中文分词简介
Posted 算法人生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文分词简介相关的知识,希望对你有一定的参考价值。
一个NLP Freshman的笔记,大佬们请跳过...
中文英文一个重要的区别就是,英文是天然分词的(使用空格或者标点符号),而中文是天然“分字”的,所以中文NLP任务中,分词是一个很基础的任务,大部分任务都是其下游任务。
本篇文章简单介绍中文分词,本人也只是看了不到一天吧(时间紧任务重),如有纰漏/补充可以发邮件讨论,邮箱:tianlong_wu@shannonai.com
顺便给香侬打个广告,持续招算法(NLP,CV)/大数据/后台/前端,全职 or 实习, 简历发邮箱。具体大家google一下 “香侬科技”,这里就不做PR了。
jieba 分词方法

jieba.cut()的参数HMM控制是否使用HMM分词。
DAG分词的思想呢,就是首先你得有一个词典,这个词典记录每个词的词频,当然这个词典是从某个语料库中统计的到的(请不要问我没有分词系统怎么统计的词典...)。然后对于每个你要进行分词的句子,例如“我去北京大学玩”,你去查看字典,你会得到所有可能的分词结果,例如“我/去/北京/大学/玩”,“我/去/北京大学/玩”等等。然后呢,你只要在这些所有的分词可能中找一个概率最大的就可以了,怎么找,DP,嗯。
但是有一个问题,比如你要进行分词的句子是“窗前明月光”,你的词典中没有“窗前”,那“窗前”这两个字肯定分开,即“窗前”,但是某些情况下你想要的结果是“窗前/明月/光”,这个时候DAG就没办法了(所以DAG缺点是完全没办法应付未登录词),jieba使用HMM处理这种问题。
DAG分词部分请看:http://www.cnblogs.com/zhbzz2007/p/6084196.html
HMM分词部分请看:https://www.cnblogs.com/zhbzz2007/p/6092313.html
写的太好了,我都不想再写了,嗯...
BiLstm + CRF
这是深度学习的方法,据说效果很好。
首先这个模型不是专门处理分词的,是处理标注问题的,分词可以作为一个标注任务,所以可以使用它解决。分词标注有几种,简单介绍一种BMES吧, B是开始begin位置, E是end, 是结束位置, M是middle, 是中间位置, S是single, 单独成词的位置。那么“我/周末/去/北京大学/玩”,标注序列就是“SBESBMMES”。
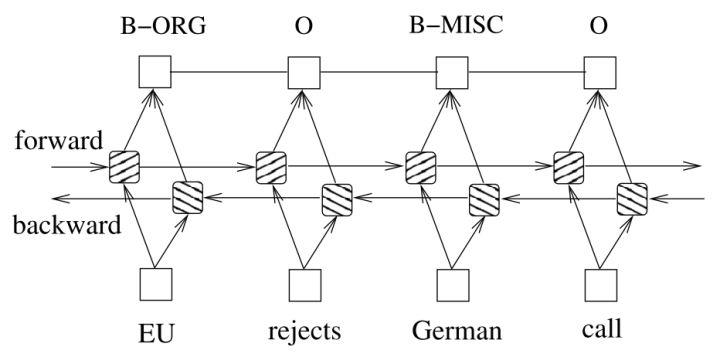
这个模型也很简单,先看BiLstm,双向LSTM嘛,大家都懂,用来提特征的,它输出维度是tag的size,分词中就是4,表示标注的非归一化的概率。这虽然已经可以训练了,但是很明显的缺陷,标注序列是由明显的转移概率的,比如B后面不可能是S,只能是M或者E,并且E的概率大一点,这是因为中文2字词更多。
怎么解决?就是使用CRF对Bilstm输出进行限制一下。
设Bi-LSTM的输出矩阵为P,其中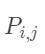 代表词wi映射到
代表词wi映射到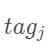 的非归一化概率。对于CRF来说,我们假定存在一个转移矩阵A,则
的非归一化概率。对于CRF来说,我们假定存在一个转移矩阵A,则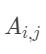 代表
代表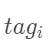 转移到的转移概率。
转移到的转移概率。
对于输入序列X对应的输出tag序列y,定义分数为:
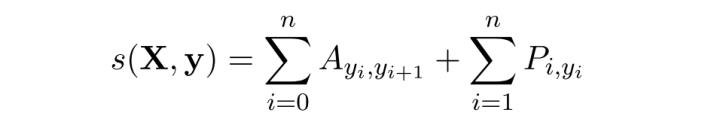
