达观数据告诉你机器如何理解语言——中文分词技术
Posted 大数据实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了达观数据告诉你机器如何理解语言——中文分词技术相关的知识,希望对你有一定的参考价值。
一、 分词算法分类
中文分词算法大概分为三大类,第一类是基于字符串匹配,即扫描字符串,如果发现字符串的子串和词典中的词相同,就算匹配,比如机械分词方法。这类分词通常会加入一些启发式规则,比如“正向/反向最大匹配”,“长词优先”等。第二类是基于统计以及机器学习的分词方法,它们基于人工标注的词性和统计特征,对中文进行建模,即根据观测到的数据(标注好的语料)对模型参数进行训练,在分词阶段再通过模型计算各种分词出现的概率,将概率最大的分词结果作为最终结果。常见的序列标注模型有HMM和CRF。这类分词算法能很好处理歧义和未登录词问题,效果比前一类效果好,但是需要大量的人工标注数据,以及较慢的分词速度。第三类是通过让计算机模拟人对句子的理解,达到识别词的效果,由于汉语语义的复杂性,难以将各种语言信息组织成机器能够识别的形式,目前这种分词系统还处于试验阶段。
二、 机械分词算法
机械分词方法又叫基于字符串匹配的分词方法,它是按照一定的策略将待分析的字符串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。这是最简单的分词方法,但非常高效和常见。(达观数据 江永青)
(1) 匹配方法
机械分词方法按照扫描方向的不同,可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配;常用的几种机械分词方法如下:
正向最大匹配法(由左到右的方向);如以例句“达观数据是一家大数据公司”,使用正向最大匹配法分词的结果为“达观/数据/是一/家/大数据/公司”
逆向最大匹配法(由右到左的方向);同样以例句“达观数据是一家大数据公司”,使用逆向最大匹配法分词的结果为“达观/数据/是/一家/大数据/公司”
最少切分(使每一句中切出的词数最小)。例句“达观数据是一家大数据公司”被分为“达观数据/是/一家/大数据公司”。
(2) 消除歧义
因为同一个句子,在机械分词中经常会出现多种分词的组合,因此需要进行歧义消除,来得到最优的分词结果。
以很常见的MMSEG机械分词算法为例,MMSEG在搜索引擎Solr中经常使用到,是一种非常可靠高效的分词算法。MMSEG消除歧义的规则有四个,它在使用中依次用这四个规则进行过滤,直到只有一种结果或者第四个规则使用完毕。这个四个规则分别是:
最大匹配,选择“词组长度最大的”那个词组,然后选择这个词组的第一个词,作为切分出的第一个词,如对于“中国人民万岁”,匹配结果分别为:
中/国/人
中国/人/民
中国/人民/万岁
中国人/民/万岁
在这个例子“词组长度最长的”词组为后两个,因此选择了“中国人/民/万岁”中的“中国人”,或者“中国/人民/万岁”中的“中国”。
最大平均词语长度。经过规则1过滤后,如果剩余的词组超过1个,那就选择平均词语长度最大的那个(平均词长=词组总字数/词语数量)。比如“生活水平”,可能得到如下词组:
生/活水/平 (4/3=1.33)
生活/水/平 (4/3=1.33)
生活/水平 (4/2=2)
根据此规则,就可以确定选择“生活/水平”这个词组
词语长度的最小变化率,这个变化率一般可以由标准差来决定。比如对于“中国人民万岁”这个短语,可以计算:
中国/人民/万岁(标准差=sqrt(((2-2)^2+(2-2)^2+(2-2^2))/3)=0)
中国人/民/万岁(标准差=sqrt(((2-3)^2+(2-1)^2+(2-2)^2)/3)=0.8165)
于是选择“中国/人民/万岁”这个词组。
计算词组中的所有单字词词频的自然对数,然后将得到的值相加,取总和最大的词组。比如:
设施/和服/务
设施/和/服务
这两个词组中分别有“务”和“和”这两个单字词,假设“务”作为单字词时候的频率是5,“和”作为单字词时候的频率是10,对5和10取自然对数,然后取最大值者,所以取“和”字所在的词组,即“设施/和/服务”。
(3) 机械分词的缺陷
机械分词方法是一种很简单高效的分词方法,它的速度很快,都是O(n)的时间复杂度,效果也可以。但缺点是对歧义和新词的处理不是很好,对词典中未出现的词没法进行处理,因此经常需要其他分词方法进行协作。
