引入中文分词信息的中文命名实体识别
Posted PKUFineLab
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了引入中文分词信息的中文命名实体识别相关的知识,希望对你有一定的参考价值。
Future丨Intelligence丨Nutrition丨Energy
让阅读成为习惯,让灵魂拥有温度
点击关注PKUFineLab

一起进步

引入中文分词信息的
中文命名实体识别
01
01
简述
命名实体识别(NER,Named Entity Recognition),是自然语言处理中的一项基础任务。命名实体一般指在文本中具有特定意义或者指代性强的实体,例如人名、地名、组织名等。命名实体识别的目的是从非结构化的文本里抽取出任务指定的实体,如上述的人名,或者是一些特定领域的实体,比如歌曲名。在一般的自然语言应用中,常将命名实体识别作为关系抽取、问答系统、知识图谱构建的前置任务。
目前,在命名实体识别任务中,深度学习方法逐渐替代传统的基于规则和基于特征的方法,常见的深度学习网络结构如下图所示,使用循环神经网络(RNN)或卷积神经网络(CNN)对输入的单词序列进行特征提取,然后使用条件随机场(CRF)进行解码。同时,为了减少未登录词的影响,一般会引入字符特征,字符特征同样使用RNN或CNN的网络进行提取,得到字符特征后与单词序列拼接,再进入下一层网络。
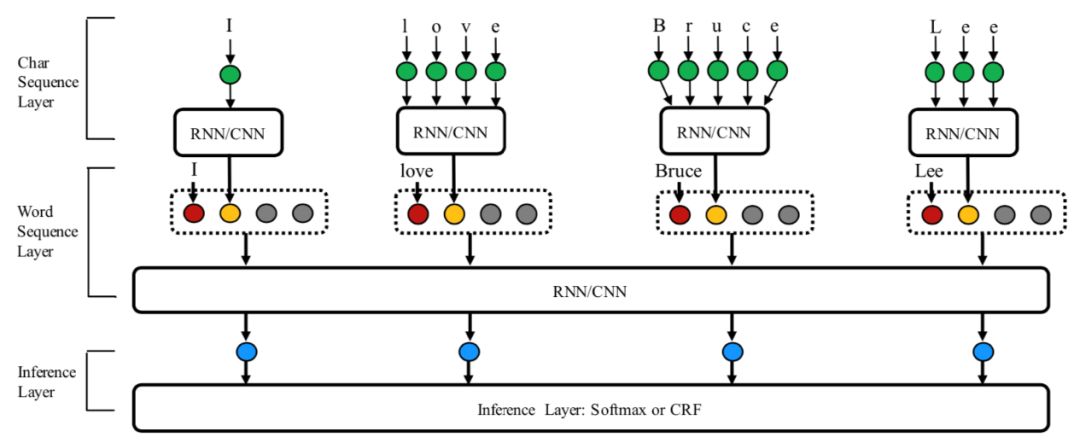
图 1
