赛尔原创 | 基于词的神经网络中文分词方法
Posted 哈工大SCIR
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了赛尔原创 | 基于词的神经网络中文分词方法相关的知识,希望对你有一定的参考价值。
1 引言
中文分词是很多中文自然语言处理任务的第一步。中文分词的方法中,认识程度最高的是基于字的分类或序列标注方法。对于输入字序列,这一类方法解码出代表词边界的标签,然后从这些标签中恢复出分词结果。基于字的方法具有简单高效的特点,也有诸如无法直接利用词级别特征的缺点。不同于基于字的方法,基于词的中文分词方法能够在解码过程中获得部分的分词结果,因而能够充分利用词级别的特征。在中文分词研究的不同阶段,基于词的方法都取得了与基于字的方法相匹敌甚至更好的结果[Aandrew2006]。
深度学习的浪潮给自然语言处理研究带来诸多新思路。其中一项非常重要的思路是使用稠密向量与非线性的网络表示自然语言。在这样的背景下,基于词的神经网络中文分词方法成为一个很有趣的研究问题。如何表示中文分词中的词向量,词向量表示能否与解码算法很好的融合等都是基于词的神经网络中文分词方法要回答的问题。
2 SRNN – semi-CRF与神经网络的首次结合
在ICLR2016上,Kong等人发表了一篇名为 Segmental Recurrent Neural Networks (SRNN)的工作[Kong et al.2015]。这篇工作的核心思想是将semi-CRF算法与神经网络进行结合。
虽然semi-CRF看起来比较陌生,但它的“近邻”——线性链条件随机场(linear chain CRF或CRF)相信大家都很熟悉。CRF基于马尔科夫过程建模,算法在随机过程的每步对输入序列的一个元素进行标注。而semi-CRF则是基于半-马尔科夫过程建模,算法在每步给序列中的连续元素标注成相同的标签。semi-CRF算法的这一性质使得它可以直接应用于中文分词任务。标注连续元素的行为可以看做从字序列中识别出词来。形式化地讲,semi-CRF建模的是整句分割的概率。其函数形式如下:
其中,x对应输入字序列,s对应分词序列。G(x,s)将x和s表示为特征向量。G是一种泛化的函数,它的输出可以是稀疏的0-1向量,也可以是稠密的词表示。
回到SRNN这项工作。如前文所述,深度学习的一大优势在于强大的特征表示能力。Kong等人希望利用这一优势,使用神经网络建模G。具体来讲,他们使用一个双向RNN作为G函数。这个双向RNN将成词的若干个字的向量组合为这个词的向量。他们的模型如图1所示。由于这种网络具有将字向量组合成词向量的功能,本文称其为组合网络。
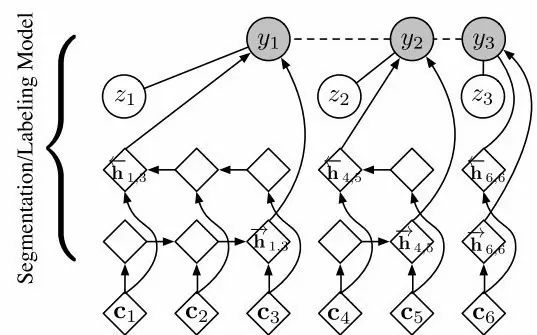
图1 SRNN的网络结构
Kong等人在PKU和MSR数据集上测试了他们的模型,并分别获得了90.6 和90.7的准确率。我们在其工作的基础上尝试了更多的超参设置,并最终取得了93.91和95.21的准确率。不过,无论是原始结果还是我们调参后的结果,SRNN相较state-of-the-art都有很大的差距。这一差距值得我们思考背后的问题。一个可能的问题是双向RNN不是一种好的组合网络。另一个可能的问题是组合网络并不能足够有效地表达词的信息。
3 其他组合网络
从“双向RNN不是一种好的组合网络”这个角度出发,我们在IJCAI2016发表的工作 Exploring Segment Representations for Neural Segmentation Models 中尝试了两种双向RNN的替代网络:CNN以及直接拼接。实验结果如表1所示。结果显示,使用CNN (SCNN)或拼接 (SCONCATE)都无法取得与基线结果类似的性能,准确率甚至低于SRNN。
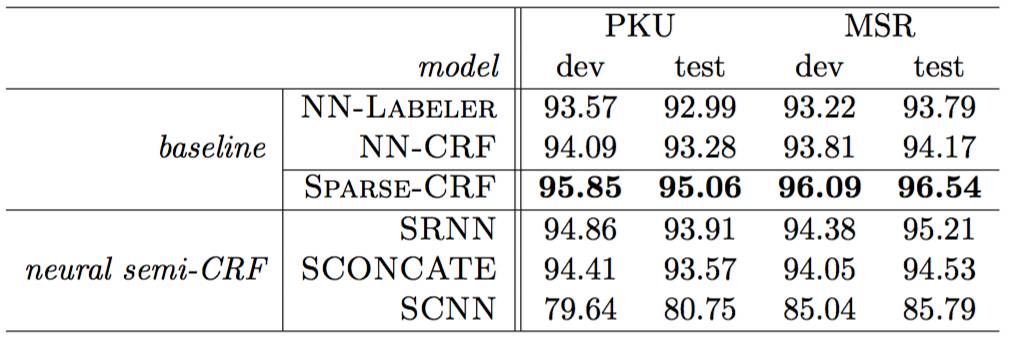
表1 其他组合网络在PKU和MSR数据集上的结果
