无监督中文分词算法近年研究进展
Posted PaperWeekly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无监督中文分词算法近年研究进展相关的知识,希望对你有一定的参考价值。

SLM

论文标题:
Unsupervised Neural Word Segmentation for Chinese via Segmental Language Modeling
论文来源:
EMNLP 2018
论文链接:
https://arxiv.org/abs/1810.03167
代码链接:
https://github.com/Edward-Sun/SLM
本文首次提出了基于神经网络的无监督中文分词模型,并在 SIGHAN 2005 分词竞赛的四个不同数据集上实现了最先进的统计模型性能。以往的无监督分词模型可大致分为判别模型和生成模型。前者使用精心设计的有效方法(互信息,nVBE,MDL 等等)来进行候选词分割,而后者侧重于为中文设计统计模型,并找到生成概率最高的最优分割。
1.1 Segmental Language Models
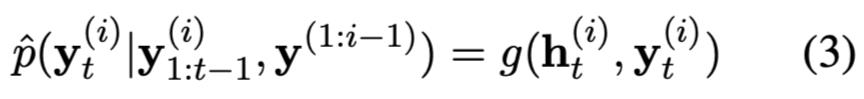

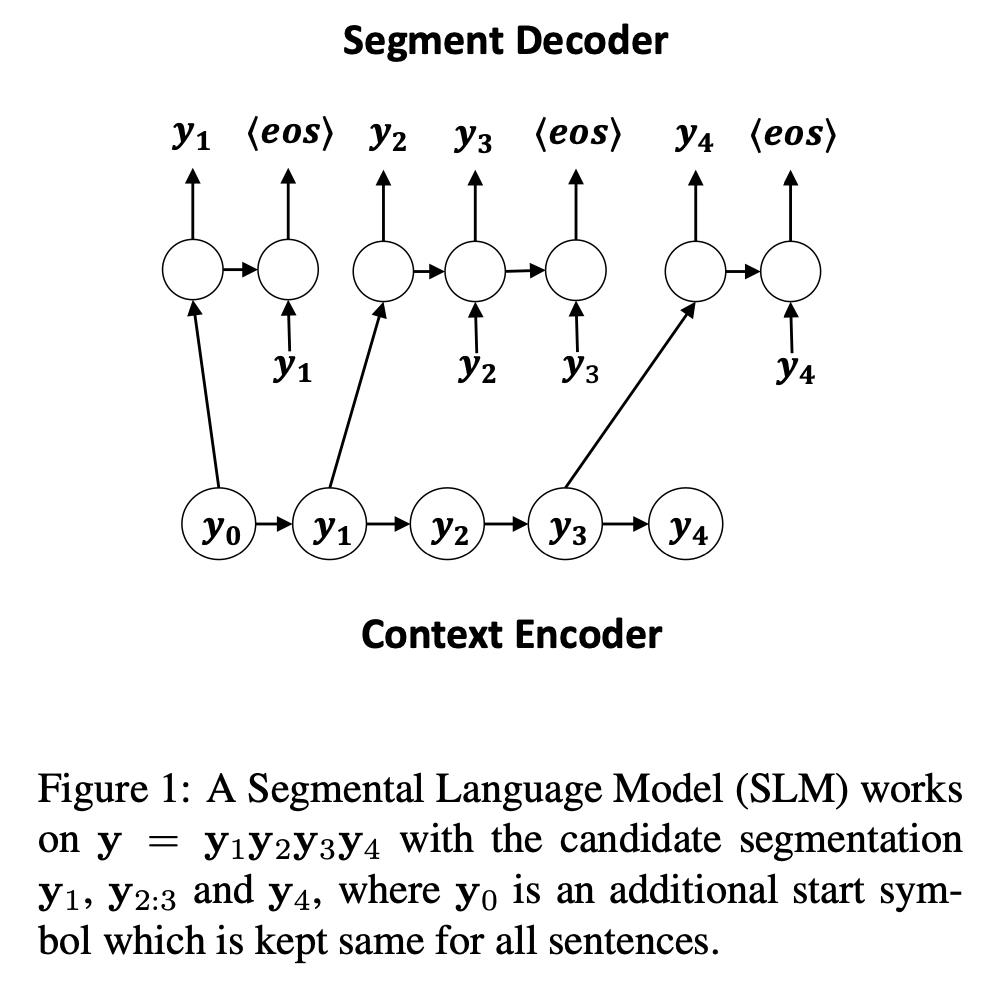
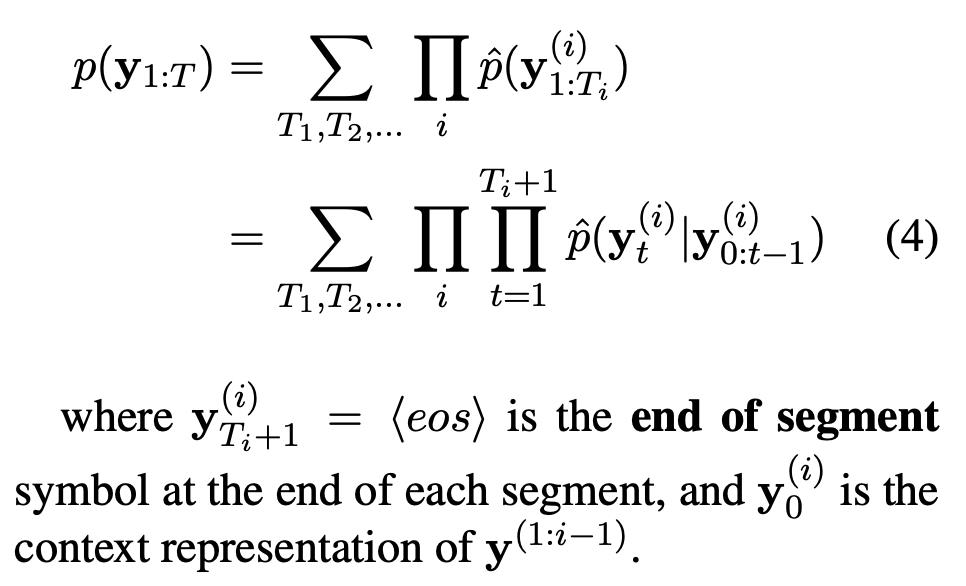
1.2 实验结果
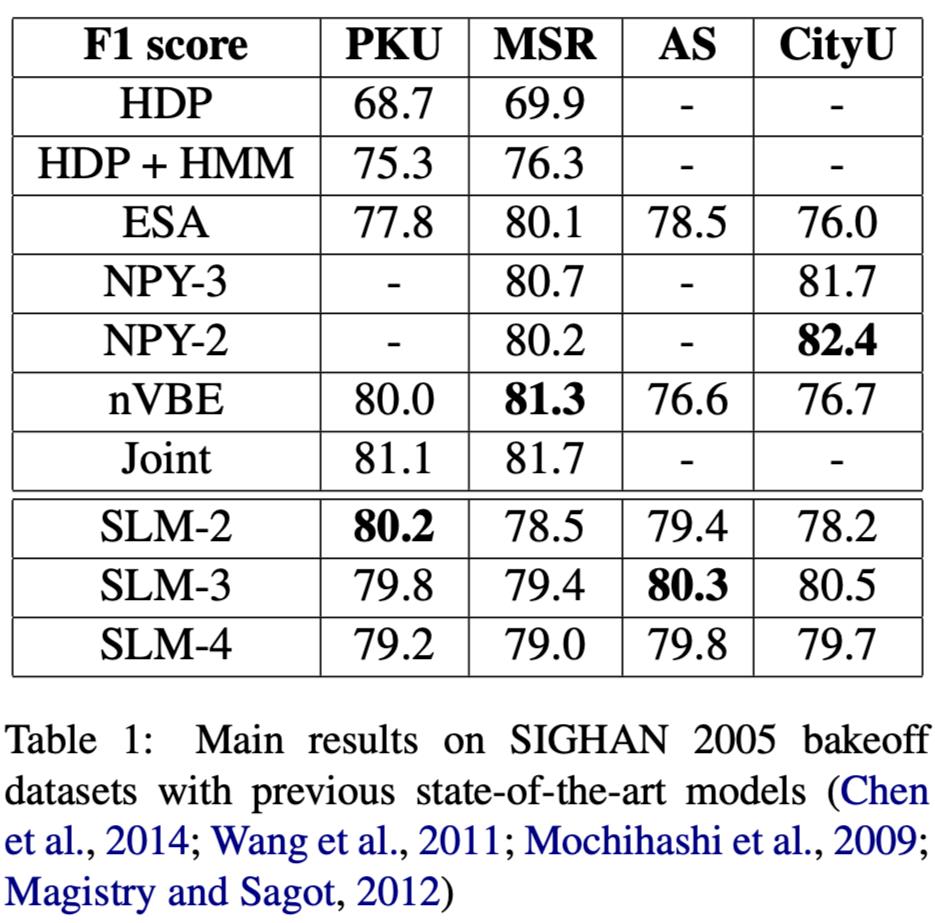
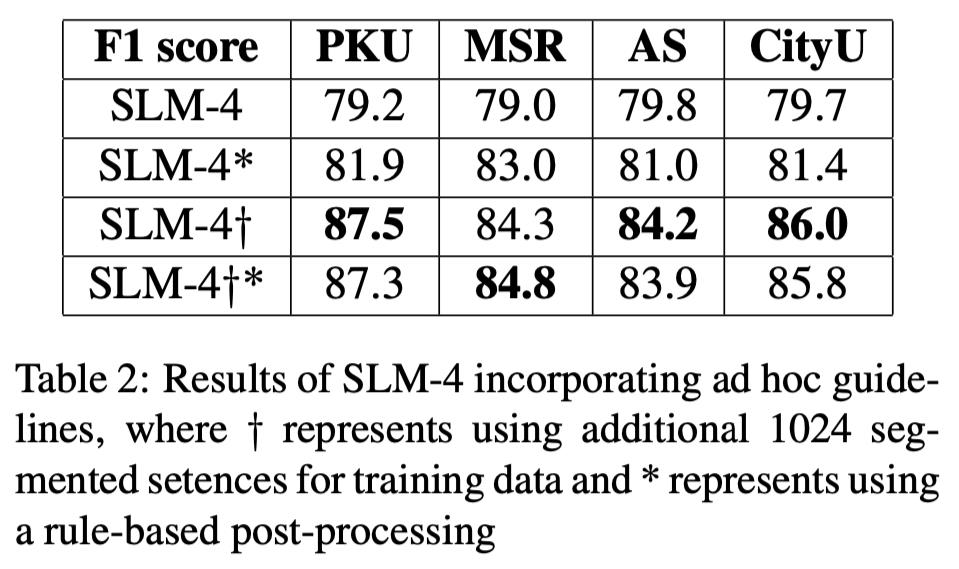
从表 1 可以看出,SLMs 在 PKU 和 AS 数据集上优于以往最好的判别和生成模型。这可能是由于 SLM 模型的分割准则更接近这两个数据集(模型名称后面的数字表示的是最大切分长度)。
1.3 总结


2.1 Intro
2.2 Contributions
在中文中,我们对于分词有一个基本的直觉:在同一个上下文窗口内的单词组合应该彼此接近。也就是说,如果一个序列的切分不正确,那么这些切分错误的词很可能在语义和句法上与其周围的词不一致。因此,一个不正确的分词的 embedding 应该远离它周围词的 embedding。
-
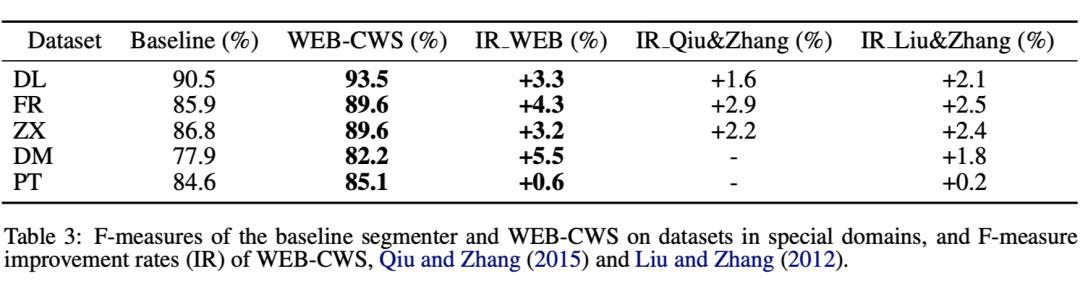
