带你走进中文分词
Posted 后厂反应堆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你走进中文分词相关的知识,希望对你有一定的参考价值。
本文作者
目录:
1.什么是中文分词
2.中文分词的困难
3.中文分词的方法
4.基于规则的中文分词方法
5.中文分词工具
一、什么是中文分词
1.1中英文的区别
英文的基本表意单元——单词之间以空格作为天然的分隔符。与英文等语言相比,中文虽然在字、句和段之间有较为明显的分界符,但是最小的能够独立运用的语言单位——词却没有一个明确的分界符。

1.2 中文分词定义
在处理中文文本时,将连续的字序列按照一定的规范重新组合成词序列,这个过程就是中文分词,即通过计算机自动识别句子的词并在词之间添加分隔符(空格、其他符号)。
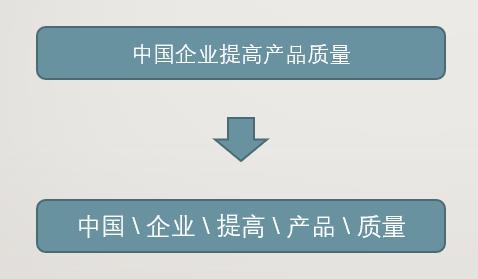
中文分词示例
1.3 为什么要进行中文分词
1.3.1 数据结构化处理的第一步
机器学习、深度学习解决现实问题都是首先将现实问题抽象成为数学模型,再对这个数学模型进行研究和求解,从而解决问题。问题相关的文本很多都是一些非结构化的数据(比如,网页文本、新闻报道等),想要对这些文本数据进行数学分析则首先需要把这些文本数据转化为结构化的数据,而分词则是数据结构化处理的关键一步,因此在中文自然语言处理中,中午分词是一个非常基础的任务和关键的步骤。

数据结构化处理-分词
1.3.2 词是最小的能够独立运用的语言单位
在汉语中,词是最小的能够独立运用的语言单位,因此计算机对中文文本进行编码,文本按词切分再进行编码比按照字或者句粒度更加合适。
【字】粒度过小,无法完整表达含义;
【词】粒度合适,最小的能够完整表达含义的语言单位;
【句】粒度过大,信息量过大;

字 词 句
计算机对中文文本进行信息挖掘、数据分析和很多的NLP任务(情感分词、词性标注、句法分析、关系抽取、文本纠错等),都需要进行中文分词后计算机才自动识别语句含义,识别语句含义需要先了解句子中有哪些词语,不同词语的不同组合会使得语句含义可能大不相同。
1.3.3 其他
随着深度学习不断研究和发展,数据量和算力都呈现出爆炸式的增长,基于字符的BERT的提出统治了各项NLP任务的榜单。但是在大部分情况和任务下,分词还是必要的步骤,如命名实体识别、词性标注、关键词提取等。
二、中文分词的困难
中文分词的过程看似简单,实际却十分复杂,当前主要的困难在于分词规范、分词歧义、未登录词识别。此外分词粒度的粗细也会影响最终的分词结果。
2.1 分词规范
“词是什么”(词的抽象定义)一直是汉语语言学界无法确定而又必须重视的问题。因为单字词与词素之间的划界等问题,至今都无法拿出一份公认的、具有权威性的词表。不同个人对汉语认知的差异,也会对分词造成困难——下图是刘开英教授的一个实验:对于图中汉语双音节结构的词语,有相当比例的人主张将其切开。

双音节结构词语及其被切分的概率(%)
目前有一些高校、组织和机构公开发布了中文分词数据集,如MSRA、PKU、CTB6/7/8等,它们一般都有一些标注规范,如北京大学计算语言学研究所为研制 2600 多万字《人民日报》基本标注语料库制订了词语切分·词性标注规范《北京大学现代汉语语料库 基本加工规范》。
2.2 歧义识别
歧义是指同一句话,有两种或两种以上的表达意义不相同的切词方案,例如“南京市长江大桥”,可以分成“南京市/长江大桥”,或者可以分成“南京/市长/江大桥”。
歧义主要分为三类:
(1)交集型歧义(Overlapping Ambiguity)
定义:对于一个给定的字符串abc,如果ab、bc的组合能够被识别为词,则称字符串组合abc存在交集型歧义。

(2)组合型歧义(Combination Ambiguity)
