世上本来没有词,只是用的人多了才成为词,谈中文分词的思想。
Posted 互联网大数据处理技术与应用
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了世上本来没有词,只是用的人多了才成为词,谈中文分词的思想。相关的知识,希望对你有一定的参考价值。
互联网的各类应用中存在大量的中文文本,是大数据中典型的非结构化数据。正确处理这些文本是进行大数据挖掘的前提,中文分词则是大部分处理过程的基础。看似简单的中文分词,由于自然语言表达的灵活性,使得中文分词存在很大的挑战。这些挑战主要来自以下若干方面:
一是,新词广泛存在。特别是互联网大数据的应用场景中,新词包括全新的词汇(如蓝瘦、照骗等口语,以及河长等领域术语)、旧词新用(如爸爸、香菇等等)。
二是,歧义现象普遍。比如,“校园外出现一种新游戏”这句话的“外出”和“出现”,“我马上就来”中的“马上”。
三是,多义词、同义词很多,需要一定的上下文才能正确判断。
四是,存在很多人名、地名、机构名等,需要在分词的过程中一起识别。
上述问题的根本原因之一是什么是一个词以及如何在上下文中判断词汇。围绕这个根本问题,不同的分词方法运用了不同的思想。
1. 定义一个词典,只要放入到该词典的字符串就会被认为是一个词。
2. 世上本来没有词,只是用的人多了才成为词(我改造了鲁迅先生的话)。则是从使用的角度来定义词汇。
3. 每个字用作词汇的开始、结束或中间是有一定规律的,这是从构词的角度出发。
针对这三种朴素的思想,分别进化出三类分词方法,分别是基于词典的分词方法、基于统计模型的优选方法和基于统计模型的序列标注方法。
基于词典的方法
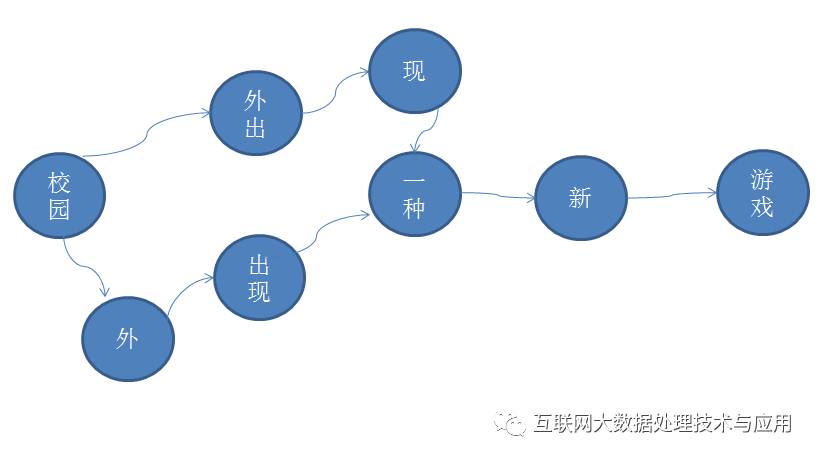
基于词典的分词方法是进行字符串匹配的方法,将一串文本中的文字片段和词典中的字符串进行匹配,如果能匹配到,则切出一个词汇。相应的有正向最大匹配,逆向最大匹配等实现方案。但可能存在切分的歧义,例如,“校园外出现一种新游戏”采用正向、逆向可以得到“校园\外出\现\一种\新\游戏”、“校园\外\出现\一种\新\游戏”。
基于统计模型的优选方法
对于上述的例子,构造如图的路径图,需要计算从第一个词汇到最后一个词汇的所有路径的最优值。这种最优值可以是基于n-gram的计算方法,但要考虑到训练语料的规模、n的选择、稀疏性等问题。
基于统计模型的序列标注方法
这种方法一般定义四个标签,即:B(Begin)表示这个字是一个词的首字;M(Middle)表示这是一个词中间的字;E(End)表示这是一个词的尾字;S(Single)表示这是单字成词。
分词的过程就是将一段中文字符进行运算得到相应的标记序列,再根据标记序列进行分词。例如“复旦大学是一所高等院校”对应的标记序列是BMMESBEBEBE,从而得到“复旦大学\是\一所\高等\院校”的切分结果。这也是目前分词方法研究的前沿技术。广泛采用HMM、CRF和深度神经网络RNN、LSTM等。
采用HMM模型,则模型示意如图,隐状态是BMES,每个隐状态之间存在概率转移,给定某个隐状态,存在一个在C上的输出分布(C就就所有的字)。这些模型参数的学习是从大规模语料中计算得到,这样,使用HMM理论的Viterbi算法,即可得到输入序列对应的最佳隐状态序列,即标签序列。
基于深度学习的分词方法是当前的热点,它将一个句子中的每个字标记成BEMS四种标签。模型的输入是字符序列,输出是一个标注序列,是一个标准的sequenceto sequence问题。深度神经网络可以自动发现特征,减少了特征工程的工作量。
以上是关于世上本来没有词,只是用的人多了才成为词,谈中文分词的思想。的主要内容,如果未能解决你的问题,请参考以下文章