尴尬!北大开源高准确度中文分词工具包,数据表现却遭质疑
Posted 图灵TOPIA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了尴尬!北大开源高准确度中文分词工具包,数据表现却遭质疑相关的知识,希望对你有一定的参考价值。
图灵TOPIA
编辑:李尔客
图灵联邦编辑部出品
近期,由北京大学语言计算与机器学习研究组研制的全新中文分词工具包Pkuseg在Github上开源发布,据发布者称Pkuseg-Python简单易用,具有如下几个特点:
1、高分词准确率。相比于其他的分词工具包,此工具包在不同领域的数据上都大幅提高了分词的准确度。根据测试结果,Pkuseg分别在示例数据集(MSRA和CTB8)上降低了79.33%和63.67%的分词错误率。
2、多领域分词。该工具包训练了多种不同领域的分词模型。根据待分词的领域特点,用户可以自由地选择不同的模型。
3、支持用户自训练模型。支持用户使用全新的标注数据进行训练。
高分词准确率引关注
此项目一经发布引起了强烈反响,其中测试数据尤为引人关注,发布者称他们选择THULAC、结巴分词等国内代表分词工具包与Pkuseg做性能比较。选择Linux作为测试环境,在新闻数据(MSRA)和混合型文本(CTB8)数据上对不同工具包进行了准确率测试。使用了第二届国际汉语分词评测比赛提供的分词评价脚本。评测结果如下:
数据显示对比结巴、THULAC两个目前比较受欢迎的开源分词工具,Pkuseg在准确性方面大大提高。在MSRA数据集上,结巴和THULAC的错误率为18.55%和14.52%,而Pkuseg仅有3.25%;在CTB8数据集上,同样结巴和THULAC的错误率高达20.42%和12.23%,而Pkuseg的错误率仅有4.36%
一方面,Pkuseg的测试准确率如此之高,受到了众多开发者的追捧;另一方面,Issue里也有人对测试数据的公平性提出了质疑。
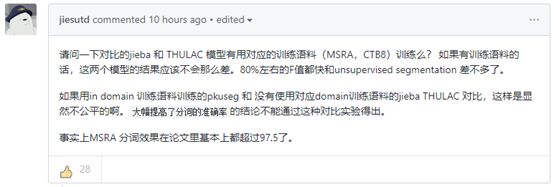
质疑1:与之做对比的分词工具测试集和训练集是否一致?
与Pkuseg做对比的分词工具(结巴和THULAC),三者之间的测试集和训练集是否一致?
众所周知,当我们在做分词模型测评的时候,如果使用随机挑选的测试集去评价,可能会得到不客观的结论。
机器学习方法得到的分词模型学到的是该训练集上的分词标准,如果把它应用到分词标准差异很大的测试集上,其测试结果既不理想也无甚意义。
反之,即使我们在某测试集获得了良好的结果,也更可能说明的是该测试集和模型所用的训练集分词标准比较接近,例如测试集和训练集是同源的。
因此,保证测试集和训练集的分词标准一致性应当作为评价机器学习方法分词模型的前提条件之一。
由此推理,Pkuseg在与结巴、THULAC做对比之前,是否有对它们用对应的训练语料(MSRA、CTB8)做训练会直接影响测试结果是否公平。
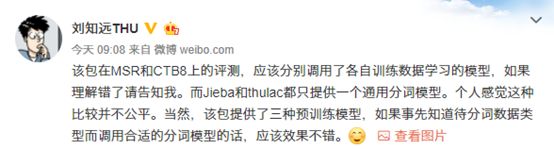
无独有偶,清华大学计算机系@刘知远THU 也在微博上提出了相关质疑:

更有网友戏称,这个测试结果讲白了就是一个铁人三项的成绩和三个分赛冠军进行单项比较。
质疑2:测试集规模几何?
Github上发布者并没有对该项目的测试集数据规模做说明,此举也引发了众多质疑。其中毕业于清华大学的知名互联网博主@梁斌penny 也对此发表了自己的看法
到底针对Pkuseg这个分词工具包,测试数据的评价方法是否合理公平,是否还有我们不知道的细节,目前为止北大方面也尚未有官方回复,图灵君将时刻保持关注。
附:常用的开源分词工具一览
1.jieba(结巴)
https://github.com/fxsjy/jieba。
2.SnowNLP
SnowNLP: Simplified Chinese Text Processing,
可以方便的处理中文文本内容,所有的算法都是自己实现的,并且自带了一些训练好的字典。
3. THULAC
THULAC(THU LexicalAnalyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,GitHub 链接:
https://github.com/thunlp/THULAC-Python,具有中文分词和词性标注功能。
4.NLPIR
前身为2000年发布的 ICTCLAS 词法分析系统,GitHub 链接:
https://github.com/NLPIR-team/NLPIR,是由北京理工大学张华平博士研发的中文分词系统,经过十余年的不断完善,拥有丰富的功能和强大的性能。
5.LTP
语言技术平台(Language Technology Platform,LTP)是哈工大社会计算与信息检索研究中心历时十年开发的一整套中文语言处理系统。LTP 有 Python 版本,GitHub链接:
https://github.com/HIT-SCIR/pyltp。
6.NLTK
NLTK,NaturalLanguage Toolkit,是一个自然语言处理的包工具,各种多种 NLP 处理相关功能,GitHub 链接:
https://github.com/nltk/nltk。
7. Hanlp
HanlpHanLP从中文分词开始,覆盖词性标注、命名实体识别、句法分析、文本分类等常用任务,提供了丰富的API。Python接口:
https://github.com/hankcs/pyhanlp 。
8. Ansj
Ansj是由孙健(ansjsun)开源的一个中文分词器,为ICTLAS的Java版本,基本上重写了所有的数据结构和算法.词典是用的开源版的ictclas所提供的。并且进行了部分的人工优化其Github链接:
https://github.com/NLPchina/ansj_seg。
以上是关于尴尬!北大开源高准确度中文分词工具包,数据表现却遭质疑的主要内容,如果未能解决你的问题,请参考以下文章