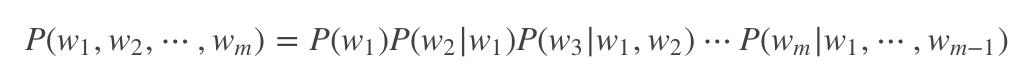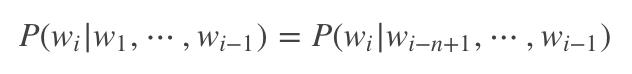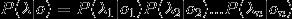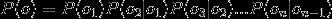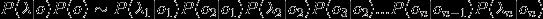分词(word tokenization)
,也叫切词,即通过某种方式将句子中的各个词语识别并分离开来,使得文本从“字序列”的表示升级为“词序列”表示。分词技术不仅仅适用于中文,对于英文、日文、韩文等语言也同样适用。
虽然英文中有天然的单词分隔符(空格),但是常有单词与其他标点黏滞的情况,比如"Hey, how are you."中的"Hey"和"you"是需要与身后的标点分隔开的
为什么需要分词?
能不能不分词?
中文分词难在哪?
从古至今的分词算法:词典到预训练
从中到外的分词工具
对于中文来说,如果不进行分词,那么神经网络将直接基于原始的汉字序列进行处理和学习。然而我们知道一个字在不同的词语中可能含义迥然不同,比如
“哈哈”
与
“哈士奇”
中
“哈”
的含义相去甚远,如果模型在训练阶段没见过
“哈士奇”
,那么预测的时候就有可能以为“哈士奇”所在的句子在表达欢快的气氛了╮( ̄▽ ̄"")╭
显然,要解决上述问题的话,分词就是了,分词之后,最小的输入单位就不再是字了,而是词,由于“哈哈”与“哈士奇”是两个不同的词,自然就不会有前面这个问题啦。因此可以认为,分词缓解了“一字多义”的问题。
除此之外,从特征(feature)与NLP任务的角度来说,字相比词来说,是更原始和低级的特征,往往与任务目标的关联比较小;而到了词级别后,往往与任务目标能发生很强的关联。比如对于情感分类任务,
“我今天走狗屎运了”
这句中的每个字都跟正向情感关系不大,甚至“狗”这个字还往往跟负面情感密切相关,但是“狗屎运”这个词却表达了
“幸运”、“开心”、“惊喜”
的正向情感,因此,分词可以看作是给模型提供了更high-level、更直接的feature,丢给模型后自然容易获得更佳的表现。
答案是,当然可以。从前面分词的目的可以看出,只要模型本身能够学习到字的多义性,并且自己学到由字组词的规律,那么就相当于隐含的内置了一个分词器在模型内部,这时候这个内置的分词器是与解决目标任务的网络部分一起“端到端训练”的,因此甚至可能获得更佳的性能。
然而,从上面这段的描述也能看出,要满足这个条件,是很难得的。这需要训练语料非常丰富,且模型足够大(可以有额外容量来内置一个隐含的分词模型),才有可能获得比“分词器+词级模型“更好的表现。这也是为什么BERT等大型预训练模型往往是字级别的,完全不需要使用分词器。
此外,分词也并不是百利而无一害的,一旦分词器的精度不够高,或者语料本身就噪声很大(错字多、句式杂乱、各种不规范用语),这时强行分词反而容易使得模型更难学习。比如模型终于学会了
“哈士奇”
这个词,却有人把哈士奇打成了“蛤士奇”,结果分词器没认出来,把它分成了
