新颖的中文分词器(基于词典与原始文本)
Posted AIChangeLife
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新颖的中文分词器(基于词典与原始文本)相关的知识,希望对你有一定的参考价值。
原文链接:
http://aclweb.org/anthology/C/C12/C12-2080.pdf
转载必须注明作者和原文链接,必须通过公众联系作者,经过作者同意
Meng FanDong Jiang Wenbin Xiong Hao LiuQun
中国科学院计算技术研究所智能信息处理重点实验室
{mengfandong, jiangwenbin, xionghao, liuqun}@ict.ac.cn
[?]符号表示有参考资料
概论:
中文分词(Chinese word segmentation,CWS)是中文信息处理中一个基本,重要的任务。
标准的中文分词处理方式是对输入文字序列进行特征标注,但如果没有精确的手工标注过的语料(以专用格式排列,标注文字特征的文本),是无法生成高精确度的处理模型的。
另一种常用的方式是使用词典进行最大匹配(Dictionary maximum matching, DMM),但对于词典外的词汇识别精度很低。
我们设计了一种新颖的方式利用词典和原始文本,建立了在实践中更有效的模型(输入数据只需要词典与原始文本)。
与词典法相比,在新闻,中国医学专利文献处理中,错误相对分别减少21.50%和13.66%,并且对未知词(out-of-vocabulary,OOV)识别率(recall rate查全率)分别为42.54%,23.72%。
介绍:
已有中文文本分词主要方法:
a) 对文字序列进行标注(Most effective approaches to CWS treat it as a character tagging task):
通过将判别标注的精确度表示为最大熵值(Maximum Entropy, ME),条件随机场(Conditional Random Fields, CRF 一种基于条件概率的模型[?])或多层前馈神经网络等方法进行训练。
可以实现比较好的识别精确度,但依赖于大量,高精确度标注的语料做训练数据,对于一些专业领域或小众语言是很难实现的。
b) 通过词典,进行最大匹配,可以应用在没有语料库的情况,但未知词汇识别精确度过低。
我们的方案:
优点:
只需要专业术语词典和原始文本做输入,就可以生成高质量的分词器
1. 通过匹配策略,检查输入原始文本中每个句子中连续的字符序列与词典的匹配情况。对找到的匹配词,把字符序列表示为一个特征码,构造一个特征码集合。
2. 对特征码使用最大熵算法训练一个分类器。
图示:
对 Penn Chinese Treebank5.0(知名开放语料库,CTB)和中文医学专利文献(Chinese medicine patent, CMP)进行测试结果:
1. 使用对CTB训练出的分类器处理CMP,精确度次于使用CMP专用词典的DMM方案。
2. 使用CTB与CMP专用词典分别训练出的分类器,精确度相比DMM方案分别提高了21.50%和13.66%,并且对未知词(out-of-vocabulary,OOV)识别率(recall rate查全率)分别为42.54%,23.72%。
对字符间隙的作用进行标注:
中文的句子可以表示为字符序列:
C1:n = C1C2···Cn,其中Ci(i = 1,···,n)是一个字符。
中字符Ci与Ci+1的间隙中加入Gi(i = 1,···,n−1)符号,结果序列为:
C1:n|G1:n−1 = C1G1C2G2···Gn−1Cn,
最后的分词结果将表示为:
C1:e1|G1:e1−1, Ge1, Ce1+1:e2|Ge1+1:e2−1, Ge2,···, Gem−1, Cem−1+1:em|Gem−1+1:em−1
其中Ci:j|Gi:j−1表示具有Gi:j−1间隙符序列的字符-间隙符序列,如上表示,间隙符分为2类:
1. 在词之中(G1···Ge1−1)
2. 在词之间(Ge1)
这样分词过程就可以表达成对间隙符进行标注的方式
标注的方式:
注:原文与以前的标注方法(Ng and Low (2004)进行了对比,为了方便,直接理解方案的含义,没有加入。
1. 标注Gi−1Gi 为"AA"表示Ci在词中间
2. 标注Gi−1Gi 为"AS"表示Ci在词结尾
3. 标注Gi−1Gi 为"SA"表示Ci在词开始