上述介绍的网络结构,如果直接应用在中文命名实体识别中,会存在一定的问题,因为中文和英文不同,中文的最小单元是字,而上述网络中的输入是词。如果使用这种网络结构进行命名实体识别,则需要先对中文输入进行分词,再进行实体识别。但是,这种先分词再实体识别的方法,如果在分词阶段产生了错误,则会将错误传递给下游的实体识别部分,得到错误的实体识别结果。所以,在中文命名实体识别任务中,比较常用的方法是基于字符的命名实体识别。
01
02
引入中文分词信息
但在中文命名实体识别任务中,基于字符的命名实体识别的任务效果往往要低于基于词的方法,因为在中文中单个字符的表现力不足,同时因为缺少词的边界信息,模型要同时学习区分词的边界和识别实体类型两个目标。所以,如何在基于字符的命名实体识别任务中,加入词信息,来提升实体识别效果,是目前中文命名实体识别任务中一项重要的工作。本文主要介绍其中一类通过多任务学习,将中文命名实体识别和中文分词任务联合学习的方法。
中文分词任务(CWS,Chinese Word Segmentation)是中文自然语言处理特有的任务,目的是从非结构化的文本中,划分出词与词之间的边界。大多数基于深度学习的中文分词模型都是将分词任务定义为序列标注任务,使用和命名实体识别类似的网络结构(LSTM+CRF)来进行分词。分词任务中的特征提取部分,提取的是词的边界特征,这也是基于字符的中文命名实体识别任务所需要的。
基于这种动机,有研究者[1]提出了基于多任务学习的思想,将中文命名实体识别模型和中文分词模型进行联合学习,两个模型,因为都是以字符作为输入,且两个模型的结构类似,所以,将两个模型的嵌入层(Embedding)和特征提取层(LSTM)参数共享,在中文分词任务中提取到的词的边界特征,能够通过多任务学习应用在中文命名实体识别任务中,在基于字符的中文命名实体识别任务中加入词的边界信息,提高模型的实体识别效果,模型的结构如下。
