海云观点 | 中文分词是个伪命题
Posted 海云数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了海云观点 | 中文分词是个伪命题相关的知识,希望对你有一定的参考价值。

赵丹|海云研究院
赵丹(Diana):1973年生于天津,1996年毕业于厦门大学法律系,做了二十年码农,写了百来万行程序,2014年作为技术合伙人加盟海云。业余时间爱好户外运动,曾攀登过5000米雪山,完成过北京马拉松全程。
关注知识图谱,开放数据互联,智能数据分析,自然语言处理方向。 喜欢各种不太剧烈的体育运动,比较擅长瑜伽、游泳、乒乓球、定向越野。喜欢徒步和骑车旅行。
正文部分
▼
六年以前,第一个中文分词系统的发明人郝玺龙先生对我讲,中文分词是个伪问题。当时NLP刚入门的我完全听不懂。
最近试用了一下BERT,做了个简单的文本分类。以前做这类任务的方法都是先分词,然后把词向量化,在向量上跑各种分类模型。但是只要一分词就引入了误差,在不定制词典的前提下,分词系统本身的准确率只能做到90%。在这个基础上做向量做分类,就是个误差逐步积累的过程,最终结果可想而知。
刚开始的时候,考虑直接用LSTM。就像在唇语识别任务中一样,后来考虑到语料太少,LSTM提取不到完全的特征,效果无法保证,必须引入基于大量语料的预训练层,才能达到好的效果。当即想到了最近风头正盛的BERT。看了下git上的BERT项目,刚好有分类的例子,动手略做改造,加载自己的语料就搞成了。用下载的预训练中文模型一跑,PR都在98%以上,这是传统方法不可能达到的指标。
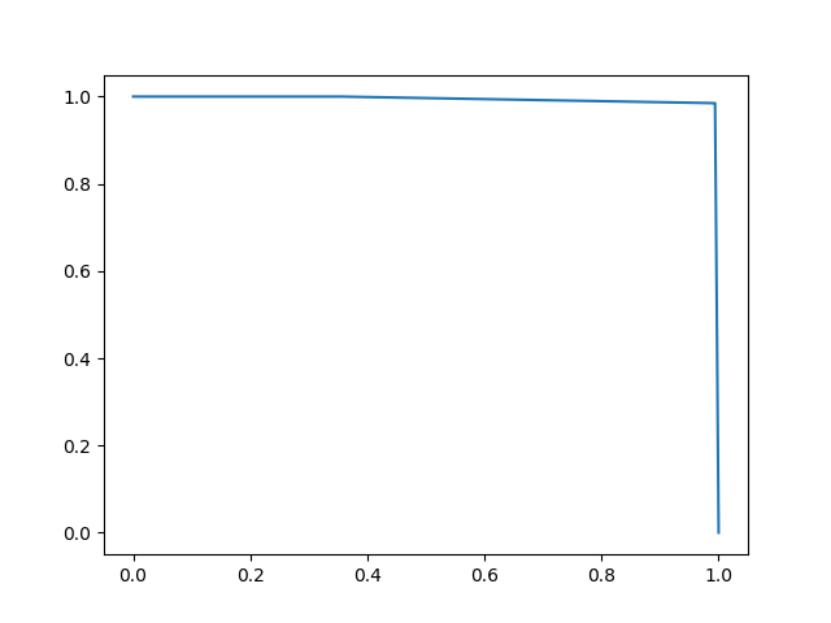
图 1 某分类任务PR曲线
这个结果确实很惊艳,不仅仅是指标如此之好,而且过程也如此简单,如此一来可能一大票NLP工程师都要失业了,什么分词、向量化、镶嵌、主题模型等等邪术都该丢到垃圾堆去了。BERT的原理既有原始论文可查,也有一大票介绍文章,我就不赘述了。与传统方法不同,BERT中文模型的tokenization是基于单个字的。下图是BERT词汇表vocab.txt的一小段。
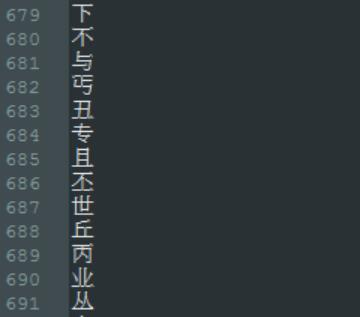
图 2 BERT词汇表一部分
这个表包含字母、数字、英文、符号和中文,其中的中文都是单字。训练模型的时候console打出来的tokenization结果也都是单字。这个事实证明了,基于字的中文NLP任务可以得到比基于词更好的结果。其实仔细想想也容易明白,中文中的构词是一种序列上的低级特征,很容易被带记忆的卷积网络提取到。只要语料足够大,用RCNN很容易拟合到构词规律,不仅能拟合大的规律,而且对于各种特例代表的小范围规律尤其有效,表现能力远远强于传统分词使用的隐马模型及其各种变形。可以说分词算法已经内置在BERT的前几层参数里了,就如同边缘检测算法已经内置在YOLO的前几层参数中一样。
