工程师手记 | 数据科学专题第三篇:Pentaho数据集成(PDI)与Python和模型管理
Posted HitachiVantara
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工程师手记 | 数据科学专题第三篇:Pentaho数据集成(PDI)与Python和模型管理相关的知识,希望对你有一定的参考价值。
《工程师手记》数据科学专题
带你深入分析Pentaho数据集成(PDI)
与深度学习、数据科学笔记本集成
以及Python和模型管理
今天为大家带来该系列的第三期:
Pentaho数据集成(PDI)与Python和模型管理
满满干货,不容错过!
输

Carl Speshock
高级技术产品经理
1. 为什么需要模型管理 ?
数据科学家一直在探索和使用机器学习(ML)和深度学习(DL)数据库中的最新内容。这增加了数据工程师在生产环境中管理和监控模型分类的数量。为了满足这一需求,Hitachi Vantara开发了一种模型管理解决方案,以支持数据科学家和工程师不断演化的需求。
Pentaho提出了模型管理参考架构的概念,如下图所示:
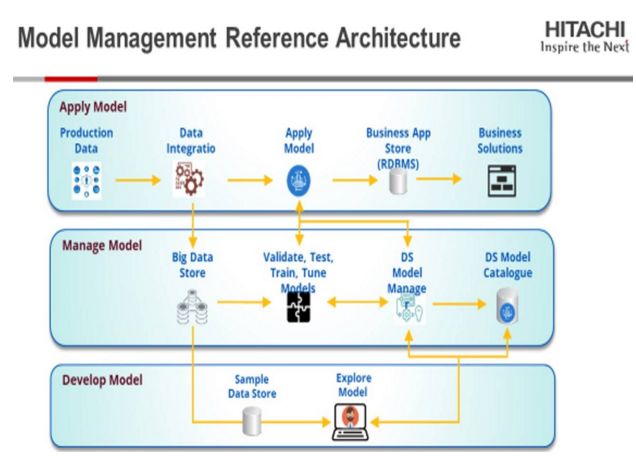
2. 为什么采用Pentaho进行模型管理 ?
由于以下原因,数据工程师选择PDI进行模型管理:
● 实施用于生产环境的机器学习/深度学习模型,通过实施模型管理解决方案扩展Pentaho的数据科学能力。
● 支持数据工程师通过PDI拖放式图形用户界面执行数据科学家从全新PDI Python Executor Step中接收的Python 脚本文件。
● 利用PDI以前步骤中的输入值作为变量、Python Numpy和/或深度学习处理中的Pandas DataFrame对象,从而将深度学习Python脚本文件与PDI工作流和数据流集成在一起。
Pentaho模型管理架构包括:
● PDI
执行数据工程师实施的数据整理/特征工程,以满足数据科学家的生产数据集请求。
● Python Executor Step
执行包含机器学习和深度学习库等的Python脚本。
● 机器学习/深度学习模型
由数据科学家在数据科学笔记本(例如Jupyter Notebook)中开发。
● 模型目录
将版本化模型存储在RDBMS、NoSQL数据库和其他数据存储库中。
● 冠军/挑战者多模型分析
从模型目录中提取模型,并使用超参数迭代运行,以分析和评估模型性能。
3. 我们如何在PDI中管理模型 ?
相关组件包括:
☑ Pentaho 8.2,PDI Python Executor Step
☑ Python.org 2.7.x或Python 3.5.x
请查看Pentaho在线帮助中的Pentaho 8.2 Python Executor Step,获取依赖项列表。
https://help.pentaho.com/Documentation/8.2/Products/Data_Integration/Transformation_Step_Reference/Python_Executor
基本操作步骤:
1
按照以下示例在PDI中构建模型管理工作流:
创建Model Catalog
(模型目录)
构建模型并将模型运行信息、评估指标、模型版本等存储到Model Catalog(模型目录)中。
设置Champion/Challenger
(冠军/挑战者)运行