4. 标注Gi−1Gi 为"SS"表示Ci是一个单独的词
N元(N-Gram )马尔可夫间隙符标注方法:
当一次处理N+1个间隙符时,可能的决策数为: 2^N+1,对应的集合为{A,S}(*)N+1 ({A,S}是间隙符集合,(*)是笛卡尔乘积),序列Gi−N:i将会从Gi 以N-Gram 马尔可夫链算法进行标注。那对于输入字符间隙符序列x = C1:n|G1:n−1,目标是找到:
F(x)= argmax Score(x, y)
y∈{A,S}(*)n−1
Score(x,y)是分类器对标注后序列的评分:
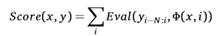
Φ(x,i)表示字符间隙输入序列中Gi位置的间隙符(表示为特征码),Eval函数基于Φ(x,i)对马尔可夫链预测的间隙标注序列评分。
实际的训练算法,使用动态规划算法,利用最大熵值(表达概率分布特征[?])来找到最优评分标注序列。为平衡精确度和速度,我们使用2元(2-gram, N=2)。
间隙符的特征码通过间隙两边的字符表示,对于间隙符G0,左侧第i个字符是C1−i,右侧第i个字符是Ci,示例:
对于"美国商务部”这句话中”商”和”务”的间隙符,它的1元,2元特征码是:
![]()
基于词典的特征值抽取:
基于标注准确的语料库,匹配度优化的中文分词器的训练分为2步:
1.抽取特征值
2.使用特征值训练评分模型
基于字典匹配算法的特征值抽取方法:
1. 词典匹配算法
2. 特征值的序列(字符序列或间隙序列)标注策略
1. 词典典双向最大匹配算法:
注意:
a) 词典中不包括时间,数字,英文,将通过规则动态识别
b) 词典中不包括单字的词:
i. 单字词使用方法非常灵活,通常会和其它字组成一个多字词。
ii. 词典的大小规模是有限的,有很多没有包含的多字词,如果它们之中的单字被识别为单词,将会产生很高的错误率。(注意:单字词匹配必须优先级最低,否则会与多字词的靠前的单字匹配为词)
为了最小化词典与原始文本匹配过程可能出现的多义性冲突,进行前向最大匹配(forward maximum matching, FMM)和后向最大匹配(backward maximum matching, BMM),分别生成前向匹配集,后向匹配集,然后保留两个集的交集:
a) 对输入语料库中的一句话S = C1:N (Cq(q = 1,···,N)表示字符),前向(FMM),后向(BMM)对 Ci:k子字符序列与词典匹配,如果完全匹配,那么Ci:k与词典中的词Wj完全匹配,将Ci:k和它之前(preceding-text),之后(following-text)的n个字符(表示这个词使用的上下文)转换为一个文本节P(结构:前向n个字符+Ci:k+后向n个字符)
2. 多字词的识别:
注意:只抽取多字词进行特征。
对于抽取出来的文本节P,以3种方式从间隙符中摄取特征:
a) 前n个字符(preceding-text)最后1个字与Ci:k第1个字之间的间隙符
b) Ci:k中字之间的间隙符
c) Ci:k最后1个字与后n个字符(following-text)第1个字与之间的间隙符

当词典中包括”美国,商务部,商务,部长,访问,上海”这些词时FMM与BMM分别对”美国商务部长访问上海”这句话匹配后的结果
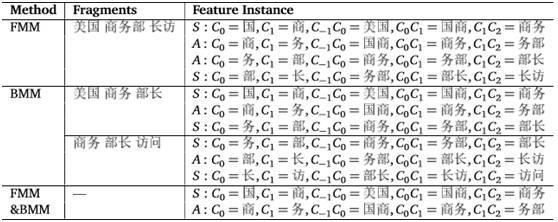
间隙符定义:
“S”表示分割("split”)
“A”表示邻接("adjoin”)
“—“表示未定义
上表分别是FMM,BMM对”美国商务部长访问上海”这句话的匹配序列的间隙符标注结果,和两者序列交集的间隙符标注结果。注意对“商务部长”FMM,BMM产生不同匹配序列。
对于FMM,BMM的分类结果很难评判好坏,所以分别对它们进行了标注,然后抽取2者的交集。
对”美国商务部长访问上海”,只有”商,务,部,长”4个字的分词结果不同,分别是”商务部 长”和”商务 部长”:
两者交集将是”商务”(根据上表最后一行标注序列)
![]()
之后处理"部长",因为只有BMM能处理,所以采用BMM方式处理。(其实就是FMM, BMM哪个匹配相对短(>2)的词用哪个)
对词内字进行准确标注后,就可以文本节P进行了完整的标注。
3. 单字词识别:
单字词是时常会使用到的,所以对单字词的识别将强化模型的处理能力,我们使用简单的策略来识别单字词:
如果一个字Ci的左侧是在词典中的词,或时间词,数字,英文,或句子的开始,结束,那我们将Ci识别为一个单字词,然后再回到上面的策略进行标注。