基于以上假设,作者提出了一种基于 word-embedding 的半监督分词方法——WEB-CWS(Word-Embedding-Based CWS),该方法还可以实现 cross-domain 的分词。 -
作者在多个数据集中验证了该方法的有效性(e.g., novels, medicine, and patent)。
2.3 Word-Embedding-Based CWS
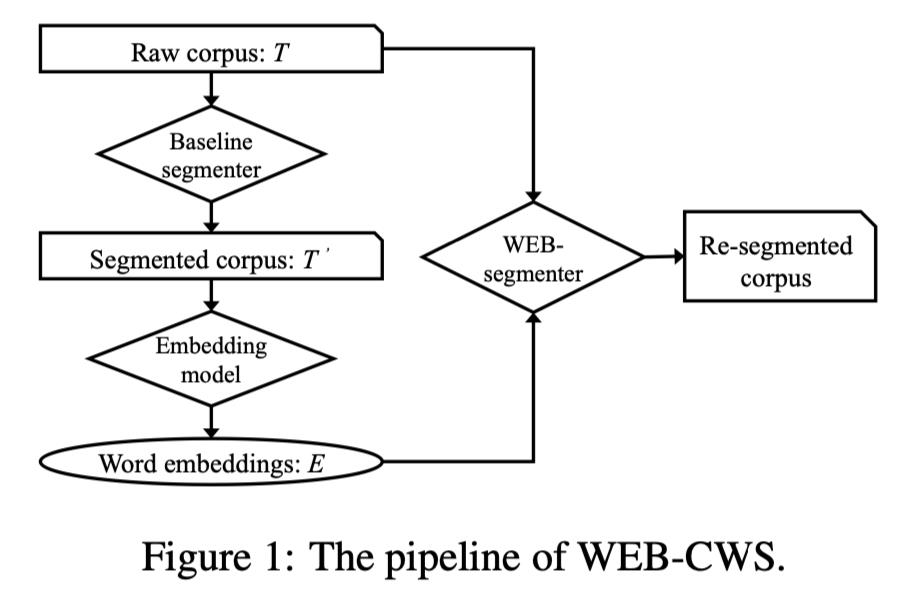
模型整体流程如上图。
-
首先会有一个 taget domain 的 raw corpus,我们将其定义为语料 T ,然后使用作为 beseline 的 segmenter 去分词,分完词之后得到语料 T'。 -
然后在 T' 上利用基于 word-embedding 的分词方法(WEB-CWS)得到一组单词的 embeddings E。此外,所有在 T' 中的 token 组合成一个 taget domain 的字典 D。 -
最后,E 和 D 使用基于单词嵌入的 segmenter 对 T 进行重新分割。