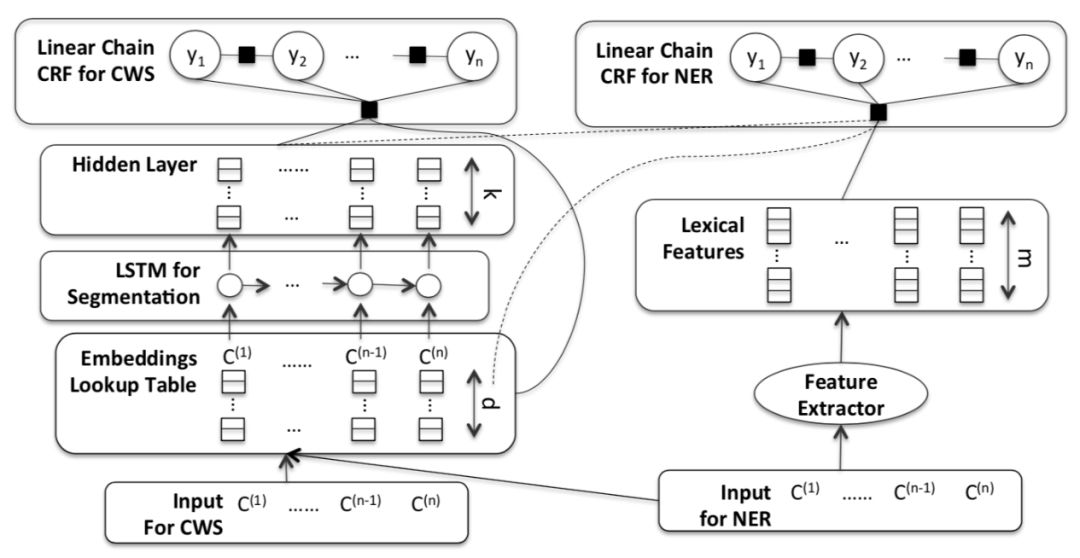
图2
在上述工作的启发下,有研究者[2]对上述的网络结构进行了优化,新的网络结构如下图所示,还是基于多任务学习的思想,两个任务共享嵌入层,然后经过一个共享的CNN模型,提取特征,得到的特征再通过LSTM+CRF做命名实体识别,同时这部分特征也会通过另外一个CRF模型做中文分词。这种新的模型与上一个工作不同的是,作者没有共享LSTM,而是选择共享CNN。原因是,在中文命名实体识别和中文分词任务中,决定一个字符的实体类型和分词边界,更多是取决于相邻的字符。由于CNN更擅长提取局部的上下文特征,所以共享CNN的效果要优于共享LSTM。
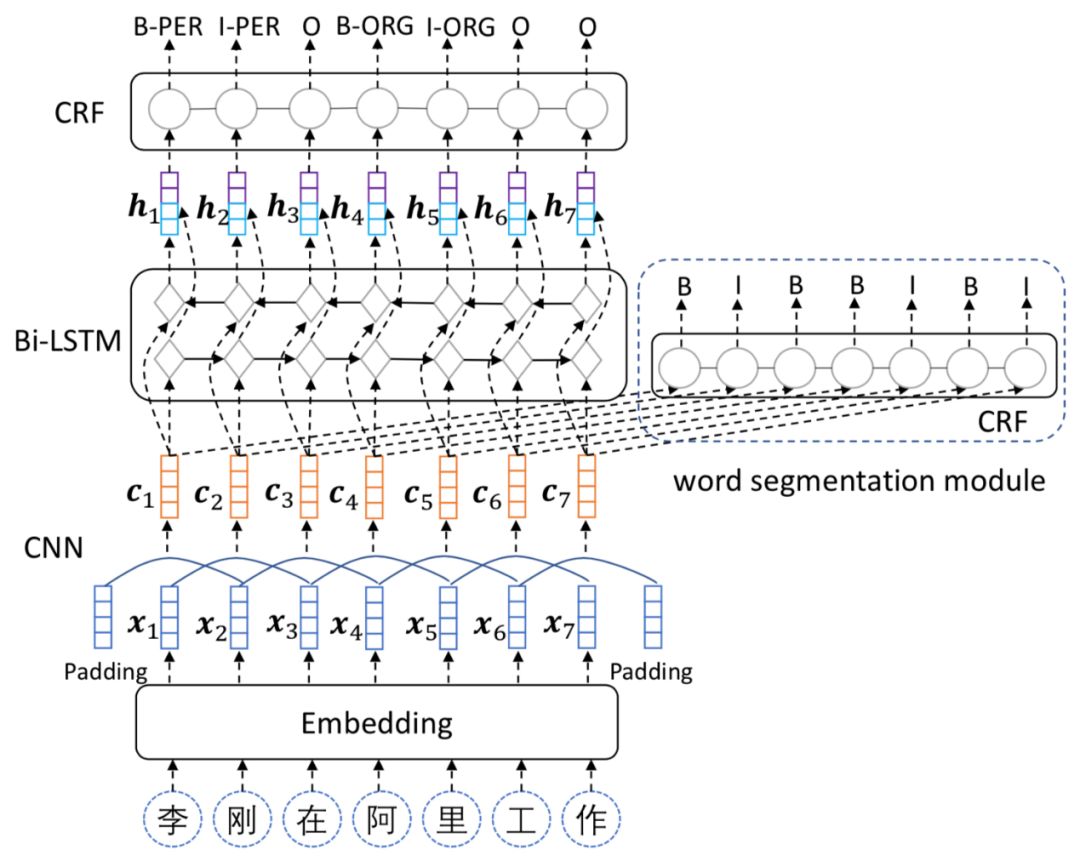
图3
基于多任务的模型结构虽然能够将中文分词任务的特征应用在中文命名实体识别任务中,但是也会将实体识别无关的特征引入到其中,这种任务无关的特征会对实体识别造成干扰。为了解决这一问题,有研究者[3]将对抗学习应用在上述的模型结构中,新的模型结构如下图所示,中文命名实体识别任务和中文分词任务分别使用一个LSTM网络进行任务特有的特征提取,然后使用一个共享的LSTM网络提取两个任务希望共享的特征,然后将提取到的共享的特征与任务特有的特征进行拼接,再使用CRF进行解码。其中,对抗学习应用在提取共享特征的部分,通过一个判别器来对共享特征进行区分,模型的目标是使判别器不能够区分共享特征来自于命名实体识别任务还是中文分词任务,即提取到两个任务共享的特征。
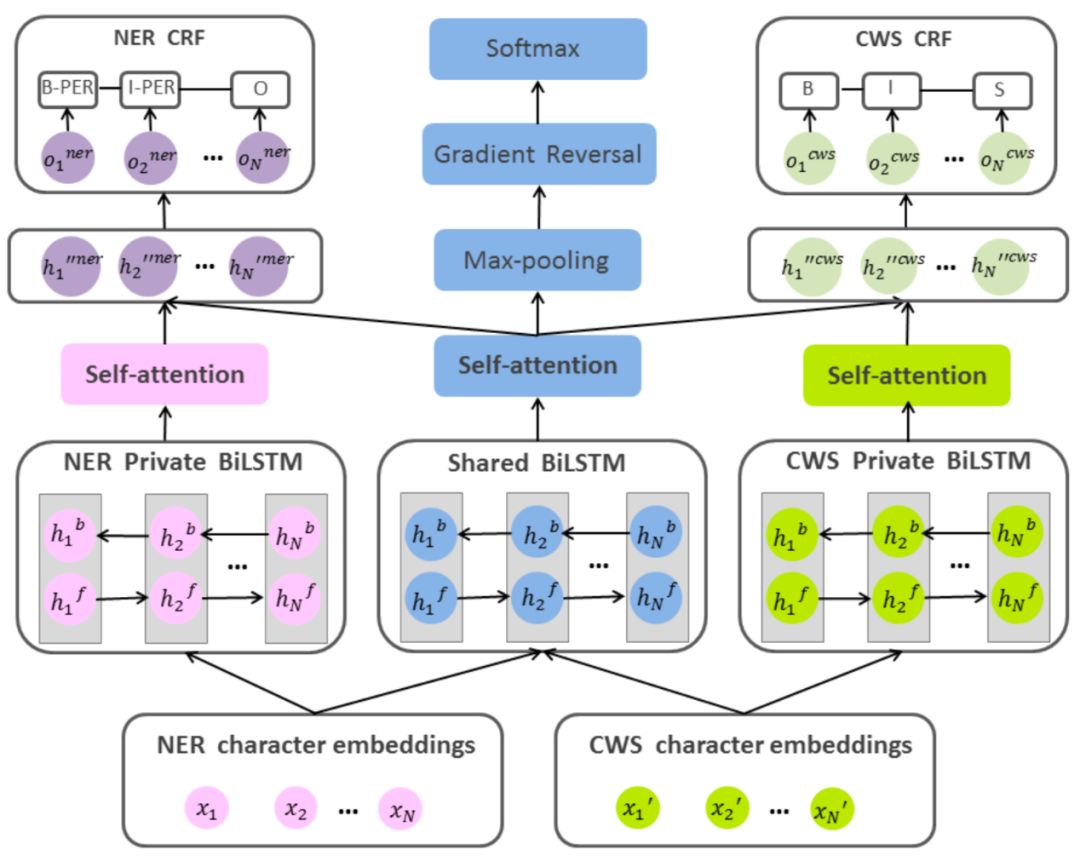
图4