那么为什么我们还要分词呢?分词其实是特定历史条件下的无奈之举。一方面因为NLP最初是以美国为主的英语国家中发展起来的,早期的研究成果都是基于英文的,而中文的词与英文的基本单位word有更好的对应关系。中文与英文的一个基本差异在于,中文的基本构成单位是字,每个字都是独立的意义单元;而英文的基本单位是字母,字母不是意义单元,只用来拼写,完全没有意义,只有词才是独立的意义单元。中文在古代,基本上是严格的一字一意,要表达新的含义就要造新的字出来,这种表意方法在古代语义系统较为简单固定,变化不大,并且抽象程度不高的环境下是可行的,因为新字及其各组成部分基本是象形的,可以观其形而知意,并且总字数不算太多,记忆负担不大。然而到了后来,新概念越来越多,语言变化越来越快,这种靠造新字扩展语言含义的办法就行不通了,中文逐渐发展成单字和多字词混合表意的系统特别是近现代,已经发展成以双字词为主要语义单元的系统。所以大多数中文使用者都直观感觉到中文的词而不是字,是英文中word的对应之物。最早一批中文NLP研究者,为了能够借用基于英文的NLP早期研究成果,就需要以词为单位对中文进行处理,然而中文的书写传统是基于字的,词并没有明显的边界,于是就产生了分词的需求。分词带来的一个额外的好处是,把语言处理这样的复杂问题分层,从而简化了每层复杂度;把语言的处理单位减少了,于是起到了一定程度上节省算力的效果,这在之前理论不足、计算资源昂贵的年代是颇具实用价值的。
然而到了今天,中文分词还有存在的必要吗?我认为虽不说完全没有,但是也在逐渐降低,迟早会消失。深度学习直接把短程特征和长程特征一并处理了,并不需要再在中间划一条界线,算力也已经充足到不用刻意节约的程度。如果说今天还有什么需要分词的场合,那大概是那些要复用传统模型和程序的地方吧,也就是某些legacy system。

回想六年前,没有BERT,没有GPT,没有LSTM,甚至RCNN也没有在语言问题中使用的案例,在那种情况下,郝玺龙先生,作为中文分词方法的发明人,提出那样的观点,可以说是超越时代的。郝先生是引领我入门NLP的导师,也是海云数据的天使投资人,是我生命中的恩人。
合作须知:合作及投稿请在微信后台直接回复或发邮件:haiyunjun@hiynn.com
推荐阅读



海云数据(HYDATA)
海云数据是AI场景筑梦师,专注于利用人工智能与可视分析技术,在场景中赋予用户更加智慧的决策能力,真正实现场景业务升级与场景业务进化。
你还可以在
【新浪微博】【今日头条】【一点资讯】
【百度百家】【搜狐新闻客户端】
【网易新闻客户端】【爱奇艺】
找到我们
如果你喜欢我们的文章请点击右上方分享哦
▼ 喜欢的话可以点击“好看”哦~
以上是关于海云观点 | 中文分词是个伪命题的主要内容,如果未能解决你的问题,请参考以下文章