HMM 中文分词
Posted NLP与人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HMM 中文分词相关的知识,希望对你有一定的参考价值。
HMM 中文分词
假设系统拥有不同的状态,每个时刻状态都会发生变化,我们可以用马尔科夫模型总结出系统状态变化的规律。以天气变化为例,现在有三种天气 {晴天,雨天,多云},和很多天的天气状态序列 D1, D2, D3,..., DM。则我们可以根据前 n 天的天气,预测第 M+1 个天气状态的概率。

这也称为 n 阶马尔科夫模型,即当前状态仅依赖于前面 n 个状态,通常比较常用的是一阶马尔科夫模型,即当前预测的状态仅依赖于前一时刻的状态。
一阶马尔科夫模型可以定义一个状态转移矩阵 T,T 的行数和列数均等于状态个数,T 描述了从一个状态转移到另一个状态的概率,如下图所示。

即如果今天是雨天,则明天是晴天的概率是 0.3。除了状态转移矩阵,还需要定义一个初始概率向量 I,表示第一天时,每种天气状态的概率。初始概率向量如下:

总的来说,定义一个一阶马尔科夫模型需要:
状态:晴天、雨天、多云
状态转移矩阵 T
初始概率向量 I
马尔科夫模型还有一个性质,不管今天的天气如何,在很多天之后的状态分布会收敛到一个固定的概率分布,称为稳态分布。例如第一天是晴天,给定的 T 如上文所示,则很多天 (n天) 之后的概率分布 p 为:
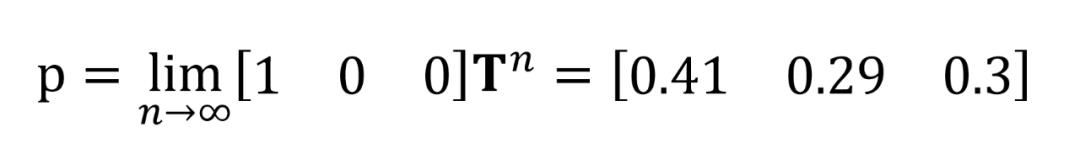
这是因为 T 自乘无穷次之后,每一行的数值都是一样的,因此不管第一天天气如何,无穷天后的概率分布都是稳定的。
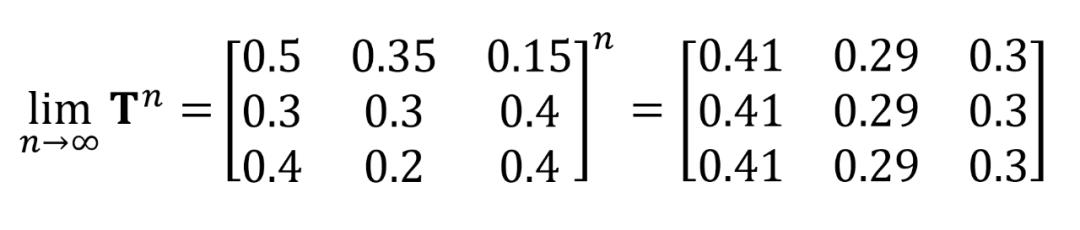

