结合中文分词和正则识别语句中的结构化数据或短语
Posted Sumslack团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了结合中文分词和正则识别语句中的结构化数据或短语相关的知识,希望对你有一定的参考价值。
项目背景
11)兴业一个月4.35 三个月4.35 六个月4.4 九个月4.45 一年4.45
29个月 4.60%
预期分词效果:
能有效识别的结构数据包括期限和价格
设计思路
针对所有的样本数据进行词性标注,交由HanLP学习,也可以采用正则表达式提炼,利用责任链模式进行逐层特定短语的提炼,本文先介绍简单的后者实现方法,步骤如下:
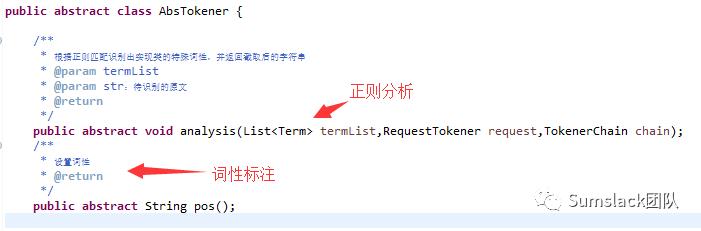
特殊词性定义,如期限,价格,评级等;
-
编写一个抽象类,用来定义各个短语正则实现类的定义;
-
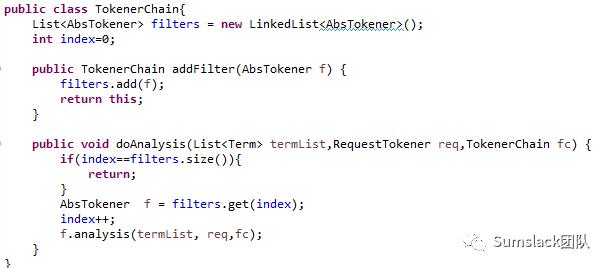
责任链实现;
-
为了查询方便,规整同一类词性到固定格式,如期限,将3个月规整为3M等;
HanLP词性定义代码如下:

定义抽象类:
责任链设计模式:
执行代码:
你可能还对以下文章感兴趣:
以上是关于结合中文分词和正则识别语句中的结构化数据或短语的主要内容,如果未能解决你的问题,请参考以下文章
Java日期时间API系列40-----中文语句中的时间语义识别(time NLP)代码实现分析
Handlp 分词加词典关键字提取摘要短语提取依法依据分析(含代码直接运行即可)
《从Lucene到Elasticsearch:全文检索实战》学习笔记二
ES中文分词器之精确短语匹配(解决了match_phrase匹配不全的问题)