上述的工作,目的是将中文分词特征引入到基于字符的中文命名实体识别任务中,来帮助区分词与词之间的边界,除了以上基于多任务学习的方法,还有一些其他工作,使用了不同的方法引入词的特征,比如有研究者[4]通过词典匹配的方法,获取到了文本中所有可能出现的词,然后通过LatticeLSTM的方法,将这些所有可能出现的单词信息加入到字符序列中,同时使用注意力机制进行权重分配,对所有可能出现的词进行筛选,保留对命名实体识别任务有增益的词,实现更好的实体识别效果。
希望能够对大家的工作有所启发。
参考文献
[1] Improving Named Entity Recognition for Chinese Social Media with Word Segmentation Representation Learning,ACL 2016
[2] Neural Chinese Named Entity Recognition via CNN-LSTM-CRF and Joint Training with Word Segmentation,WWW 2019
[3] Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism,EMNLP 2018
[4] Chinese NER Using Lattice LSTM,ACL 2018

作者简介及往期文章
薛平,博士三年级
研究领域:命名实体识别、关系抽取
1.
2.
3.
4.
PKU FINELab

转载请联系:
colordown@pku.edu.cn
The secret of success lies in perseverance
以上是关于引入中文分词信息的中文命名实体识别的主要内容,如果未能解决你的问题,请参考以下文章