虽然使用其他组合网络的初步尝试未取得理想结果,但这并不代表这一研究思路没有可行性。Zhuo等人在ACL2016发表的工作 Segment-Level Sequence Modeling using Gated Recursive Semi-Markov Conditional Random Fields[Zhuo et al.2016]亦是从组合网络的思路出发。但相较简单的拼接以及RNN,他们采用了更为复杂的Gated Recursive Network (如图2所示)对片段(亦即分词任务中的词)进行建模。在组块分析以及命名实体识别任务上的实验结果表明,这种表示方法能够非常有效地处理这两类切分问题。因而这一思路也值得中文分词借鉴。
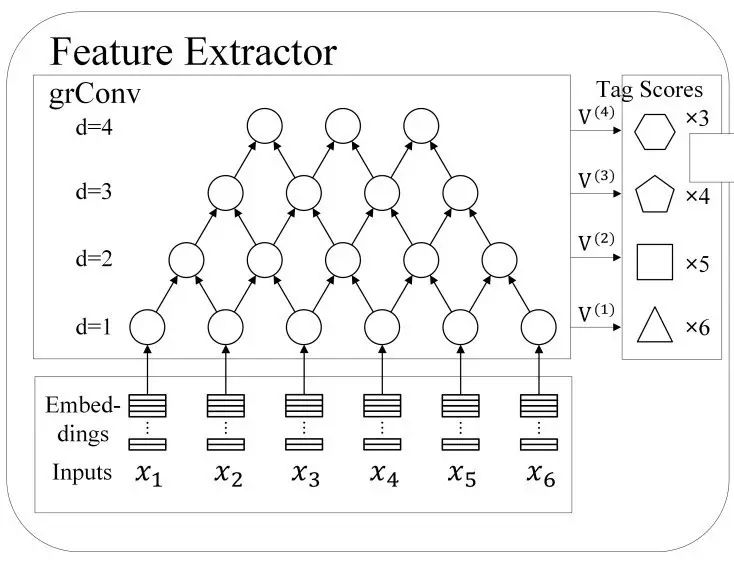
图2 Gated Recursive Network表示词片段的网络结构。举例来讲,对于长度为1的词,可以使用d=1的网络输出作为表示。
4 引入更丰富的词向量
在初步尝试使用其他组合网络失败的情况下,我们尝试另一种思路,即尝试在组合网络之外,给函数增加更丰富的信息。受到传统semi-CRF工作[Sarawagi and Cohen2004, Andrew2006]的启发,我们认为除了用网络组合词内的字序列,词的整体的表示也应该作为G的输入。在这一思路之下,我们将词向量作为G函数的输入。图3显示了我们的网络结构。其中,Seg-Rep from Input Units 部分代表SRNN,Seg-Rep from Segment 部分代表词向量。
读到这里,细心的读者会发出疑问“等等,中文分词不是获取词的过程吗,哪来的词向量?”在这项工作中,我们首先使用一个不依赖词向量的模型(SRNN或SCONCATE)对大规模文本进行切分,然后从自动切分结果中使用word2vec学习词向量。这种方法解决了词向量的获取问题。
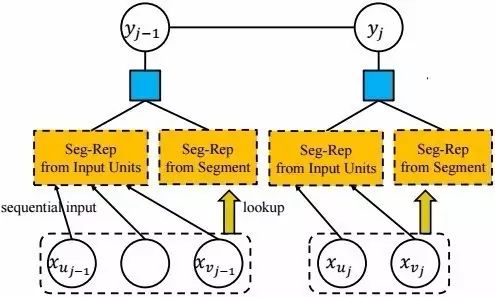
图3 我们的网络
我们的实验结果(表2)表明,引入词向量能够带来分词准确率的显著提升。在PKU和MSR数据集上,我们的模型均取得了好于前人工作的结果。
表2 Comparison with the state-of-the-art CWS systems
5 讨论
semi-CRF是使用基于词的方法进行分词的一种有效的方法,但并不是唯一的方法。除了semi-CRF,inexact search方法[Zhang and Clark2007]也可以实现基于词的分词。Zhang等人在ACL2016发表的工作 Transition-Based Neural Word Segmentation[Zhang et al.2016]尝试了在inexact search的框架下用神经网络表示词。同样取得了很高的分词准确率。
中文分词有多年的研究历史,在一些公开的数据集上已经取得了非常高的准确率。但中文分词仍具有很强的实践意义。首先,中文分词是自然语言切分问题的一个典型实例。中文分词的模型可以很容易地切换到命名实体识别,信息抽取等切分问题上。同时,中文分词仍存在模型泛化性、领域适应等问题。相信未来深度学习可以在这些问题上有所建树。
6 参考文献
[Andrew2006] Galen Andrew. A hybrid markov/semi-markov conditional random field for sequence segmentation. In Proc. of EMNLP-2006, pages 465—472, Sydney, Australia, July 2006. ACL.
[Kong et al.2015] Lingpeng Kong, Chris Dyer, and Noah A. Smith. Segmental recurrent neural networks. CoRR, abs/1511.06018, 2015.
[Pei et al.2014] Wenzhe Pei, Tao Ge, and Baobao Chang. Max-margin tensor neural network for chinese word segmentation. In Proc. of ACL-2014, pages 293—303, Baltimore, Maryland, June 2014. ACL.
