Impala?难道 Presto 不香吗?
Posted 老蒙大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Impala?难道 Presto 不香吗?相关的知识,希望对你有一定的参考价值。
导读(老蒙): Presto 是当下比较流行的即席查询引擎,相比另一个相似的引擎 Impala ,Presto 是 Java 开发的,拥有更好的社区资源(毕竟做大数据的都喜欢用 Java)。这篇文章比较基础,对 Presto 做了一个基本的讲解,包括各个进程的作用,编程模型,整体架构等等内容,是入门理解 Presto 的一篇好文章。
多数据源:通过自定义Connector能支持mysql,Hive,Kafka等多种数据源
支持SQL:完全支持ANSI SQL
扩展性:支持自定义开发Connector和UDF
混合计算:可以根据需要将开源于不同数据源的多个Catalog进行混合join计算
高性能:10倍于Hive的查询性能
流水线:基于Pipeline涉及,在数据处理过程当中不用等到所有数据都处理完成后再查看结果
1. 基本概念
1.1. 服务进程
Coordinator
主要作用:接受查询请求、解析查询语句、生成查询执行计划、任务调度、Worker管理
部署于服务器的一个单独节点上,是整个集群的Master节点
与Worker通信获得最新的状态信息,同时接受Client的查询请求
所有信息交互通过StatmentResource类提供的RESTful接口完成
Worker
工作节点,完成数据的处理和Task的执行
定时向Coordinator上报心跳
1.2. Presto模型
Connector
连接器,可以理解为Presto访问不同数据源的驱动程序;每个Connector都实现了Presto的标准SPI接口,因此只要自己实现SPI接口,就可以实现适合自己需求的Connector。Presto Connector Manager根据对应Connector的配置文件中connector.name属性来决定访问数据源时使用的ConnectorCatalog
类似于Mysql中的数据库实例,配置Connector配置文件时的文件名就是对应数据源的Catalog名。Schema
类似于Mysql中的Database,一个Catalog+一个Schema就唯一确定了一系列可查询的表集合。Table
就是传统数据库中表的概念。一份表的全称组合是 Catalog.Schema.Table
1.3. 查询执行模型
Statement:即输入的SQL语句;Presto支持符合ANSI标准的SQL语句,由字句,表达式和断言组成
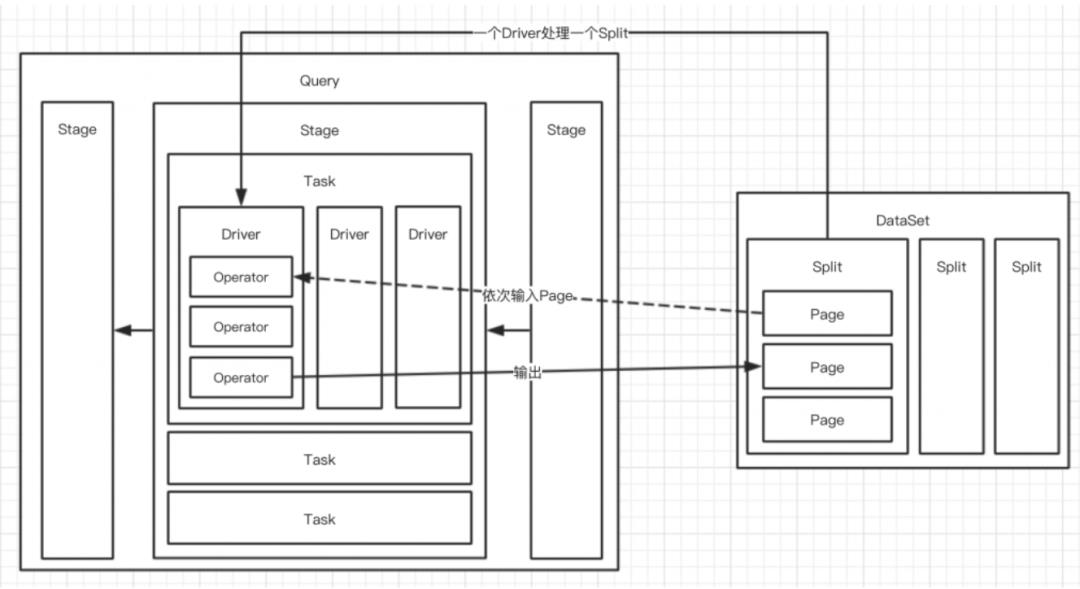
Query:即查询执行,当Presto接受SQL并执行时,会解析SQL并转变成一个查询执行和相关的查询计划。查询由运行在多个Worker上且相互关联的Stage组成的。
Coordinator_Only:用于执行DDL或者DML语句中最终的表结构创建和更改
Single:没有下游Stage,结果直接输出给Coordinator,用于聚合其他Stage的输出数据,并最终返回给终端用户
Source:没有上游Stage,从Coordinator获取数据,用于直接连接数据源,获取原始数据。也会根据查询计划的优化相关完成断言下发和条件过滤等
Fixed:用于接收其子Stage产生的数据并进行分布式聚合和分组运算
Output Buffer:产生数据的Stage通过这个Exchange将数据传送给下游Stage
Exchange Client:消费数据的Stage通过这个Exchange从上游Stage获取数据
1.4. Presto执行查询的模型关系
1.5. 整体架构
硬件方面
硬件必须满足大内存,万兆网络和高计算性能特点。集群为Master-Slave的拓扑架构。
软件方面
-
Client通过HTTP发送SQL查询语句给Coordinator -
Coordinator解析查询语句,生成查询执行计划。Coordinator会根据数据本地性生成对应的HttpRemoteTask -
Coordinator分发Task到对应Work,通过HttpClient发送给节点上TaskResource提供的RESTful接口;Worker启动一个SqlTaskExecution对象或者更新对应对象需要处理的Split -
执行处于上游Source Stage中的Task,这些Task通过Connector从数据源中读取数据 -
处于下游Stage的Task读取上游输出结果,并在内存中进行计算和处理 -
Coordinator会不断从Single Stage中的Task处获取结果,并缓存到Buffer中,直到所有计算结束 -
Client不停从Coordinator中获取本次查询结果,直到获取了所有结果
有收获就点个「赞」吧 ▼
以上是关于Impala?难道 Presto 不香吗?的主要内容,如果未能解决你的问题,请参考以下文章