2.3.1 CWS-Oriented Word Embedding Model
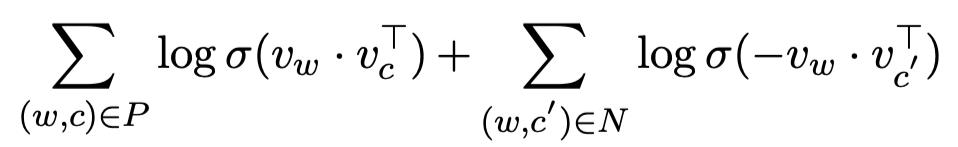
作者为了让模型更加适配 CWS 任务,做了以下几点修改:
添加面向 CWS 的负样本;Skip-gram 将词 w 的 context 在 window 里的词作为正样本,在本论文中,给定目标词 w 及其上下文 C,并将 SL 和 SR 作为 C 中 w 左右的字符序列,对于 SL 或 SR 的任意子串 s' 在字典 D 中,而不在 C 中,那么(w, s')会被看做一个负样本。
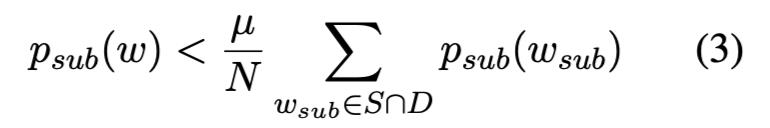
通过这样做,可以保留那些子字符串本身就是更常见单词的多字符单词。
规范化嵌入的点积;在原始的 skip-gram 模型中,直接使用两个单词的嵌入量的点积作为 sigmoid 层的输入。为了使基于 CWS 的单词嵌入模型导出的单词嵌入更符合上述用于分割的 metric,作者将原目标函数的训练目标修改为基于 dot-product 的目标函数:
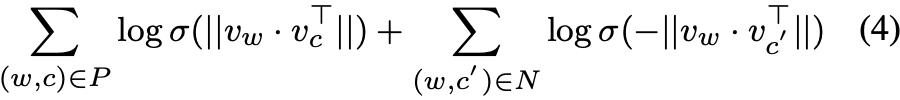