定义:对于一个给定的字符串ab,如果a、b、ab能够被识别为词,则称字符串组合abc存在组合型歧义。
如,“学生会实行轮值制度”、“学生会在课堂犯困”在第一句话中“学生会”是一个词,而在第二句话里则不是。

(3)真歧义
除了交集型歧义和组合型歧义外,还有一种相较不常见的歧义类型——歧义字符串的多种分词结果都是正确的,若要消除歧义必须结合上下文判断,这一类歧义为真歧义。

2.2 未登录词识别
未登录词(Out of Vocabulary, OOV)主要指命名实体(人名、地名、机构名)、新词、专业术语等词汇,即分词词典没有收录的且实际存在的词汇。
在中文分词中,与歧义识别相比,未登录词带来的问题更大、识别的错误更多,占比高达98%以上。
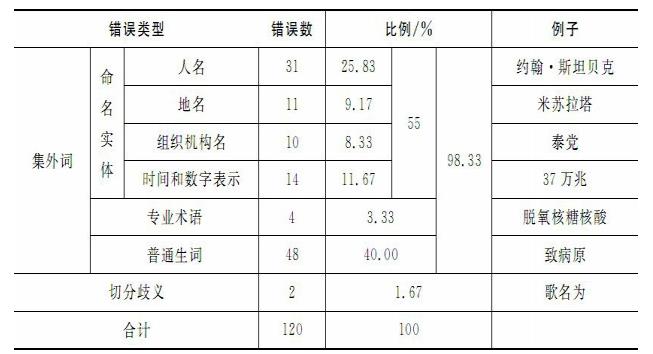
分词错误类型统计 (宗成庆《统计自然语言处理》)
E.g. 腾阿讯里市值突破3万亿,马化云寻找新的增长点。其中,“腾阿讯里”是机构名,“马化云”是人名
全世界的公司名、人名无数,不可能都收录入字典。因此,对于未登录词识别,目前主要是使用统计学的方法来解决。
三、中文分词的方法
中文分词技术自提出至今,经过了多年研究提出了很多方法,可以主要归纳为“基于规则分词(字符串匹配)”、“基于统计的分词”、“基于深度学习的分词”。
3.1 基于规则(词典匹配)的分词方法
优点:资源占用少、速度快
缺点:通用性不强,对不同领域文本分词效果差异巨大;十分依赖词典
3.2 基于统计的分词方法
基于统计的分词方法主要是依据字与字之间相邻的紧密程度来进行分词,即**(基本思想)若相邻的字在不同的文本中出现的频率越高,则表示相连的这字符串是词的可能性越高**。常用一些算法主要有HMM、MEMM、CRF、SVM等。
优点:通用性较强
缺点:资源占用较多、速度一般
3.3 基于深度学习的分词方法
目前基于深度学习的分词研究主要采用BiLSTM-CRF框架实现分词器(+外部特征/词典),本质上是将分词任务转化为序列标注任务,分词准确确率高达97.5%(公开分词数据集)。
优点:通用性强
缺点:资源占用多、速度慢
四、基于规则的中文分词方法
规则分词,又可以称为基于字符串匹配的分词。早期的中文分词主要通过人工建立并维护词典,在切分句子时将句子的每个字符串与词典中的词进行匹配,匹配上则切分,否则不切分。
优点:简单、快速;
缺点:对未登录词的识别不好,一旦句子出现词典中未收录的词语,则容易切分错误;如今新词层出不穷,词典的维护工作巨大;
其常用的几种规则分词方法如下:
正向最大匹配法(由左到右的方向);
逆向最大匹配法(由右到左的方向);
双向最大匹配法(由左到右、由右到左,进行两次扫描);
4.1 正向最大匹配法(Maximum Match Method)
4.1.1 基本思想
假设词典中最长单词有i个汉字字符,则取待切分字符串的前i个字符作为匹配字段,查找词典并于词典中的词进行比对,若查找成功则该匹配字段作为一个词语切分出来,若查找失败则将该匹配字段的最后一个字符去除,继续如此循环操作,直到查找成功或匹配字段为空(匹配字段长度为1时剩余的字符单独成词)。
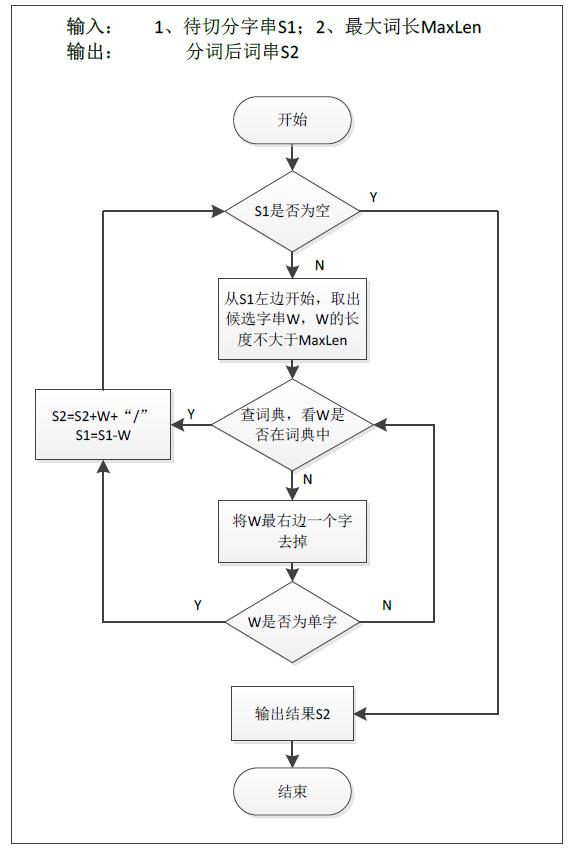
正向最大匹配法流程图(摘自网络)
4.1.2 举例说明(正向最大匹配法)
假设当前字典curr_dict如下,词典中最长字符串”研究生“长度为3,因此窗口大小为3。
curr_dict = {"研究生", "生物", "物质", "生活", "水平", "不断", "提高"}对“研究生物质生活水平不断提高”进行分词
Iteration 1
step1: 研究生物质生活水平不断提高 [当前窗口:"研究生" 查询词典->匹配->去除"研究生"并添加至result中]result = [“研究生”]
Iteration 2
