学习深度解析中文分词器算法(最大正向/逆向匹配)
Posted PPV课数据科学社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习深度解析中文分词器算法(最大正向/逆向匹配)相关的知识,希望对你有一定的参考价值。
中文分词算法概述:
1:非基于词典的分词(人工智能领域)
相当于人工智能领域计算。一般用于机器学习,特定领域等方法,这种在特定领域的分词可以让计算机在现有的规则模型中,推理如何分词。在某个领域(垂直领域)分词精度较高。但是实现比较复杂。
例:比较流行的语义网:基于本体的语义检索。
大致实现:用protege工具构建一个本体(在哲学中也叫概念,在80年代开始被人工智能),通过jena的推理机制和实现方法。
实现对Ontology的语义检索。
Ontology语义检索这块自己和一朋友也还在琢磨,目前也只处于初级阶段。这一块有兴趣的朋友可以留言一起共享资源。
2:基于词典的分词(最为常见)
这类分词算法比较常见,比如正向/逆向匹配。例如: mmseg分词器 就是一种基于词典的分词算法。以最大正向匹配为主,多种 消除歧义算法为辅。但是不管怎么分。该类分词方法,分词精度不高。由于中文比较复杂,不推荐采用正向最大匹配算法的中文分词器。。逆向最大匹配算法在处理中文往往会比正向要准确。
接下来分析第2种:基于词典的分词算法(最长的词优先匹配)。 先分析最大正向匹配算法
一: 具体流程图如下:
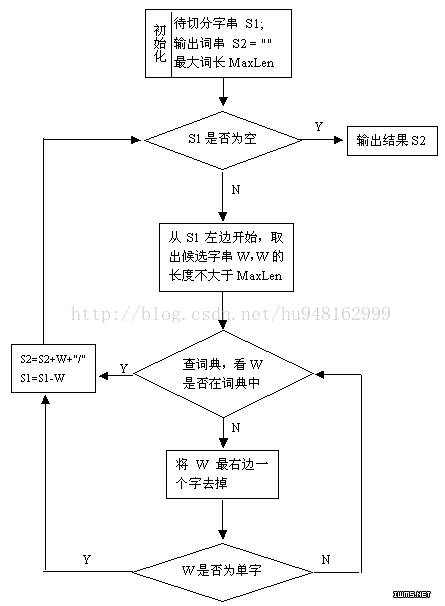
一:以下代码片段为最大正向匹配算法:
[html] view plaincopy
package hhc.forwardAlgorithm;
import java.net.URL;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.Stack;
/**
* @Description:
* @Date: 2015-2-7上午02:00:51
* @Author 胡慧超
* @Version 1.0
*/
@SuppressWarnings("unchecked")
public class TokenizerAlgorithm {
private static final List<String> DIC=new ArrayList<String>();
private static int MAX_LENGTH;
/**
* 把词库词典转化成dic对象,并解析词典信息
*/
static {
try {
System.out.println("开始初始化字典...");
int max=1;
int count=0;
//读取词典中的每一个词
URL url=TokenizerAlgorithm.class.getClassLoader().getResource("hhc/dic.txt");
Path path=Paths.get(url.toString().replaceAll("file:/", ""));
List<String> list=Files.readAllLines(path, Charset.forName("UTF-8"));
System.out.println("读取词典文件结束,词总数为:"+list.size());
for(String line:list){
DIC.add(line);
count++;
//获取词库中 ,最大长度的词的长度
if(line.length()>max){
max=line.length();
}
}
MAX_LENGTH=max;
System.out.println("初始化词典结束,最大分词长度为:"+max+" !!");
System.out.println("------------------------------------------------------------------------");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 正向分词算法
* @param text
* @return
*/
public static List forwardSeg(String text){
List result=new ArrayList();
while(text.length()>0){
int len=MAX_LENGTH;
if(text.length()<MAX_LENGTH){
len=text.length();
}
//取指定的最大长度 文本去字典中匹配
String tryWord=text.substring(0, len);
