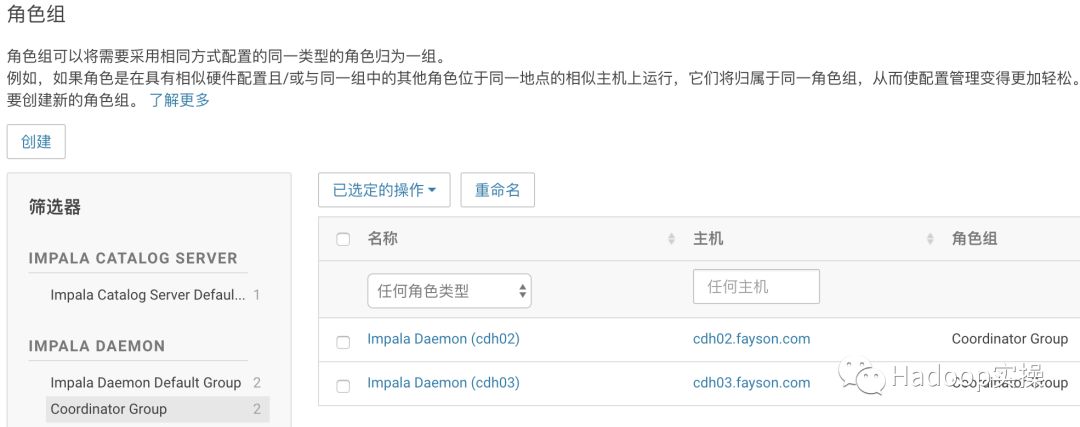
2.将cdh02和cdh03两个节点移到Coordinator Group组
4.进入Impala的配置页面,为我们划分的两个组配置高级参数
在Impala配置中搜索“Impala Daemon 命令行参数高级配置代码段(安全阀)”,为Default Group组配置-is_coordinator = false,为Coordinator Group配置-is_executor = true,如下截图所示:
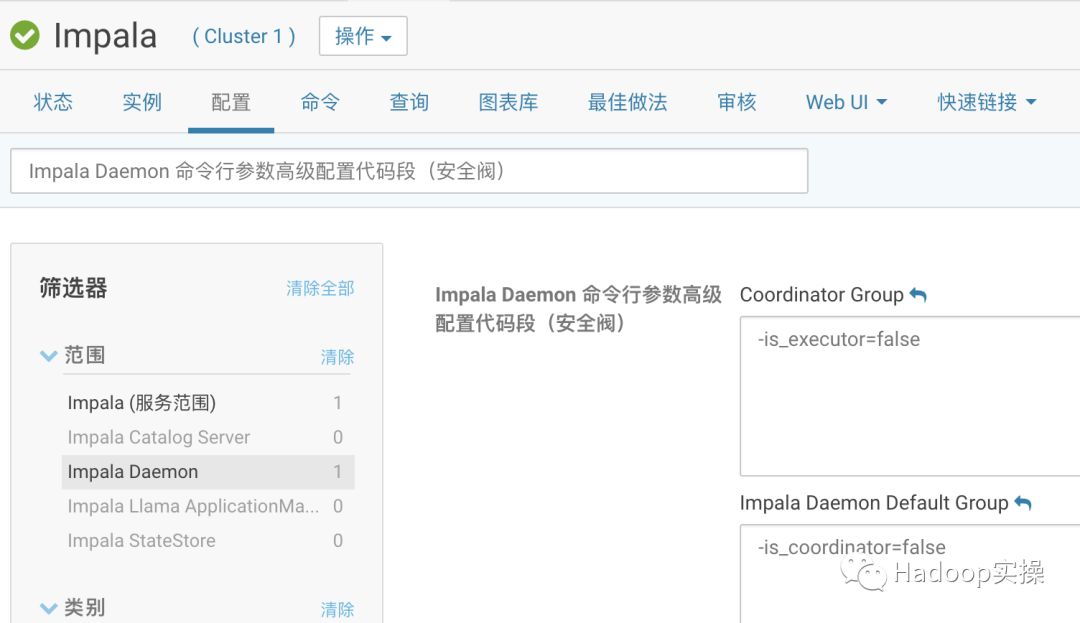
保存配置,根据CM提示重启Impala服务。
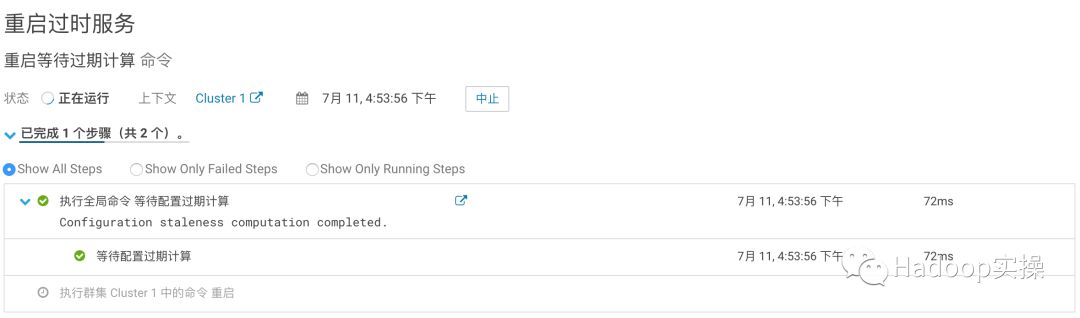
3.修改HAProxy的配置
1.修改/etc/haproxy/haproxy.cfg文件,将Coordinator Group组的Impala Daemon节点配置到haproxy.cfg文件中,内容如下:
listen impalashell
bind 0.0.0.0:25003
mode tcp
option tcplog
balance leastconn
server cdh02.fayson.com cdh02.fayson.com:21000 check