step1: 物质生活水平不断提高 [当前窗口:"物质生" 查询词典->不匹配->"物质生"截去末尾一字符]step2: 物质生活水平不断提高 [当前窗口:"物质" 查询词典->匹配->去除"物质"并添加至result中]result = [“研究生”, “物质”]
Iteration 3
step1: 生活水平不断提高 [当前窗口:"生活水" 查询词典->不匹配->"生活水"截去末尾一字符]step2: 生活水平不断提高 [当前窗口:"生活" 查询词典->匹配->去除"生活"并添加至result中]result = [“研究生”, “物质”, “生活”]
…
Iteration 6
step1: 提高 [当前窗口:"提高" 查询词典->匹配->去除"生活"并添加至result中]result = [“研究生”, 物质", “生活”, “水平”, “不断”, “提高”]
4.2 逆向最大匹配法(Reverse Maximum Match Method)
逆向最大匹配法除了分词过程中切分方向与正向最大匹配法相反外,其基本原理基本相同。
因为汉语中偏正结构较多,逆向匹配能够提高分词的精确度。实验表明,仅使用正向最大匹配的错误率为1/169,仅使用逆向最大匹配的错误率为1/245(宗成庆《统计自然语言处理》)。
4.3 双向最大匹配法(Bi-direction Matching Method)
双向最大匹配法:将正向最大匹配得到的分词结果和逆向最大匹配法的分词结果比较,按照最大匹配原则将两者结果中词数最少的作为结果。
双向最大匹配的规则如下所示:
正向/逆向 完全相同,任意选取一个作为最终结果;
正向/逆向 不完全相同,则单字个数越少越好;
正向/逆向 不完全相同&单数相同,则非词典词越少越好;
正向/逆向 不完全相同&单数相同&非词典词数相同,则总词数越少越好(分词粒度越大越好)
双向最大匹配法的准确度:
根据研究,对于中文使用正向/逆向两种切分方法:90%左右的语句得到的结果一样;9%左右的语句切分结果不一样但其中必有一个正确的结果;不到1%的语句两种切分方法都不对。
PS:粒度越大越好,表达的意思越准确,比如:“北京大学”和“北大”,其中“北京大学”粒度比“北大”更大,表达的意思更加明确。
4.4 相关代码
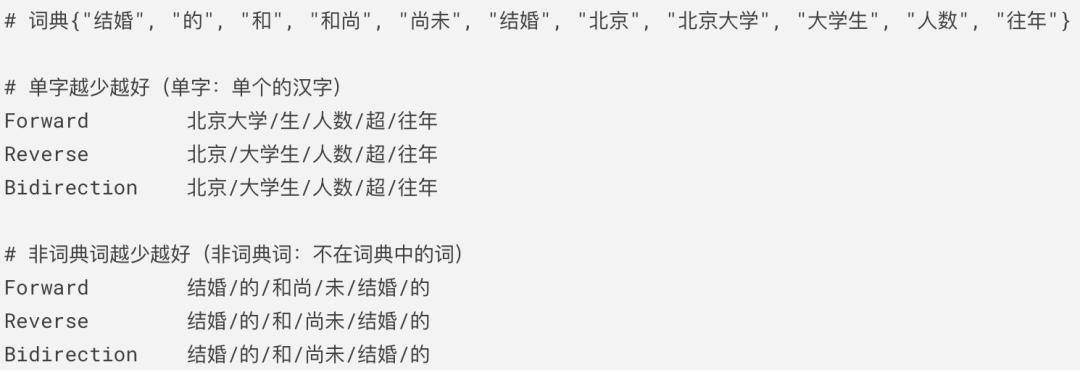
class MaximumMatch(object):"""Maximum Match Method"""def __init__(self):# windows_size 字典最长字符串的长度self.windows_size = 4# 读取字典-略self.dictionary ={"结婚", "的", "和", "和尚", "尚未", "结婚","北京", "北京大学", "大学生", "人数", "往年"}def segment(self, text):result = []index = 0while index < len(text):temp = ''for size in range(self.windows_size+index, index, -1):temp = text[index:size]if temp in self.dictionary:index = size - 1breakindex = index + 1result.append(temp)return "/".join(result)class ReverseMaximumMatch(object):"""Reverse Maximum Match Method"""def __init__(self):# windows_size 字典最长字符串的长度self.windows_size = 4# 读取字典-略self.dictionary ={"结婚", "的", "和", "和尚", "尚未", "结婚","北京", "北京大学", "大学生", "人数", "往年"}def segment(self, text):result = []index = len(text)while index > 0:temp = ''for size in range(index-self.windows_size, index):temp = text[size:index]if temp in self.dictionary:index = size + 1breakindex = index - 1result.append(temp)result.reverse()return "/".join(result)class BiMaximumMatch(object):"""Bi-directction Matching Method"""def __init__(self):# windows_size 字典最长字符串的长度self.windows_size = 4# 读取字典-略self.dictionary ={"结婚", "的", "和", "和尚", "尚未", "结婚","北京", "北京大学", "大学生", "人数", "往年"}def segment(self, text):result_mm, result_rmm = [], []# 正向index_mm = 0while index_mm < len(text):temp = ''for size in range(self.windows_size+index_mm, index_mm, -1):temp = text[index_mm:size]if temp in self.dictionary:index_mm = size - 1breakindex_mm = index_mm + 1result_mm.append(temp)# 逆向index_rmm = len(text)while index_rmm > 0:temp = ''for size in range(index_rmm-self.windows_size, index_rmm):temp = text[size:index_rmm]if temp in self.dictionary:index_rmm = size + 1breakindex_rmm = index_rmm - 1result_rmm.append(temp)result_rmm.reverse()# 完全相同if "/".join(result_rmm) == "/".join(result_mm):return "/".join(result_mm)# 不完全相同# 单字数越少越好single_mm = [x for x in result_mm if len(x) == 1]single_rmm = [x for x in result_rmm if len(x) == 1]if len(single_mm) < len(single_rmm):return "/".join(result_mm)elif len(single_mm) < len(single_rmm):return '/'.join(result_rmm)# 单字数相同,非词典词越少越好dict_rmm = [x for x in result_rmm if x in self.dictionary]dict_mm = [x for x in result_mm if x in self.dictionary]if len(dict_rmm) > len(dict_mm):return "/".join(result_rmm)elif len(dict_rmm) < len(dict_mm):return '/'.join(result_mm)# 单字数相同,非词典词数相同,总词数越少越好if len(result_rmm) < len(result_mm):return "/".join(result_rmm)else: # len(result_rmm) > len(result_mm)return "/".join(result_mm)if __name__ == '__main__':text = "结婚的和尚未结婚的"# text = "北京大学生人数超往年"mm = MaximumMatch()print("Forward\t\t", mm.segment(text))rmm = ReverseMaximumMatch()print("Reverse\t\t", rmm.segment(text))bi_mm = BiMaximumMatch()print("Bidirection\t", bi_mm.segment(text))
五、中文分词工具
随着中文自然语言处理技术的不断发展、成熟,为了更加简便、高效地处理中文文本内容,越来越多优秀的的中文分词工具涌现出来,以下介绍几个Github上最受欢迎的中文分词工具。
5.1 Hanlp
Github:https://github.com/hankcs/HanLP
HanLP是一个面向生产环境的多语种自然语言处理工具包,它提供分词、词性标注、命名实体识别、依存句法分析、自动摘要、拼音转换、简繁转换等功能。
5.2 Stanford CoreNLP
Github:https://github.com/stanfordnlp/CoreNLP
Stanford CoreNLP是斯坦福大学NLP组用Java开发的NLP工具,它支持多国语言(英语(默认)、中文、法语、德语、阿拉伯语、西班牙语),提供分词、词性标注、命名实体识别、依存句法分析等功能。
5.3 SnowNLP
Github:https://github.com/isnowfy/snownlp
SnowNLP是一个用python写的类库,可以方便的处理中文文本内容,其所有的算法都是自己实现的,并且自带了一些训练好的字典。
5.4 pyltp
Github:https://github.com/HIT-SCIR/pyltp
pyltp 是哈工大语言技术平台(Language Technology Platform, LTP)的 Python 封装,其除了分词之外,还提供词性标注、命名实体识别、依存句法分析、语义角色标注等功能。
pip安装或者从源代码安装pyltp报错,可以通过下载安装包安装:
pyltp-0.2.1-cp35-cp35m-win_amd64.whl:
http://suo.im/6wdDiK
pyltp-0.2.1-cp36-cp36m-win_amd64.whl
http://suo.im/5y3UyV
5.5 jieba
Github:https://github.com/fxsjy/jieba
jieba是一个 Python 中文分词组件,它支持三种分词模式(精确模式、全模式、搜索引擎模式),同时支持用户自定义词典,以便自行添加新词解决jieba词库中没有的词,从而提高分词的准确性。
精确模式:试图将句子最精确地切开,适合文本分析;
全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词;
后续讲解安排:基于统计的中文分词-HMM模型;基于深度学习的中文分词-BiLSTM-CRF等。
查看图片,
开启AI学习之旅
现面向所有技术发烧友
征集优秀原创技术文章
后厂反应堆将为你提供展示平台
期待你的分享哦!
(可添加上图微信投稿)
以上是关于带你走进中文分词的主要内容,如果未能解决你的问题,请参考以下文章