对于每一次运行,竞争模型将与冠军模型竞争——后者是数据科学家在生产中使用的模型。
运行Champion/Challenger Models
(冠军/挑战者模型)
将使用Model Catalog(模型目录)中预设定的挑战者模型,并针对当前冠军运行。具有最佳评估指标的模型将被设置为冠军,以保留当前冠军或用更精确的挑战者模型替换它。

2
在PDI中使用全新的8.2 Python Executor Step
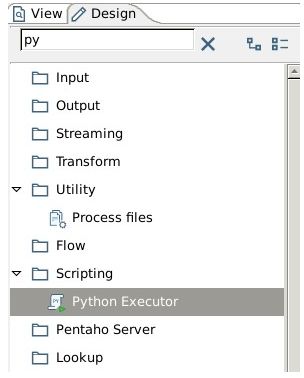
3
模型实验是模型管理工作流的第一部分,它可以构建和培训模型,并将评估指标信息存储在模型目录中(下图显示了5个处理功能区域)。PDI提供了一个拖放式图形用户界面环境,以便添加漂移检测、数据偏差检测、Canary管道等。
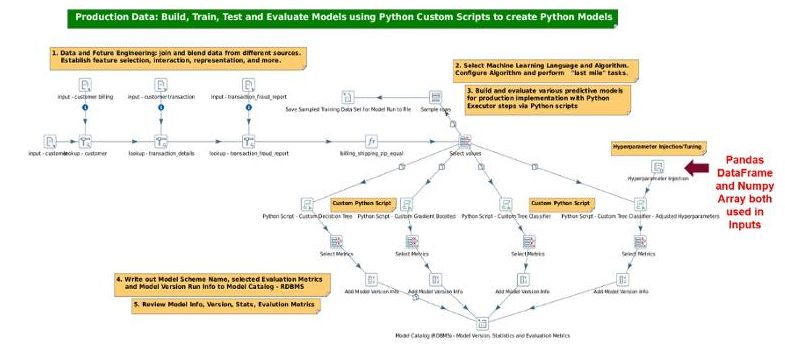
该图示采用四个模型。其中一个模型通过标记的生产数据子集注入了在线模型超参数。所有这些都可以根据您的环境进行调整(即修改为包含标记数据或未标记数据和非生产数据,以满足您的具体需求)。
4
工作流的下一个阶段是Setup Champion/Challenger(设置冠军/挑战者)运行。将模型放入冠军文件夹,其余模型放入挑战者文件夹。这可以通过使用PDI Copy Files步骤完成,示例如下:
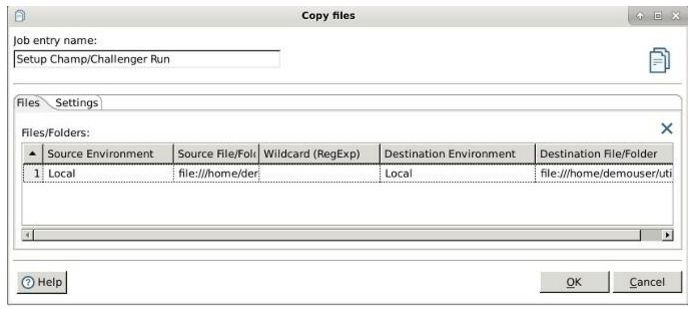
5
现在,利用三个性能最高的模型执行Champion/Challenger(冠军/挑战者)运行的一个子集。通过确定评估指标或其他数值,比较哪个模型的性能最好。运行Champion/Challenger(冠军/挑战者)的输出数据可以生成日志条目或发送电子邮件,以保存结果。
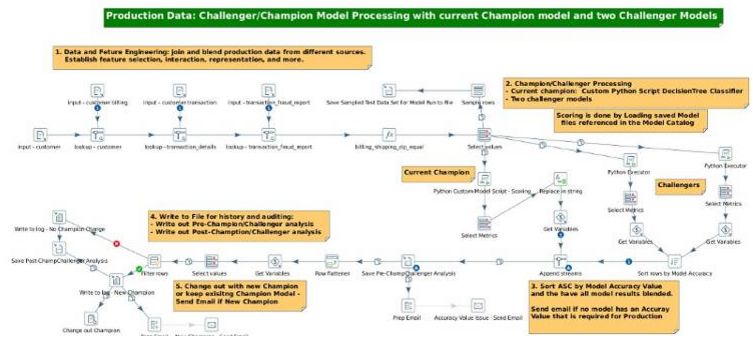
该图示显示了使用生产数据的模型,可对其进行修改,以合并标记数据或未带标记数据和非生产数据,以满足您的需求。PDI提供了一个拖放式图形用户界面环境,可以添加漂移检测、数据偏差检测、Canary管道等。
6
运行PDI作业以执行Model Management Workflow(模型管理工作流),它将把输出写入PDI日志,并显示Champion/Challenger(冠军/挑战者)结果(见下文):
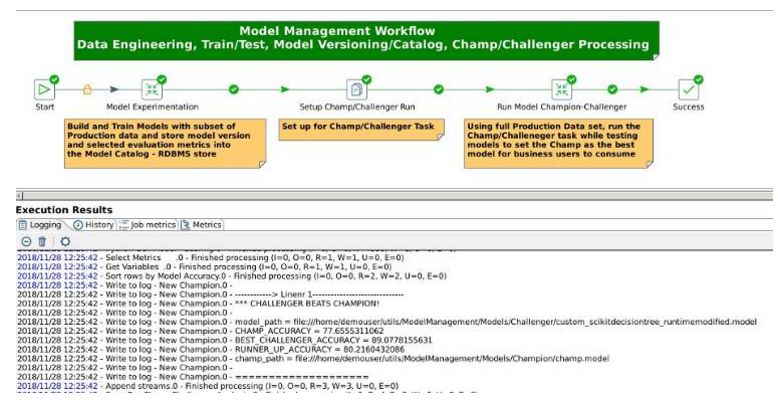
4. 为什么各企业机构采用PDI和Python
进行深度学习?
在缺乏专用数据准备工具的生产环境中操作模型已不再是一种备选项,而是必要条件。Pentaho 8.2完全可以当此重任。
● 借助针对相关管道和工作流的图形开发环境,PDI有助于更简便地实施和执行模型管理解决方案。定制您的模型管理工作流以满足特定的需求变得轻而易举。
● 数据工程师和数据科学家可在工作流程上共同协作,以及更有效地利用他们的技能和时间。
● 数据工程师可以使用PDI创建工作流,以准备来自数据科学家的Python脚本/模型,并将其在模型目录中实施。
三篇数据科学专题已经全部为你奉上
看完工程师们的亲自介绍,
有没有对Pentaho数据集成(PDI)
产生更深入的理解呢?
欢迎继续关注
《工程师手记》系列的更多精彩内容!
以上是关于工程师手记 | 数据科学专题第三篇:Pentaho数据集成(PDI)与Python和模型管理的主要内容,如果未能解决你的问题,请参考以下文章