[Sarawagi and Cohen2004] Sunita Sarawagi and William W. Cohen. Semi-markov conditional random fields for information extraction. In NIPS 17, pages 1185—1192. MIT Press, Cambridge, MA, 2004.
[Sun et al.2009] Xu Sun, Yaozhong Zhang, Takuya Matsuzaki, Yoshimasa Tsuruoka, and Jun’ichi Tsujii. A discriminative latent variable chinese segmenter with hybrid word/character information. In Proc. of NAACL-2009, pages 56—64, Boulder, Colorado, June 2009. ACL.
[Tseng2005] Huihsin Tseng. A conditional random field word segmenter. In In Fourth SIGHAN Workshop on Chinese Language Processing, 2005.
[Zhang and Clark2007] Yue Zhang and Stephen Clark. Chinese segmentation with a word-based perceptron algorithm. In ACL-2007, pages 840—847, Prague, Czech Republic, June 2007. ACL.
[Zhang et al.2016] Meishan Zhang, Yue Zhang, and Guohong Fu. Transition-based neural word segmentation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 421—431, Berlin, Germany, August 2016. Association for Computational Linguistics.
[Zheng et al.2013] Xiaoqing Zheng, Hanyang Chen, and Tianyu Xu. Deep learning for Chinese word segmentation and POS tagging. In Proc. of EMNLP-2013, pages 647—657, Seattle, Washington, USA, October 2013. ACL.
[Zhuo et al.2016] Jingwei Zhuo, Yong Cao, Jun Zhu, Bo Zhang, and Zaiqing Nie. Segment-level sequence modeling using gated recursive semi-markov conditional random fields. In ACL ‘16, pages 1413—1423, Berlin, Germany, August 2016. Association for Computational Linguistics.
本期责任编辑:郭江
本期编辑: 赵得志
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,郭江,赵森栋
编辑: 李家琦,施晓明,张文博,赵得志
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。
以上是关于赛尔原创 | 基于词的神经网络中文分词方法的主要内容,如果未能解决你的问题,请参考以下文章