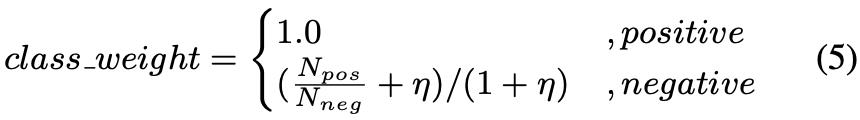
2.3.2 Word-Embedding-Based Segmentater
在这一步,作者将序列分词的过程建模为一个基于假设的维特比解码过程。
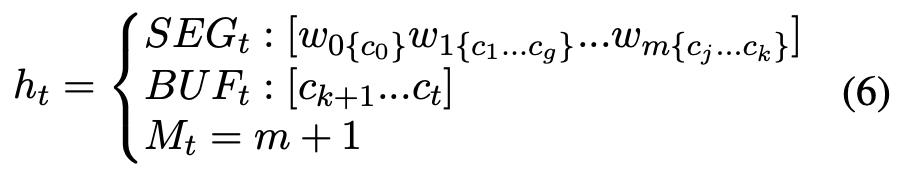
概率计算:
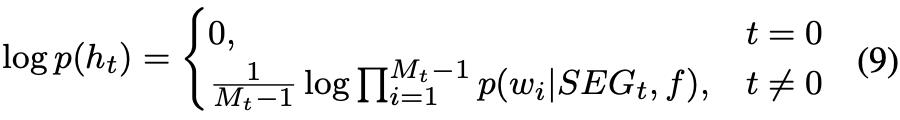
2.4 Experiment
2.5 总结


论文标题:
Improving Chinese Segmentation-free Word Embedding With Unsupervised Association Measure
论文链接:
https://arxiv.org/abs/2007.02342
目前很多神经网络模型不再将分词作为解决问题的首要步骤,而是通过直接学习每个词的 embedding 来解决具体任务。但是使用这种方式在词汇中会存在大量的的噪声 n-gram,并且这些 n-gram 在字符之间没有很强的关联强度,一定程度上限制了 embedding 的质量。
3.1 Methods