server cdh03.fayson.com cdh03.fayson.com:21000 check
listen impalajdbc
bind 0.0.0.0:25004
mode tcp
option tcplog
balance leastconn
server cdh02.fayson.com cdh02.fayson.com:21050 check
server cdh03.fayson.com cdh03.fayson.com:21050 check
(可左右滑动)
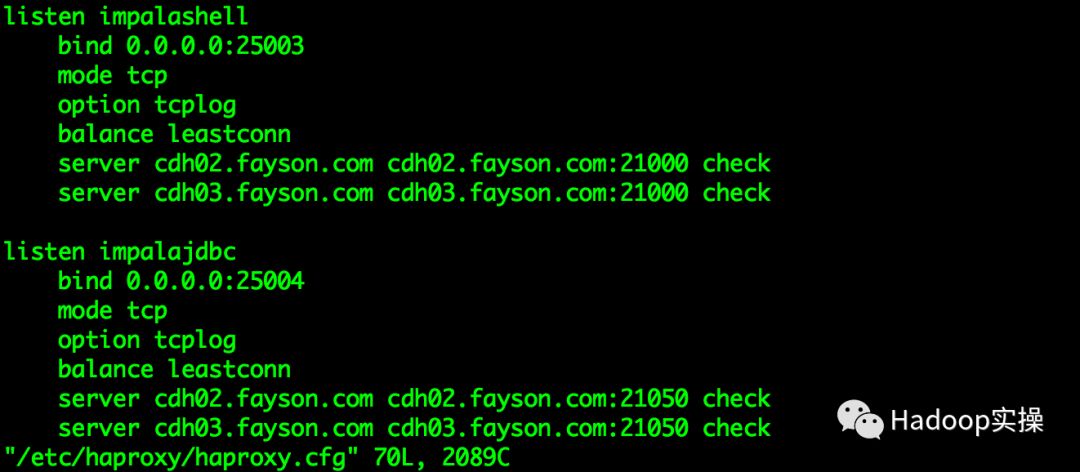
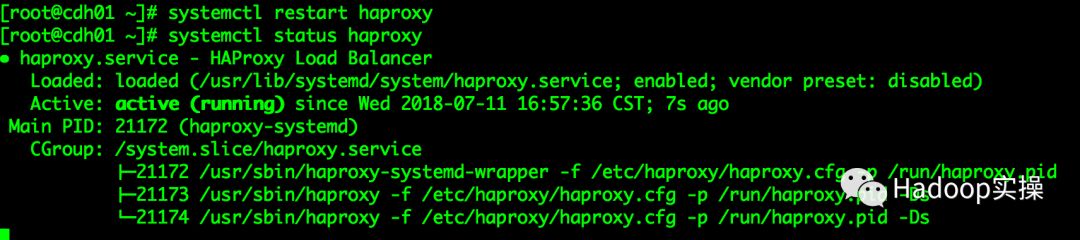
2.保存配置,然后重启Impala服务
[root@cdh01 ~]# systemctl restart haproxy
[root@cdh01 ~]# systemctl status haproxy
(可左右滑动)
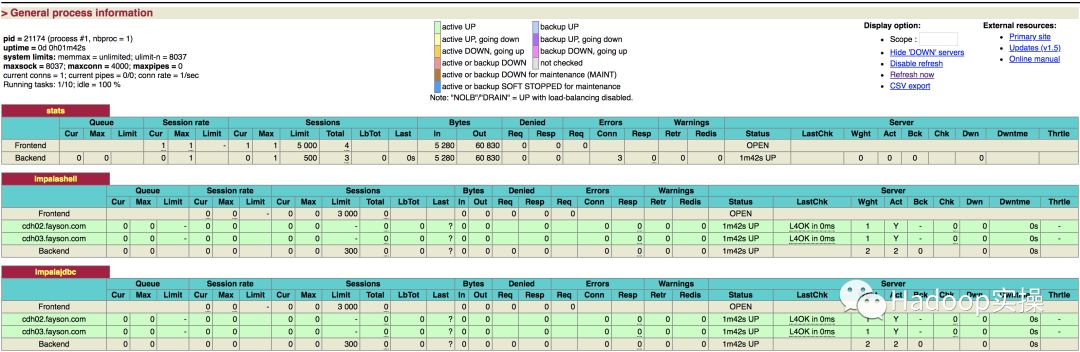
3.访问HAProxy服务监控界面查看
4.Impala-shell测试
1.使用impala-shell命令访问HAProxy端口
2.执行SQL操作,通过CM查看SQL执行详细信息
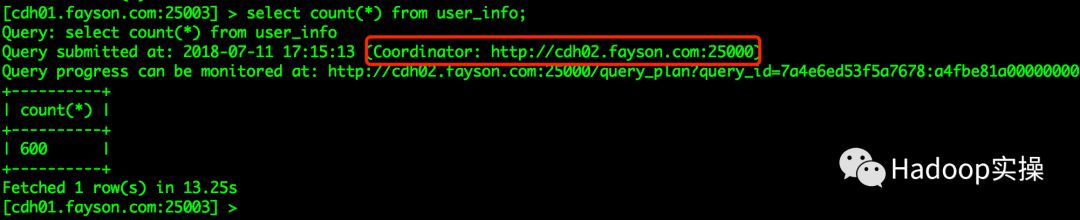
通过CM查看到的SQL执行详细信息可以看到cdh02将接受的查询请求转发至cdh04节点,该节点为Executor角色的Impala Daemon。
5.总结
1.对于较大的Impala集群,我们在配置Impala Daemon负载均衡时可以将一部分Impala Daemon节点配置为Coordinator角色。这里需要考虑的问题,Coordinator角色的节点可以部署在非DataNode节点上,保证所有的Executor角色的节点都能在所有的DataNode节点,避免Impala跨节点读取数据。
2.配置为Coordinator角色的Impala Daemon可以通过impala-shell访问,但配置为Executor角色的Impala Daemon是不可以通过impala-shell访问。
3.作为Coordinator角色的Impala Daemon节点作为HAProxy的后端,用于配置Impala集群负载均衡。
4.Coordinator角色的Impala Daemon节点不会参与运算而仅负责调度和监控查询的执行,以及同步元数据,而Executor角色的Impala节点仅参与运算但不会同步数据。
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于如何为Impala Daemon服务配置Executor和Coordinator角色的主要内容,如果未能解决你的问题,请参考以下文章