“蛤”、“士”、“奇”
这三个字,这样我们这个已经训练好的“word level模型”就看不到
“哈士奇”
了(毕竟模型训练的时候,“哈士奇”是基本单位)。
1 歧义问题
首先,前面提到分词可以缓解“一字多义”的问题,但是分词本身又会面临“切分歧义”的问题。

虽然切分成《无线电/法国/别/研究》看起来没毛病,但是考虑到这是个书名,显然正解《无线电法/国别/研究》对分词器来说太南了(。 ́︿ ̀。)而如果不告诉你这是一个书名,显然两种切分方式看起来都没毛病。
2 未登录词问题
此外,中文词典也是与时俱进的,例如“青青草原”、“累觉不爱”等网络词在10年前是没有的,今天训练的分词器也一定会在不久的将来遇到不认识的词(即“未登录词”,out-of-vocabulary word),那个时候分词器很容易因为“落伍”而出现切分错误。
3 规范问题
最后,分词时的切分边界也一直没有一个确定的规范。尽管在 1992 年国家颁布了《信息处理用现代词汉语分词规范》,但是这种规范很容易受主观因素影响,在实际场景中也难免遇到有所不及的问题。
对于中文分词问题,最简单的算法就是基于词典直接进行greedy匹配。
比如,我们可以直接从句子开头的第一个字开始查字典,找出字典中以该字开头的最长的单词,然后就得到了第一个切分好的词。比如这句“夕小瑶正在讲NLP”,查字典发现“夕小瑶”是最长的词了,于是得到
夕小瑶/正在讲NLP
然后从下一个词的开头开始继续匹配字典,发现“正在”就是最长的词了,于是
夕小瑶/正在/讲NLP
依此类推,最终得到
夕小瑶/正在/讲/NLP
这种简单的算法即为前向最大匹配法(FMM)
虽然做法很朴素,但是名字听起来还有点高端╮(╯▽╰)╭
不过,由于中文句子本身具有重要信息后置的特点,从后往前匹配的分词正确率往往要高于从前往后,于是就有了反向进行的“后向最大匹配法(BMM)”。
当然了,无论是FMM还是BMM,都一定存在不少切分错误,因此一种考虑更周到的方法是“双向最大匹配”。
双向最大匹配算法是指对待切分句子分别使用FMM和RMM进行分词,然后对切分结果不重合的歧义句进行进一步的处理。通常可对两种方法得到的词汇数目进行比较,根据数目的相同与否采取相应的措施,以此来降低歧义句的分词错误率.
2 基于统计
2.1 基于语言模型
基于词典的方法虽然简单,但是明显能看出来太!不!智!能!了!稍微复杂一些的句子,例如“没关系,除夕小瑶在家做饭。”,这时候如果使用后向最大匹配法,就会切分成“没关系/,/除/夕小瑶/在家/做饭/。”,这明显错的很不可原谅。
犯这种错误的根本原因在于,基于词典的方法在切分时是没有考虑词语所在的上下文的,没有从全局出发找最优解。其实上面这个句子无非就是在纠结两种切分方式:
我们日常说话中很少会有人说出“没关系/,/除/xxxx/做饭/。”这种句子,而第二个句子出现的频率则会非常高,比如里面的“小瑶”可以替换成“我”、“老王”等。显然给定一个句子,各种切分组合是数量有限的,如果有一个东西可以评估出任何一个组合的存在合理性的分值,那么不就找到了最佳的分词组合嘛!
