中文分词器应用实践
Posted 拍码场
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文分词器应用实践相关的知识,希望对你有一定的参考价值。
背景及应用场景
近年来,随着物联网、智慧城市、人工智能、5G等新技术与应用的快速发展,使得数据量呈指数级增长,带着我们快速迈进了信息爆炸的时代,各行各业都在疯狂的产生数据:
Twitter每天发布5000万条消息
Facebook每天生成300TB数据
淘宝每天产生20TB数据
在这种情况下,想要准确、快速的获取自己需要的东西显得特别重要,但是在这些数据中,存在着大量的非结构化数据,如大段文本。为了充分利用这些数据,我们需要对文本数据进行结构化处理,以便于后期的检索、统计和分析。
在我们的汽车项目中,同样遇到这样的问题,需要从大量文本中提取出汽车的品牌、车型、车系等关键数据,如对于这段文本“大众途安 2013款 1.4T 自动舒适版5座”,需要提取出以下信息:
大众---品牌
途安---车系
2013款 1.4T 自动舒适版5座---车型
然后存储为结构化的数据,并进行后续的检索、统计及分析。
为了快速、准确提取文本中的关键数据,我们在项目中引入了中文分词器。中文分词器是对文本数据进行结构化处理的主要方式,它的主要功能是将中文文本中的所有词汇按照某种策略进行分割,获得一批中文词汇,并且在这个分割过程中能够保证一定的准确率。
目前市场主流的分词器有MMSeg4j分词器、Word分词器、IKAnalyzer分词器、Paoding分词器等,综合考虑到分词准确性、识别效率及引入成本等因素,我们在项目中引入了Word分词器。
Word分词器
1. 实现原理
Word分词器是基于词典的分词器(基于字符串匹配),同时支持同义标注、反义标注,并利用ngram模型来消除歧义。在word分词器初始化时,会将词典以前缀树数据结构加载至内存,再指定分词算法来进行分词匹配。
2. 分词算法
Word分词器主要思路是把中文文本按照一定的分词算法将待分析的汉字串与已知且足够大的中文词典库进行比对,从而达到分词效果。Word分词器主要支持以下几种分词算法:
正向最大匹配算法(MaximumMatching)
逆向最大匹配算法(ReverseMaximumMatching)
正向最小匹配算法(MinimumMatching)
逆向最小匹配算法(ReverseMinimumMatching)
双向最大匹配算法(BidirectionalMaximumMatching)
双向最小匹配算法(BidirectionalMinimumMatching)
3.功能特性
Word分词器除了支持各种分词算法以外,还提供了诸多功能特性,在项目中可以起到重要作用,具体如下:
自定义词典:支持自定义词典进行文本匹配,提高匹配准确率
同义词:“一决雌雄”与“一较长短”为同义词,在同义词字典文件中同一行以空格分割即可,如“一决雌雄 一较长短”
反义词:“一反常态”与“一如既往”为反义词,在反义词字典文件中同一行以空格分割即可“一反常态 一如既往”
停用词:无意义的字、词,比如“的”一行为一个词
分词算法实现
1. 正向最大匹配算法(MaximumMatching)
该算法的基本思想是按照文本从左至右的阅读习惯取一定长度(等于词典中最长词条中汉字的个数)的汉字串与词典中的最长词条进行比对,如果比对成功则把该汉字串作为一个词切分出来,如果在词典中匹配不到这样长度的汉字串,则去掉该汉字串的末尾一个字重新与词典中的词条进行比对,按照汉字串长度逐步减小的原则重复以上比对过程,直到匹配成功为止,这样就完成一个词的切分,然后对剩余未切分的文本重复上述一系列步骤,直到切分出语句中所有词为止。
