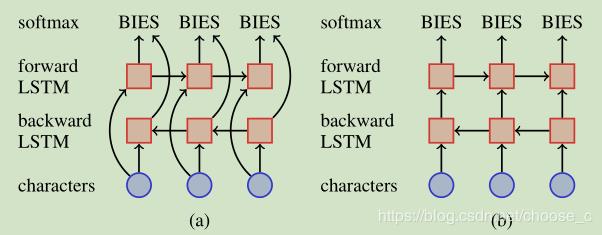
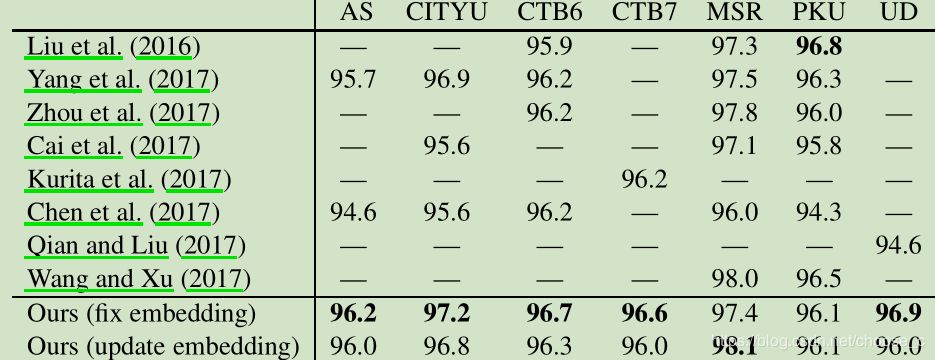
作者:choose_c原文链接:https://blog.csdn.net/choose_c/article/details/86545299 论文题目:State-of-the-art Chinese Word Segmentation with Bi-LSTMs作者:Ji Ma Kuzman Ganchev David Weiss机构:Google AI Language论文发表:EMNLP2018
错误分析: 文章还对错误进行了分析,其中三分之二的错误来自out of vocabulary,而实验证明了pretrain word embedding在oov情况下可以提高10%的召回率,对pretrain word embedding肃然起敬(今年elmo、GPT、bert的惊艳效果也证明了预训练模型和迁移学习在NLP中的巨大发展前景)。对于oov问题,基于字的特征会更加有效,而且基于知识库的研究也可以优化这方面的问题。另外三分之一的错误来自标注错误(人工智能问题=模型+数据,模型优化到头秃,只能数据背锅了)。文章使用一个脚本计算了每个数据集标注的不一致性,不一致性严重的数据集也是现在已有方法效果不好的,这个锅数据就顺理成章地背下了。作者脚本的大概思路是统计单词作为双词出现的次数,或者是双词作为单词和三次出现的次数,没有说的很详细,应该就是一些词频统计的东西。说实话,这些小脚本工具确实有时候很有用,很能快速反映一些数据的问题或者是帮助找到一些特征和信息。