测试结果:
准备工作:
1. 新闻类文本,使用Penn Chinese Treebank 5.0语料库(CTB)。词典从1-270章节(1.8万条句子)抽取了33500个词。
CTB原来包括1000万条句子,为了减少与CMP差别,分为小数据集(2百万条句子),大数据集(1000万条句子)
2. 医疗专利资料,字典包括21800个单词(内部资料),包括了相关的专业术语,由于它不包括常用词,所以我们结合了CTB词典,构成更大的CTB+CMP词典(55100个词,去重后),原始语料库包括大约200万条句子,其中的300条单独抽取出来进行测试。
使用Zhang开发的最大熵工具来训练我们的模型,主要配置如下:
(参考homepages.inf.ed.ac.uk/lzhang10/maxent_toolkit.html)
1. epoch: 150
2. 高斯先验值: 3.0
3. 总精确度评估公式:2PB/(P+R) P表示与测试数据比较的精确度,R表示对于未知词与标准语言语法比较的精确度。
基于词典和文本匹配度模型的训练结果:
首先使用手动定制的规则辨别时间,数字,英文,之后使用分类器处理其余部分。
直接字符标注法与间隙符标注法对比:
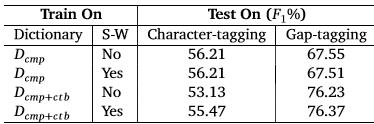
SW表示是否识别单字词
相对直接字符标注法,间隙符标注法具有更高精确度(每行的最后两格,平均增加16.66%),虽然识别单字词小幅提高直接字符标注法(53.13到55.47),间隙符标注法(76.23 到76.37)的精确度,但并不弥补接字符标注法较高的错误率,所以间隙符标注法是更好的选择。
DMM与间隙符标注法(包含单字词识别)对比:
1. 使用前向匹配(FMM)基于CTB词典,处理CTB测试数据集精确度为91.05%
2. 使用后向匹配(BMM)基于CTB词典,处理CTB测试数据集精确度为91.44%
3. 使用前向匹配(FMM)基于CTB+CMP词典,处理CMP测试数据集精确度为72.30%
4. 使用后向匹配(BMM)基于CTB+CMP词典,处理CMP测试数据集精确度为72.63%
(BMM相对FMM在CTB和CMP上有更好的精确度)
5. 使用我们的模型,基于CTB小数据集,相对BMM提升了1.54%(91.44到92.98)精确度
使用我们的模型,基于CTB大数据集(1000万条句子)提升了更多的0.3%精度(93.28%)(相较于BMM错误率减少21.50%(错误率=1-正确率))
6. 使用我们的模型,只使用CMP词典,对CMP测试数据集测试,精确度为67.51%,相较BMM和FMM低,因为CMP词典中的通用词太少。
7. 使用我们的模型,CTB+CMP词典,对CMP测试数据集测试,精确度为76.37%,相较BMM和FMM更高。
对未知词的测试:
对时间,数字,英文字符不进行测试,由规则处理。
对单字词不支持,不进行测试。
使用DMM方法测试准确度为0%
使用我们的模型,CTB数据集的精确度为42.54%
使用我们的模型,CMP数据集的精确度为23.72%
如果没有标注语料库,
我们的模型精确度更好。
其余部分与模型实现关联不大,可以查看原文。
参考文献:
Maximum Entropy:
https://en.wikipedia.org/wiki/Maximum_entropy
References Collins, M. (2002). Discriminative training methods for hidden markov models: Theory and experiments with perceptron algorithms. In Proceedings of theACL-02 conference on Empirical
7The dictionaries used in this paper are available resources. To our knowledge, we can produce a dictionary for a novel domain/language from Wikipedia or Baidupedia (Chinese).methods in natural language processing-Volume 10, pages 1–8. Association for Computational Linguistics.