三、 基于n元语法的分词算法
(1) 概念
基于词的n元语法模型是一个典型的生成式模型,早期很多统计分词均以它为基本模型,然后配合其他未登录词识别模块进行扩展。其基本思想是:首先根据词典(可以是从训练语料中抽取出来的词典,也可以是外部词典)对句子进行简单匹配,找出所有可能的词典词,然后,将它们和所有单个字作为结点,构造的n元切分词图,图中的结点表示可能的词候选,边表示路径,边上的n元概率表示代价,最后利用相关搜索算法(动态规划)从图中找到代价最小的路径作为最后的分词结果。
图1:n元语法分词算法图解
(2) 求解方法
假设随机变量S为一个汉字序列,W是S上所有可能切分出来的词序列,分词过程应该是

这里的P(结合|start)、P(成分|结合)、P(子|成分)、P(end|子) 都是通过大量的语料统计得出,因此可以通过概率相乘来判断哪一个分词序列更好。在例图中,可以通过动态归划的算法算出最后最优的分词序列。
n元语法的分词方法是基于统计的分词算法,它比简单的机械分词算法精度更高,但算法基于现有的词典,因此很难进行新词发现处理。
四、 基于隐马尔可夫模型的分词算法
(1) 隐马尔可夫模型
隐马尔可夫模型(Hidden Markov Model,简称HMM)是结构最简单的动态贝叶斯网络(dynamic Bayesian network),这是一种尤其著名的有向图模型,主要用于时序数据建模,在语音识别、自然语言处理等领域有广泛应用。在分词算法中,隐马尔可夫经常用作能够发现新词的算法,通过海量的数据学习,能够将人名、地名、互联网上的新词等一一识别出来,具有广泛的应用场景。(达观数据 江永青)
隐马尔可夫模型是马尔可夫链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。如图所示,隐马尔可夫模型中的变量可分为两组。第一组是状态变量{y1, y2, …, yn},其中yi表示第i时刻的系统状态。通常假定状态变量是隐藏的、不可被观测的,因此状态变量亦称隐变量。第二组是观测变量{x1, x2, …, xn},其中xi表示第i时刻的观测值。在隐马尔可夫模型中,系统通常在多个状态之间转换,因此状态变量yi的取值范围通常是有N个可能取值的离散空间。
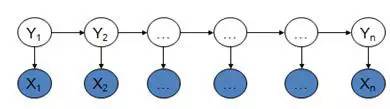
图2:隐马尔可夫模型图解
图中的箭头表示了变量间的依赖关系。在任一时刻,观测变量的取值仅依赖于状态变量,即xi由yi决定,与其他状态变量及观测变量的取值无关。同时,i时刻的状态yi仅依赖于i-1时刻的状态yi-1,与其余n-2个状态无关。这就是所谓的“马尔可夫链”,即:系统下一时刻的状态仅由当前状态决定,不依赖于以往的任何状态。
(2) 隐马尔可夫的求解
一般的,一个HMM可以记作一个五元组u=(S, K, A, B, π), 其中S是状态集合,K是输出符号也就是观察集合,A是状态转移概率,B是符号发射概率,π是初始状态的概率分布。HMM主要解决三个基本问题:
估计问题,给定一个观察序列O=O1,O2,O3,… ,Ot和模型u=(A,B,π),计算观察序列的概率;
序列问题,给定一个观察序列O=O1,O2,O3… Ot和模型μ=(A, B,π),计算最优的状态序列Q=q1,q2,q3…qt;
参数估计问题,给定一个观察序列O=O1,O2,O3… Ot,如何调节模型μ=(A,B,π)的参数,使得P(O|μ)最大。
隐马尔可夫的估计问题可以通过前向/后向的动态规划算法来求解;序列问题可以通过viterbi算法求解;参数估计问题可以通过EM算法求解。通过海量的语料数据,可以方便快速地学习出HMM图模型。
(3) HMM分词方法
隐马尔可夫的三大问题分别对应了分词中的几个步骤。参数估计问题即是分词的学习阶段,通过海量的语料数据来学习归纳出分词模型的各个参数。状态序列问题是分词的执行阶段,通过观察变量(即待分词句子的序列)来预测出最优的状态序列(分词结构)。
我们设定状态值集合S =(B, M, E, S),分别代表每个状态代表的是该字在词语中的位置,B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词;观察值集合K =(所有的汉字);则中文分词的问题就是通过观察序列来预测出最优的状态序列。