2. 逆向最大匹配算法(ReverseMaximumMatching)
它的分词过程与MM方法相同,不同的是分词方向与MM正好相反。每次是从待处理文本的末尾开始处理,每次匹配不成功时去掉的是汉字串的首字。由于篇幅所限,本文就不再一一介绍其他分词算法。
项目实现方案
在汽车项目中,我们采用了自定义词典,逆向最大匹配算法来实现汽车关键属性的提取,同时引入了自定义同义词标注,实现更高准确性的匹配。
1. 自定义词典
考虑到在项目中做中文字符匹配仅仅涉及汽车品牌、车型、车系,字符范围是明确的,故配置三个自定义词典,具体如下:
品牌词典
车系词典
车型词典
2. 使用逆向最大匹配算法
案例:奥迪A4L 2016款 35 TFSI 自动标准型
奥迪A4L不能匹配为奥迪A4,这时候需要使用逆向最大匹配,如果使用逆向最小匹配,此时匹配的车系为A4而不是A4L。
3. 自定义同义词标注
案例:
DS 6 2016款 1.6T 雅致版THP160
谛艾仕6 2016款 1.6T 雅致版THP160
由于“DS”与 “谛艾仕”为同一品牌,在需要处理的文本数据中,这两种形式都是存在的。我们的品牌词典中只定义了“DS”而没有“谛艾仕”,这时候通过增加同义标注“DS=谛艾仕”,使得匹配时二者做等价处理。
代码演示
1. 在pom.xml 文件中引入word分词器所需jar包
<dependency><groupId>org.apdplat</groupId><artifactId>word</artifactId><version>1.3</version></dependency>
2. 自定义配置文件
在resourece包中配置Word分词器配置文件,文件名为word.local.conf。
3. 详细配置如下图所示,主要包括词典文件、同义词、反义词配置
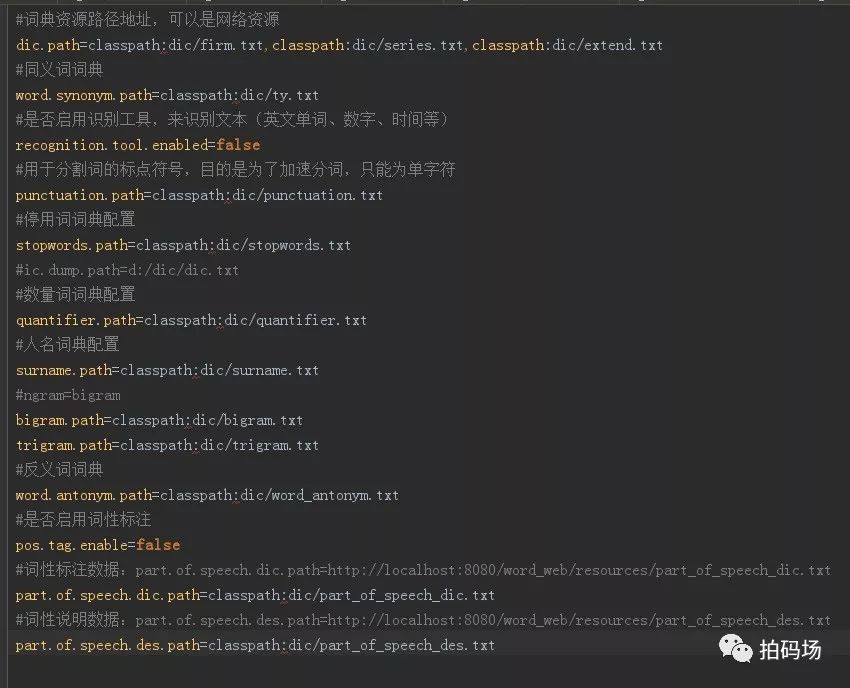
4. 自定义词典
由于不同应用场景的专业术语差距很大,我们通过自定义词典(汽车品牌、车型、车系)来有效提高识别准确率,如下图示,词典以文本形式保存在文件中,每行保存一条数据 。

优化心得
1. 词典优化:
在项目中,根据实际需要适当优化字典可以提高分词效率,节省内存空间。比如此项目中是对车源数据进行处理,不需要word分词器自带通用词典(dic.txt)、人名词典(surname.txt)、量词词典(quantifier.txt)等,在配置中指定dic.path=classpath:firm.txt,或用同名空文件覆盖jar包中默认词典(不能不指定,不指定用的是默认词典)。
2. 算法优化:
逆向最大匹配法的思想具有简单易懂的特点,但是该算法对于一些比较特殊的句子,分词准确率可能会降低。例如下面这个句子:“爱迪生发明了很多东西”。
如果你的词典足够大,你会发现,按照逆向最大匹配的方法,计算机会将“明了”看做一个中文词汇分隔出来,继续向下走,计算机将分出词汇“生发”,这样一来,就会造成 “爱迪 生发 明了” 的错误。
没关系!我们还有正向最大匹配法,我们可以用正向最大匹配法,对这个句子进行分词,结果就对了。但是正向最大匹配法也会出现bug,怎么办呢,我们可以将正向和逆向结合,这样就是另外一种分词策略:双向最大匹配法,大大降低了出现bug的概率。
3. 辅助优化:
很多情况下,分词匹配的准确度取决于词典的数量。在词典不满足少数分词情况时,可以配合采用向量匹配、模糊匹配等其他方式,提高分词准确率。
本文简单介绍了一下中分分词器在拍拍贷的应用实践。欢迎感兴趣的同学扫描以下二维码,进一步交流讨论。
更多福利请关注官方订阅号“拍码场”
好内容不要独享!快告诉小伙伴们吧!
以上是关于中文分词器应用实践的主要内容,如果未能解决你的问题,请参考以下文章