揭秘中文分词算法三大流派 海量分词5.0免费版应用了哪些算法?
Posted 海量智能计算研究中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了揭秘中文分词算法三大流派 海量分词5.0免费版应用了哪些算法?相关的知识,希望对你有一定的参考价值。
随着需求的变化和技术的发展,互联网企业对数据的分析越来越深入,尤其是自然语言处理处理领域,近几年,在搜索引擎、数据挖掘、推荐系统等应用方面,都向前迈出了坚实的步伐。中文分词是文本挖掘的基础,对于输入的一段中文,成功的进行中文分词,可以达到电脑自动识别语句含义的效果。
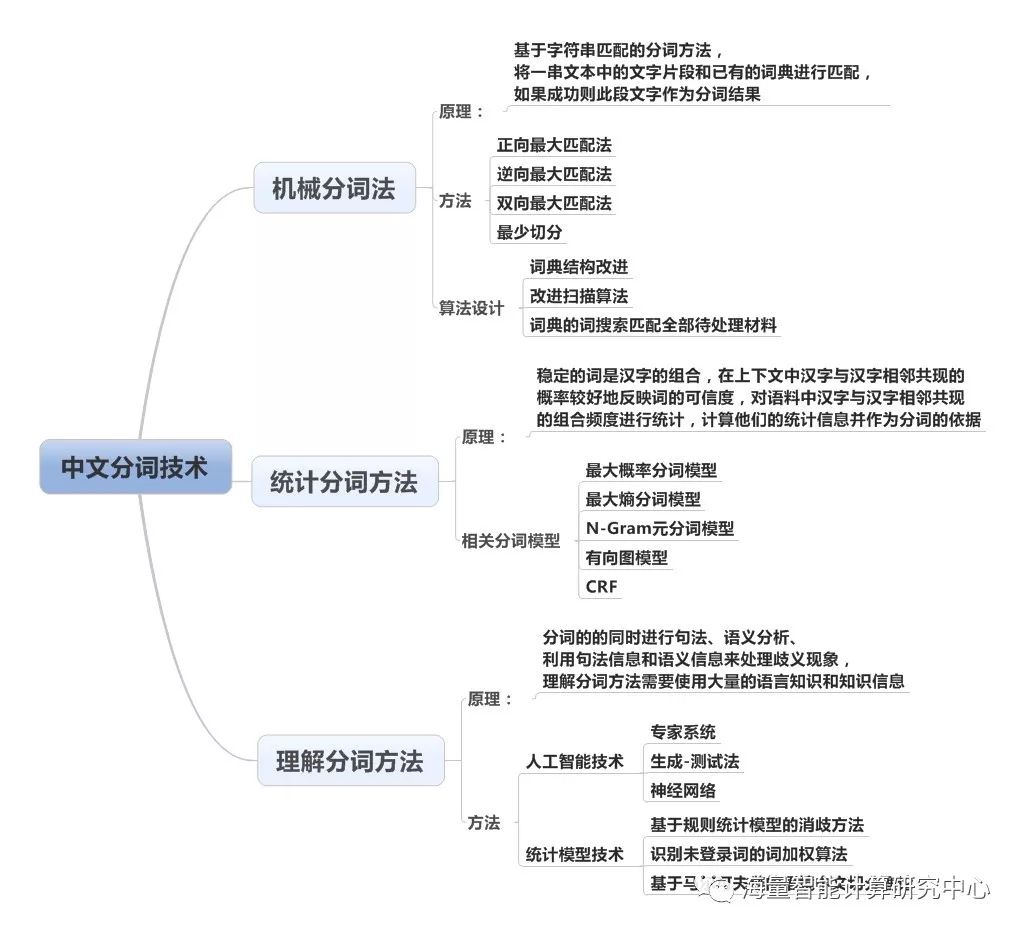
目前总体上分词算法可分为三大类:基于字符串匹配的分词方法(机械分词法)、基于理解的分词方法和基于统计的分词方法,按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
01
机械分词法
机械分词法是基于字符串匹配的分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功。
正向最大匹配法(从左到右)
把文本粗分切成一个一个句子,然后把每个句子切成单字,字典按照树形结构存储,比如这句话“牡丹还会开吗”首先查找“牡”字开头的词,然后按照字典树形结构往下走一个节点,查找“牡”后面一个字是“丹”的词,然后又下沉一个节点,找“还”下面是“会”的词,找不到了,查找就结束。
逆向最大匹配法(从右向左)
朝相反的方向发掘可以匹配的文字,比如百货大楼这个文字串,那么会向左延伸在“大楼”的前面会出现的结果是区域性的文字,比如天津或者北京等,在大楼的前面会出现更精准的定义文字符,比如商业,办公等专属性强的文字符。
双向最大匹配法(进行由左到右、由右到左两次扫描)
还可以将上述各种方法相互组合,例如,可以将正向最大匹配方法和逆向最大匹配方法结合起来构成双向匹配法,由于汉语单字成词的特点,正向最小匹配和逆向最小匹配一般很少使用。
最少分词法
使每一句中切出的词数最小,还需通过利用各种其它的语言信息来进一步提高切分的准确率。
02
基于统计分词方法
常见的基于统计的分词方法有依据概率、依据最大熵分词模型等,其中CRF(Conditionalrandom field,条件随机场)是用来标注和划分结构数据的概率化结构模型,通常使用在模式识别和机器学习中,在自然语言处理和图像处理等领域中得到广泛应用。当对于给定的输入观测序列X和输出序列Y,CRF通过定义条件概率P(Y|X),而不是联合概率分布P(X,Y)来描述模型。在实际应用中,统计分词系统都要使用一部基本的分词词典(常用词词典)进行串匹配分词,同时使用统计方法识别一些新的词,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
03
理解分词法
这种分词的方法是使计算机模拟人对句子的理解,希望计算机在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。例如时下流行的RNN(Recurrent Neural Networks,循环神经网络)会考虑上下文的关系,将当前时刻一个节点的输入除了上一层的输出外,还包括上一时刻隐藏层的输出。
从分词技术的难点和技术实施角度以及效果上的简单我们可以了看到不同方法基于现有技术发展的优劣其实各有侧重点,如字符串匹配即机械分词的方法分词速度相对较快,理解分词的准确率相对较高。

(图表来源于论文《国
到底哪种分词算法的准确度更高,目前并无定论,对于任何一个成熟的分词系统来说,不可能单独依靠某一种算法来实现,都需要综合不同的算法,例如,海量(HYLANDA)的分词算法就采用“复方分词法”,所谓复方,就是像中西医结合般综合运用机械方法和知识方法,对于成熟的中文分词系统,需要多种算法综合处理问题。海量最新推出的免费的海量分词5.0,将不断更新迭代的技术与不断优化效果并行融合,保证了效率和效果的高水平。
欢迎大家下载并试用海量分词5.0
以上是关于揭秘中文分词算法三大流派 海量分词5.0免费版应用了哪些算法?的主要内容,如果未能解决你的问题,请参考以下文章