所以,这种方法的本质就是在各种切词组合中找出那个最合理的组合,这个过程就可以看作在切分词图中找出一条概率最大的路径:
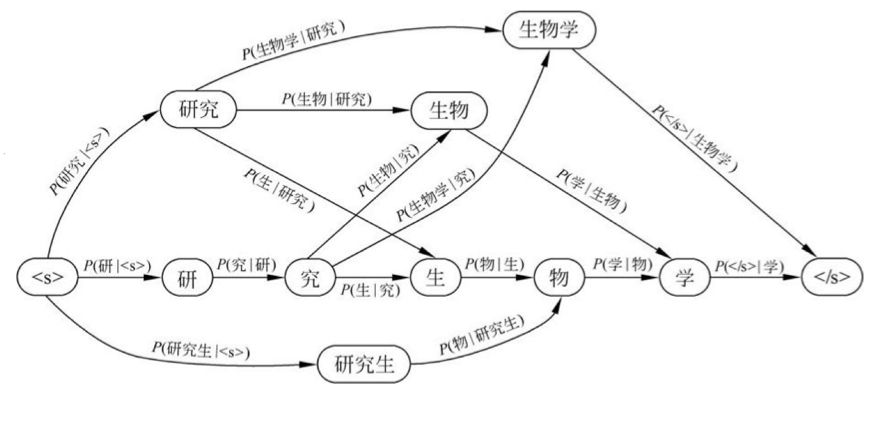
而这个可以给词序列存在合理性打分的东西就叫做“语言模型”(language model)。这种利用语言模型来评估各种切分组合的方法是不是就显得智能多啦╮(╯▽╰)╭
给定一个句子分词后得到的单词序列{w1,w2...wm},
语言模型就能计算出这个句子(或者说词序列)存在的可能性:
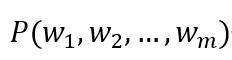
显然,当m取值稍微一大,乘法链的后面几项会变得非常难计算(估计出这几项的概率需要依赖极其庞大的语料才能保证估计误差可接受)。计算困难怎么办?当然是用合理的假设来简化计算,比如我们可以假设当前位置取什么词仅取决于相邻的前面n个位置,即
这种简化的语言模型就称为n-gram语言模型。这样乘法链中的每个乘子都可以在已经完成人工标注的分词语料中计算得到啦。当然了,在实际计算中可能还会引入一些平滑技巧,来弥补分词语料规模有限导致的估计误差,这里就不展开讲啦。
2.2 基于统计机器学习
NLP是一门跟机器学习强绑定的学科,分词问题自然也不例外。中文分词同样可以建模成一个“序列标注”问题,即一个考虑上下文的字分类问题。因此可以先通过带标签的分词语料来训练一个序列标注模型,再用这个模型对无标签的语料进行分词。
样本标签
一般用{B:begin, M:middle, E:end, S:single}这4个类别来描述一个分词样本中每个字所属的类别。它们代表的是该字在词语中的位置。其中,B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词。
人/b 们/e 常/s 说/s 生/b 活/e 是/s 一/s 部/s 教/b 科/m 书/e
之后我们就可以直接套用统计机器学习模型来训练出一个分词器啦。统计序列标注模型的代表就是生成式模型的代表——隐马尔可夫模型(HMM),和判别式模型的代表——(线性链)条件随机场(CRF)。已经对这两个模型很熟悉的小伙伴可以跳过。
隐马尔可夫模型(HMM)
HMM模型的详细介绍见
《)》 /
在了解了HMM模型的基本概念之后,我们来看看HMM模型是如何进行分词的吧~
基本思路:将分词问题转换为给每个位置的字进行分类的问题,即序列标注问题。其中,类别有4个(前面讲到的B、M、E、S)。给所有的位置分类完成后,便可以根据类别序列得到分词结果啦。
举个栗子!
那么问题又来了,假如一个完美的HMM分词模型给你了,那么如何用这个模型对输入的字序列进行序列标注呢?
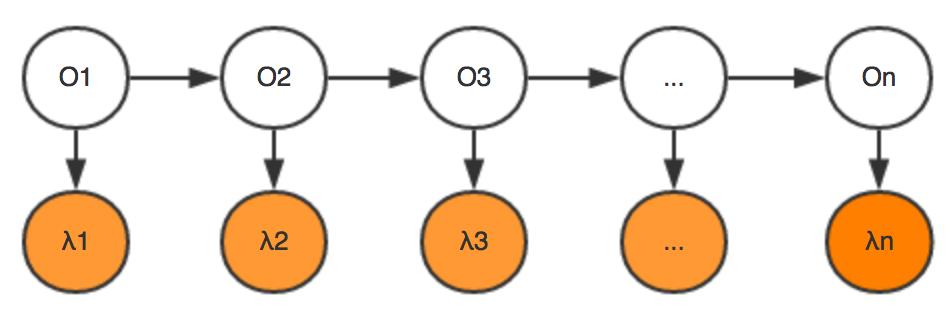
首先看下HMM模型中的两个核心概念:观测序列和状态序列。
观测序列就是我可以直接看到的序列,也就是“
小Q硕士毕业于中国科学院
”这个字序列,而状态序列则是不能通过肉眼直接观察到的内在序列,也就是上面这句话所对应的标注结果“
BEBEBMEBEBME
”,而我们的HMM模型,就可以帮助我们完成从观测序列->状态序列的华丽变身!