while(!DIC.contains(tryWord)){//如果词典中不包含该段文本
//如果长度为1 的话,且没有在字典中匹配,返回
if(tryWord.length()==1){
break;
}
//如果匹配不到,则长度减1,继续匹配
/**
* --这里就是最关键的地方,把最右边的词去掉一个,继续循环
*/
tryWord=tryWord.substring(0, tryWord.length()-1);
}
result.add(tryWord);
//移除该次tryWord,继续循环
text=text.substring(tryWord.length());
}
return result;
}
public static void main(String[] args) {
// TODO Auto-generated method stub
List<String> lst=new ArrayList();
lst.add("研究生命起源");
lst.add("食物和服装");
lst.add("乒乓球拍卖完了");
for(String str:lst){
List<String> list=forwardSeg(str);
String word="";
for(String s:list){
s+="/";
word+=s;
}
System.out.println(word);
}
}
执行正向分词结果:
二:最大逆向分词算法
考虑到逆向,为了 区分分词的数据的连贯性。我们采用Stack(栈对象,数据结果,后进先出,不同于Queue和ArrayList有顺序的先进先出) 这个对象来存储分词结果。。
[java] view plaincopy
/**
* 逆向分词算法
* @param text
* @return
*/
public static List reverseSeg(String text){
Stack<String> result=new Stack();
while(text.length()>0){
int len=MAX_LENGTH;
if(text.length()<MAX_LENGTH){
len=text.length();
}
//取指定的最大长度 文本去字典中匹配
String tryWord=text.substring(text.length()-len);
while(!DIC.contains(tryWord)){//如果词典中不包含该段文本
//如果长度为1 的话,且没有在字典中匹配,返回
if(tryWord.length()==1){
break;
}
//如果匹配不到,则长度减1,继续匹配
/**
* --这里就是最关键的地方,把最左边的词去掉一个,继续循环
*/
tryWord=tryWord.substring(1);
}
result.add(tryWord);
//移除该次tryWord,继续循环
text=text.substring(0,text.length()-tryWord.length());
}
int size=result.size();
List list =new ArrayList(size);
for(int i=0;i<size;i++){
list.add(result.pop());
}
return list;
}
执行逆向分词结果
以上代码实现了两种正向和逆向的算法,可以很明显的比较中文分词结果。
但是效率,,呵呵!确实不咋的。欢迎打脸。
比如:数据结构就先不提。text.substring(0, 0+len)会导致产生大量的新的字符串的产生,消耗CPU的同时还会促发垃圾回收频繁发生导致性能下降。随着最大长度的增加,性能会严重下降。
像之前介绍的采取正向最大匹配算法的mmseg分词器,内部设置了4个消除歧义的过滤算法,这四个歧义解析规则表明是相当有效率的。总体来讲。mmseg的分词精度还是值得推荐的。。。
PPV课其他精彩文章:
0、回复“活动”查看PPV课社区百日掘金活动-积分兑换Iphone 5s、MINI金条
1、回复“干货”查看干货 数据分析师完整知识结构
2、回复“答案”查看大数据Hadoop面试笔试题及答案
3、回复“设计”查看这是我见过最逆天的设计,令人惊叹叫绝
4、回复“可视化”查看数据可视化专题-数据可视化案例与工具
5、回复“禅师”查看当禅师遇到一位理科生,后来禅师疯了!!知识无极限
6、回复“啤酒”查看数据挖掘关联注明案例-啤酒喝尿布
7、回复“栋察”查看大数据栋察——大数据时代的历史机遇连载
8、回复“数据咖”查看数据咖——PPV课数据爱好者俱乐部省分会会长招募
9、回复“每日一课”查看【每日一课】手机在线视频集锦
以上是关于学习深度解析中文分词器算法(最大正向/逆向匹配)的主要内容,如果未能解决你的问题,请参考以下文章