利用Softmax函数,我们为每一个正确的tag序列y定义一个概率值($Y_X$代表所有的tag序列)
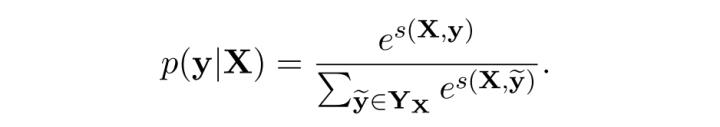
因而在训练中,我们只需要最大化似然概率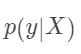 即可,这里我们利用对数似然
即可,这里我们利用对数似然
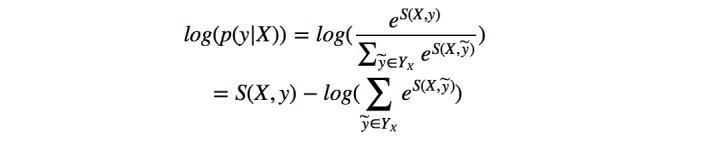
所以我们将损失函数定义为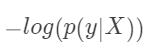 ,就可以利用梯度下降法来进行网络的学习了。
,就可以利用梯度下降法来进行网络的学习了。
在对损失函数进行计算的时候,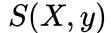 的计算很简单,而
的计算很简单,而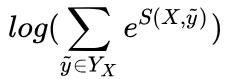 (下面记作logsumexp)的计算稍微复杂一些,因为需要计算每一条可能路径的分数。
(下面记作logsumexp)的计算稍微复杂一些,因为需要计算每一条可能路径的分数。
嗯。我们需要优化一下,再提一句,基本上遇到softmax第一反应要想想是否需要优化,因为分母的计算要么很费时,要么根本无法计算(当然不排除所有路径并不多的情况),NCE(噪声对比估计)是主流方法。这里不需要NCE,因为这里的归一化因子是可以利用上一步计算的结果的,其实是一个DP。
具体的,对于到词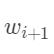 的路径,可以先把到的wi的logsumexp计算出来,然后对于只需要在前面的基础上,再计算其发射所有的tag(BMES)的概率加起来,就是到所有标注可能了。
的路径,可以先把到的wi的logsumexp计算出来,然后对于只需要在前面的基础上,再计算其发射所有的tag(BMES)的概率加起来,就是到所有标注可能了。
目前存在的问题
目前中文分词难点主要有三个:
1、分词标准:比如人名,在哈工大的标准中姓和名是分开的,但在Hanlp中是合在一起的。这需要根据不同的需求制定不同的分词标准。
2、歧义:对同一个待切分字符串存在多个分词结果。
歧义又分为组合型歧义、交集型歧义和真歧义三种类型。
1) 组合型歧义:分词是有不同的粒度的,指某个词条中的一部分也可以切分为一个独立的词条。比如“中华人民共和国”,粗粒度的分词就是“中华人民共和国”,细粒度的分词可能是“中华/人民/共和国”
2) 交集型歧义:在“郑州天和服装厂”中,“天和”是厂名,是一个专有词,“和服”也是一个词,它们共用了“和”字。
3) 真歧义:本身的语法和语义都没有问题, 即便采用人工切分也会产生同样的歧义,只有通过上下文的语义环境才能给出正确的切分结果。例如:对于句子“美国会通过对台售武法案”,既可以切分成“美国/会/通过对台售武法案”,又可以切分成“美/国会/通过对台售武法案”。
一般在搜索引擎中,构建索引时和查询时会使用不同的分词算法。常用的方案是,在索引的时候使用细粒度的分词以保证召回,在查询的时候使用粗粒度的分词以保证精度。
3、新词:也称未被词典收录的词,该问题的解决依赖于人们对分词技术和汉语语言结构的进一步认识。
参考:
https://zhuanlan.zhihu.com/p/27338210
https://www.zhihu.com/question/19578687
http://www.cnblogs.com/zhbzz2007/p/6084196.html
https://www.cnblogs.com/zhbzz2007/p/6092313.html
以上是关于中文分词简介的主要内容,如果未能解决你的问题,请参考以下文章