比如观察序列为:
O = 小红就职于达观数据
预测的状态序列为:
Q = BEBESBMME
根据这个状态序列我们可以进行切词:
BE/BE/S/BMME/
所以切词结果如下:
小红/就职/于/达观数据/
因为HMM分词算法是基于字的状态(BEMS)来进行分词的,因此很适合用于新词发现,某一个新词只要标记为如“BMME”,就算它没有在历史词典中出现过,HMM分词算法也能将它识别出来。
五、 基于条件随机场的分词算法
(1) 条件随机场模型
条件随机场(Conditional Random Field,简称CRF)是一种判别式无向图模型,它是随机场的一种,常用于标注或分析序列语料,如自然语言文字或是生物序列。跟隐马尔可夫模型通过联合分布进行建模不同,条件随机场试图对多个变量在给定观测值后的条件概率进行建模。(达观数据 江永青)
具体来说,若令x = {x1, x2, …, xn}为观测序列,y = {y1, y2, …, yn}为与之对应的标记序列,则条件随机场的目标是构建条件概率模型P(y | x)。令图G = <V, E>表示结点与标记变量y中元素一一对应的无向图,yv表示与结点v对应的标记变量,n(v)表示结点v的邻接结点,如果图G的每个变量yv都满足马尔可夫性,即:
则(y, x)构成一个条件随机场。也就是说,条件概率只与x和y的邻接结点有关,与其他的y结点没有关系。
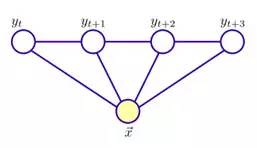
图3:条件随机场模型图解
理论上来说,图G可具有任意结构,只要能表示标记变量之间的条件独立性关系即可。但在现实应用中,尤其是对标记序列建模时,最常用的仍然是上图所示的链式结构,即“链式条件随机场”。


(3) 条件随机场分词方法
条件随机场和隐马尔可夫一样,也是使用BMES四个状态位来进行分词。以如下句子为例:
中 国 是 泱 泱 大 国
B B B B B B B
M M M M M M M
E E E E E E E
S S S S S S S
条件随机场解码就是在以上由标记组成的数组中搜索一条最优的路径。
我们要把每一个字(即观察变量)对应的每一个状态BMES(即标记变量)的概率都求出来。例如对于观察变量“国”,当前标记变量为E,前一个观察变量为“中”,前一个标记变量为B,则:
t(B, E, ‘国’) 对应到条件随机场里相邻标记变量{yi-1, yi}的势函数:
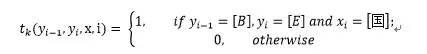


量化对冲实战培训班(八期)登录广州,报名进行中!
上课地点:广州
培训时间:2016年7月8--9日

六、 达观数据分词算法应用
达观数据是一家新兴高科技大数据公司,创始人来自腾讯、百度、盛大、搜狗等知名企业,具有非常深厚的技术实力。在分词技术领域,达观数据借鉴国内外优秀的项目,升级了不少分词算法,并积累了大量的分词词典。此外,达观文本挖掘融合了全套自然语言处理技术和机器学习技术,在分词基础文字处理功能上集成了词性标注、句法分析、命名实体识别、文本标签提取等功能模块,基于此再结合SVM、GBRT、logistic regression等机器学习算法,实现认知层次上的文本自动分类、涉黄涉政分析、垃圾评论识别等功能。
总结
本文介绍了常见的几种分词算法及其原理,分析了它们对应的优缺点。应用在文本挖掘、搜索引擎等领域,需要根据不同场景,使用不同的分词算法及词典,才能最有效地达到准确分词的效果。
江永青,浙江大学软件工程专业硕士,曾在盛大创新院负责搜索引擎的索引和检索模块,在盛大文学数据中心负责大数据分布式系统、搜索引擎架构、搜索行为分析。现任达观数据联合创始人,对搜索引擎、数据挖掘和大数据技术有丰富的经验和较深入的理解。
来源:36大数据
本文连接http://www.36dsj.com/archives/52930
传说中的股票日内交易培训班(第二期)
2016年7月30—8月2日 上海
神奇的资金曲线,普通交易员,经过训练就可以做到
魔鬼与天使都在细节中,非长期总结提炼,无法达到尽善尽美
交易成功率比期货日内交易高出不止10倍
以前只在传说中听过的股票日内交易,而今呈上无遗
以上是关于达观数据告诉你机器如何理解语言——中文分词技术的主要内容,如果未能解决你的问题,请参考以下文章