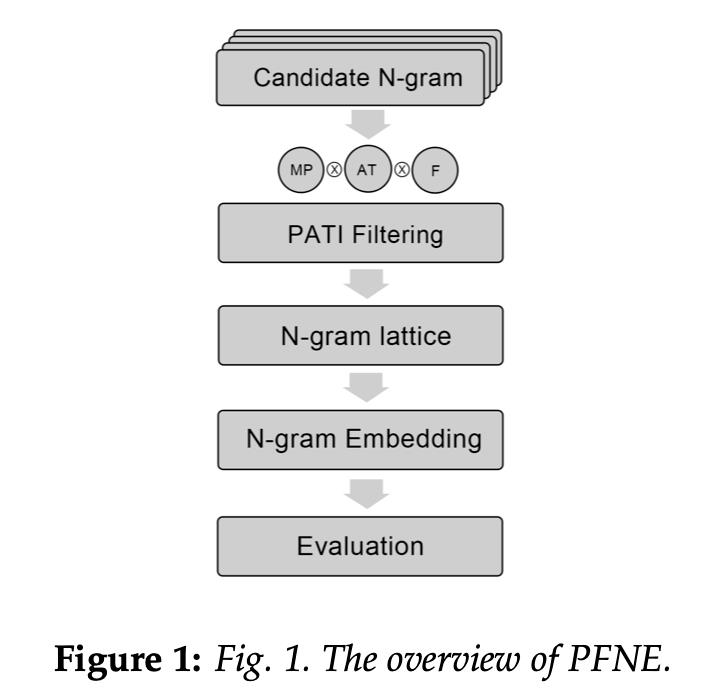
3.1.2 PATI
作者提出了一种无监督的 n-gram 关联度量方法——pointwise association with times information(PATI):
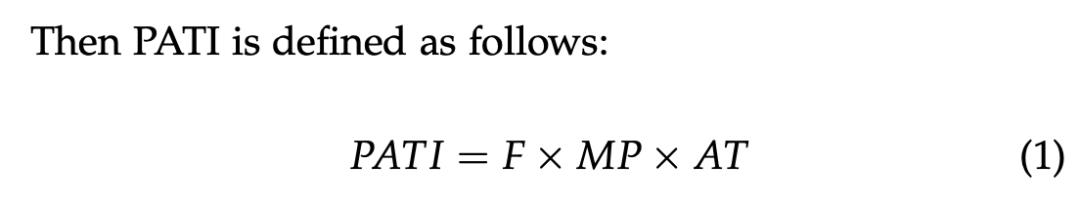
其中 F 是 n-gram:g 出现的频率。
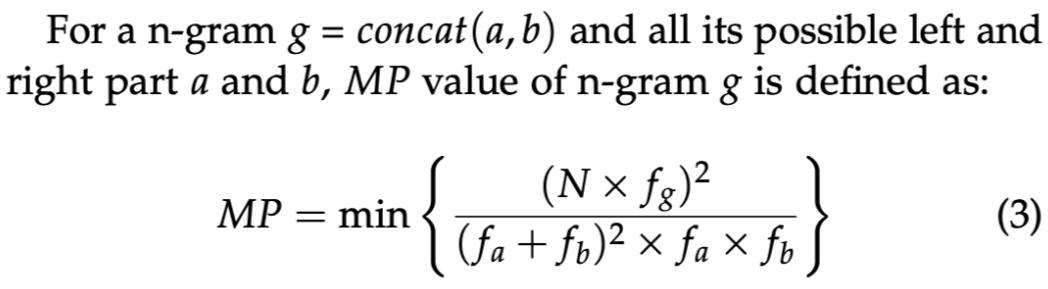

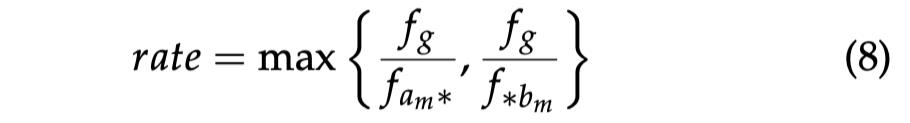
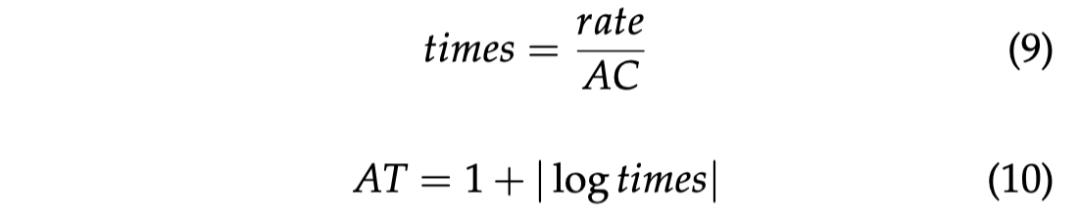
3.1.3 PATI FILTERED N-GRAM EMBEDDING MODEL
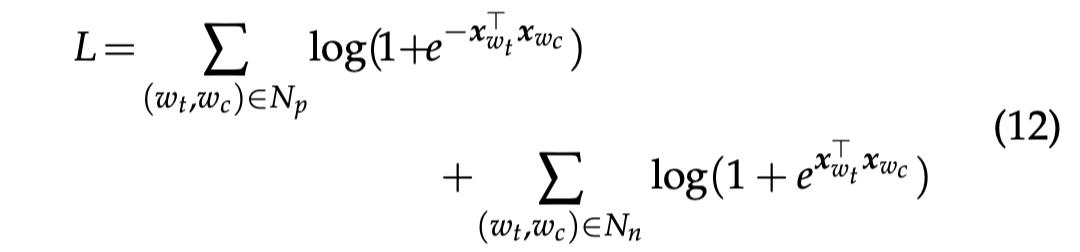
3.2 总结
更多阅读

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
以上是关于无监督中文分词算法近年研究进展的主要内容,如果未能解决你的问题,请参考以下文章