Collins, M. and Roark, B. (2004). Incremental parsing with the perceptron algorithm. In Proceedings of ACL, volume 2004.
Hewlett, D. and Cohen, P. (2011). Fully unsupervised word segmentation with bve and mdl. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: short papers-Volume 2, pages 540–545. Association for Computational Linguistics.
Jiang, W., Huang, L., and Liu, Q. (2009). Automatic adaptation of annotation standards: Chinese word segmentation and pos tagging: a case study. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 1-Volume 1, pages 522–530. Association for Computational Linguistics.
Jiang, W., Meng, F., Liu, Q., and Lü, Y. (2012). Iterative annotation transformation with predict-self reestimation for chinese word segmentation. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pages 412–420.
Johnson, M. and Goldwater, S. (2009). Improving nonparameteric bayesian inference: experiments on unsupervised word segmentation with adaptor grammars. In Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, pages 317–325. Association for Computational Linguistics.
Kruengkrai, C., Uchimoto, K., Kazama, J., Wang, Y., Torisawa, K., and Isahara, H. (2009). An error-driven word-character hybrid model for joint chinese word segmentation and pos tagging. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 1-Volume 1, pages 513–521. Association for Computational Linguistics.
Lafferty, J., McCallum, A., and Pereira, F. (2001). Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th ICML, pages 282–289.
Li, Z. (2011). Parsing the internal structure of words: a new paradigm for chinese word segmentation. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Portland, Oregon, USA: Association for Computational Linguistics.
Li,Z.andSun, M.(2009). Punctuationasimplicit annotations forchinesewordsegmentation. Computational Linguistics, 35(4):505–512.
Mochihashi, D., Yamada, T., and Ueda, N. (2009). Bayesian unsupervised word segmentation with nested pitman-yor language modeling. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 1-Volume 1, pages 100–108. Association for Computational Linguistics.
Ng, H. and Low, J. (2004). Chinese part-of-speech tagging: One-at-a-time or all-at-once? word-based or character-based. In Proceedings of EMNLP, volume 4.
Peng, F. and Schuurmans, D. (2001). Self-supervised chinese word segmentation. Advances in Intelligent Data Analysis, pages 238–247.
Ratnaparkhi and Adwait (1996). A maximum entropy model for part-of-speech tagging. In Proceedings of the conference on empirical methods in natural language processing, volume 1, pages 133–142.
Sun, W. (2011). A stacked sub-word model for joint chinese word segmentation and part-ofspeechtagging. InProceedings of the49thAnnual Meetingof theAssociation for Computational Linguistics, pages 1385–1394.
Sun, X., Wang, H., and Li, W. (2012). Fast online training with frequency-adaptive learning rates for chinese word segmentation and new word detection. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, pages 253–262.
Wang, H., Zhu, J., Tang, S., and Fan, X. (2011). A new unsupervised approach to word segmentation. Computational Linguistics, 37(3):421–454.
Wang, K., Zong, C., and Su, K. (2010). A character-based joint model for chinese word segmentation. InProceedingsofthe23rdInternationalConferenceonComputationalLinguistics, pages 1173–1181. Association for Computational Linguistics.
Xue, N. and Shen, L. (2003). Chinese word segmentation as lmr tagging. In Proceedings of the second SIGHAN workshop on Chinese language processing-Volume 17, pages 176–179. Association for Computational Linguistics.
Xue,N.,Xia,F.,Chiou,F.,andPalmer, M.(2005). Thepennchinesetreebank: Phrasestructure annotation of a large corpus. Natural Language Engineering, 11(02):207–238.
Zhang, Y. and Clark, S. (2007). Chinese segmentation with a word-based perceptron algorithm. In Anual Meeting-Association for Computational Linguistics, volume 45, page 840.
Zhang, Y. and Clark, S. (2008). Joint word segmentation and pos tagging using a single perceptron. In Proceedings of ACL, volume 8, pages 888–896.
Zhang,Y.andClark, S.(2010). Afastdecoderforjointwordsegmentationandpos-taggingusing a single discriminative model. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, pages 843–852. Association for Computational Linguistics.
以上是关于新颖的中文分词器(基于词典与原始文本)的主要内容,如果未能解决你的问题,请参考以下文章