有的时候我们只能看到观察的序列,而不能直接看到隐藏的状态,此时就需要使用隐马尔科夫模型。例如有一个被关在一个密闭的房间里,没办法查看到天气,但是可以通过一个湿度计查看湿度。
由于湿度 (观察状态) 和天气 (隐藏状态) 之间存在联系,HMM 可以根据给出的观测状态序列,估计出对应的隐藏状态序列,同时可以对未来的隐藏状态和观察状态进行预测。
隐马尔科夫模型还需要增加一个发射概率矩阵 E,E 的行数等于隐藏状态个数,列数为观察状态个数,Eij 表示隐藏状态为 i 时,观察状态为 j 的概率。
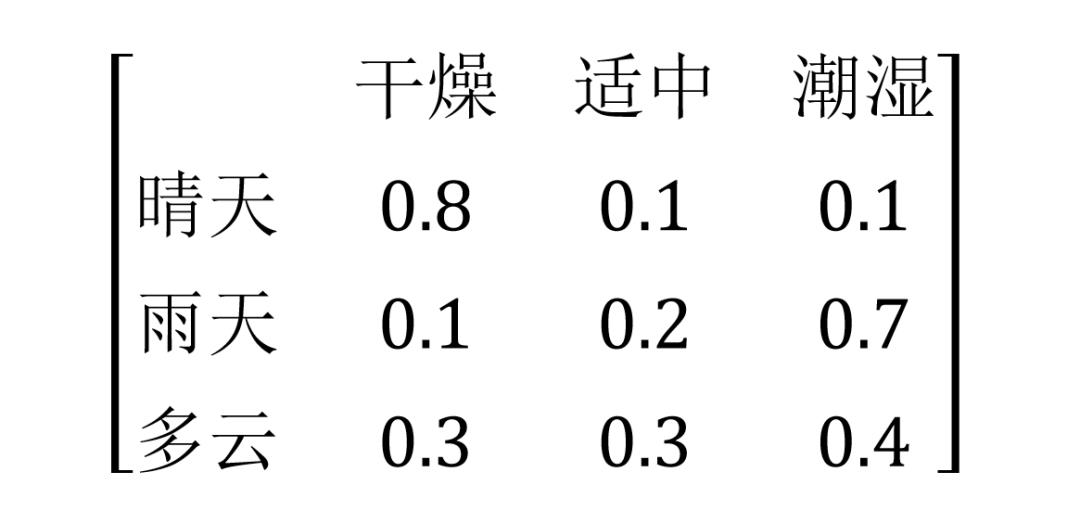
总的来说,定义一个一阶隐马尔科夫模型以下参数,这些就是 HMM 的参数:
隐藏状态 S:晴天、雨天、多云
观察状态 O:干燥、适中、潮湿
状态转移矩阵 T
初始概率向量 I
发射概率矩阵 E
隐马尔科夫模型比较常见的三个问题分别是:评估问题,解码问题和学习问题。
评估问题:我们已经知道模型的参数 (S, O, T, I, E),给定一个观测序列 X (例如 干燥、干燥、潮湿、....、适中),评估问题要计算出得到这样一个观测序列 X 的概率值。求解评估问题的方法有前向算法和后向算法。
解码问题:已经知道模型的参数 (S, O, T, I, E),给定一个观测序列 X,找出使观测序列概率最大的隐藏状态序列 Y。求解的方法有 Viterbi 算法。
学习问题:学习问题是指在未知模型参数的时候,通过数据集学习出模型的参数 (S, O, T, I, E)。学习问题包监督学习方法和非监督学习方法,如果我们同时拥有观察序列 X 和状态序列 Y,则可以采用监督学习;如果只有观测序列 X,则只能采用非监督学习,非监督学习的算法有 Baum-Welch 算法。
HMM 可以用于中文分词的任务,其隐藏状态包含 4 种,分别是 SBME,S 表示单个字的词,而 B 表示多字词的第一个字,M 表示多字词中间的字,E 表示多字词最后一个字,如下图所示。

用 HMM 进行中文分词,要通过观察序列找出最有可能的隐藏状态序列,主要涉及学习问题和解码问题。
可以使用已经标注好的数据 (即有观察序列 X 和隐藏状态序列 Y) 的数据集进行有监督学习。数据集包含很多句子,每个句子都有 X 和 Y。那么我们就可以通过统计得到 HMM 的状态转移矩阵、发射矩阵和初始概率向量。
状态转移矩阵 T:Tij 表示从状态 i 转移到状态 j 的概率,需要统计数据集里面从状态 i 转移到 状态 j 的个数 Aij,然后除以状态 i 转移到所有状态的个数 Ai。
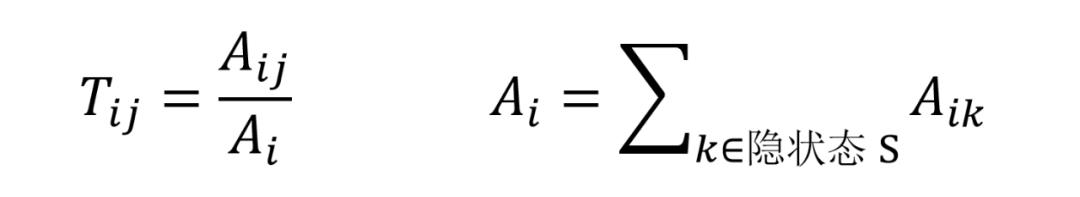
例如我们可以用下面的公式计算从状态 B 转到状态 E 的概率:
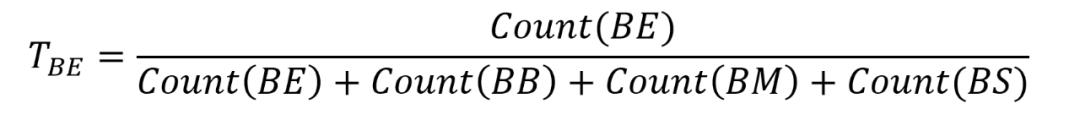
中文分词的时候是不存在从状态 B 到状态 B 的,也不存在 B 到 S,所以 Count(BB) 和 Count(BS) 都是 0。
发射概率矩阵 E:Eij 表示在状态 i 时得到观察值 j 的概率。计算方法是统计状态 i 且观察值为 j 的个数 B,然后除以状态 i 的个数。
初始概率向量 I:I 只要统计每个句子第一个状态,得到第一个状态的概率分布即可。
在学习得到 HMM 的参数后,可以通过 HMM 解码算法 (Viterbi 算法) 求解出句子的隐状态,最终分词。具体做法可以参考《统计学习方法》。
《统计学习方法》
 NLP与人工智能
NLP与人工智能
微信ID:NLP_Learning

长按二维码关注
以上是关于HMM 中文分词的主要内容,如果未能解决你的问题,请参考以下文章