用数学抽象表示如下:用
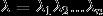 代表输入的句子,n为句子长度,
代表输入的句子,n为句子长度,
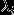 表示字,
表示字,
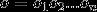 代表输出的标签,那么理想的输出即为:
代表输出的标签,那么理想的输出即为:
我们的理想输出的是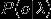 ,通过贝叶斯公式能够得到:
,通过贝叶斯公式能够得到:
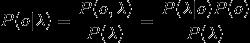
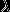 为给定的输入,因此
为给定的输入,因此
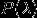 计算为常数,可以忽略,因此最大化
等价于最大化
计算为常数,可以忽略,因此最大化
等价于最大化
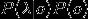 .
可是,上面这个式子也太难算了吧!!!为此,聪明的科学家们引入了两个可以简化计算的假说:
观测独立性假设:每个字的输出仅仅与当前字有关,即每个λ的值只依赖于其对应的O值,即
齐次马尔可夫假设:每个输出仅仅与上一个输出有关,即Oi的值只依赖于Oi-1,即
在HMM中,将
.
可是,上面这个式子也太难算了吧!!!为此,聪明的科学家们引入了两个可以简化计算的假说:
观测独立性假设:每个字的输出仅仅与当前字有关,即每个λ的值只依赖于其对应的O值,即
齐次马尔可夫假设:每个输出仅仅与上一个输出有关,即Oi的值只依赖于Oi-1,即
在HMM中,将
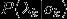 称为观测概率,
称为观测概率,
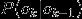 称为转移概率。通过设置某些
称为转移概率。通过设置某些
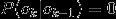 ,可以排除类似BBB、EM等不合理的组合。
,可以排除类似BBB、EM等不合理的组合。
最后,求解
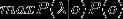 的常用方法是Veterbi算法。它是一种动态规划方法,核心思想是:如果最终的最优路径经过某个
的常用方法是Veterbi算法。它是一种动态规划方法,核心思想是:如果最终的最优路径经过某个
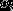 ,那么从初始节点到
,那么从初始节点到
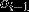 点的路径必然也是一个最优路径。当然啦,这一切的前提是HMM中的模型参数都已经被训练好了,而训练这些模型参数可以通过万能的极大似然估计来从有标签的分词语料中学习得到,这里就不展开赘述啦,对细节不清楚的小伙伴可参考本小节开头给出的两篇文章。
点的路径必然也是一个最优路径。当然啦,这一切的前提是HMM中的模型参数都已经被训练好了,而训练这些模型参数可以通过万能的极大似然估计来从有标签的分词语料中学习得到,这里就不展开赘述啦,对细节不清楚的小伙伴可参考本小节开头给出的两篇文章。
条件随机场 (CRF)
HMM隐马模型有一个非常大的缺点,就是其存在输出独立性假设,导致其不能将上下文纳入特征设计,大大限制了特征的可用范围。CRF则没有这个限制,它不对单独的节点进行归一化,而是对所有特征进行全局归一化,进而全局的最优值。因此,在分词问题上,显然作为判别式模型的CRF相比HMM更具优越性。
HMM模型围绕的是一个关于序列X和Y的联合概率分布以上是关于中文分词的古今中外,你想知道的都在这里的主要内容,如果未能解决你的问题,请参考以下文章
中文分词技术全解析,你想知道的都在这里(附开源工具)
关于Flutter,你想知道的都在这里了!
Swift具体解释之三----------函数(你想知道的都在这里)
Java基础“线程池”-你想知道的都在这里
关于Oracle Sharding,你想知道的都在这里
#yyds干货盘点# 关于并发编程-AQS,你想知道的都在这里