轻松搞定RocketMQ入门
Posted JAVA烂猪皮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了轻松搞定RocketMQ入门相关的知识,希望对你有一定的参考价值。
RocketMQ是一款分布式、队列模型的消息中间件,具有以下特点:
能够保证严格的消息顺序
提供丰富的消息拉取模式
高效的订阅者水平扩展能力
实时的消息订阅机制
亿级消息堆积能力
RocketMQ网络部署特
(1)NameServer是一个几乎无状态的节点,可集群部署,节点之间无任何信息同步
(2)Broker部署相对复杂,Broker氛围Master与Slave,一个Master可以对应多个Slaver,但是一个Slaver只能对应一个Master,Master与Slaver的对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId为0表示Master,非0表示Slaver。Master可以部署多个。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有的NameServer
(3)Producer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Produce完全无状态,可集群部署
(4)Consumer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master、Slaver建立长连接,且定时向Master、Slaver发送心跳。Consumer即可从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定
RocketMQ储存特点
(1)零拷贝原理:Consumer消费消息过程,使用了零拷贝,零拷贝包括一下2中方式,RocketMQ使用第一种方式,因小块数据传输的要求效果比sendfile方式好
a )使用mmap+write方式
优点:即使频繁调用,使用小文件块传输,效率也很高
缺点:不能很好的利用DMA方式,会比sendfile多消耗CPU资源,内存安全性控制复杂,需要避免JVM Crash问题
b)使用sendfile方式
优点:可以利用DMA方式,消耗CPU资源少,大块文件传输效率高,无内存安全新问题
缺点:小块文件效率低于mmap方式,只能是BIO方式传输,不能使用NIO
(2)数据存储结构
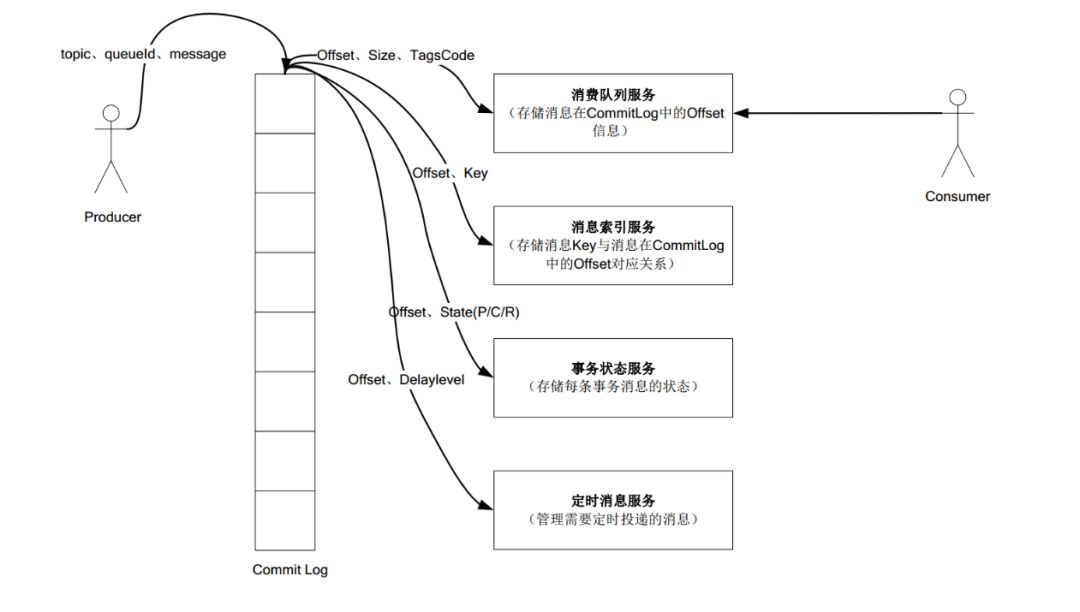
RocketMQ关键特性
1.单机支持1W以上的持久化队
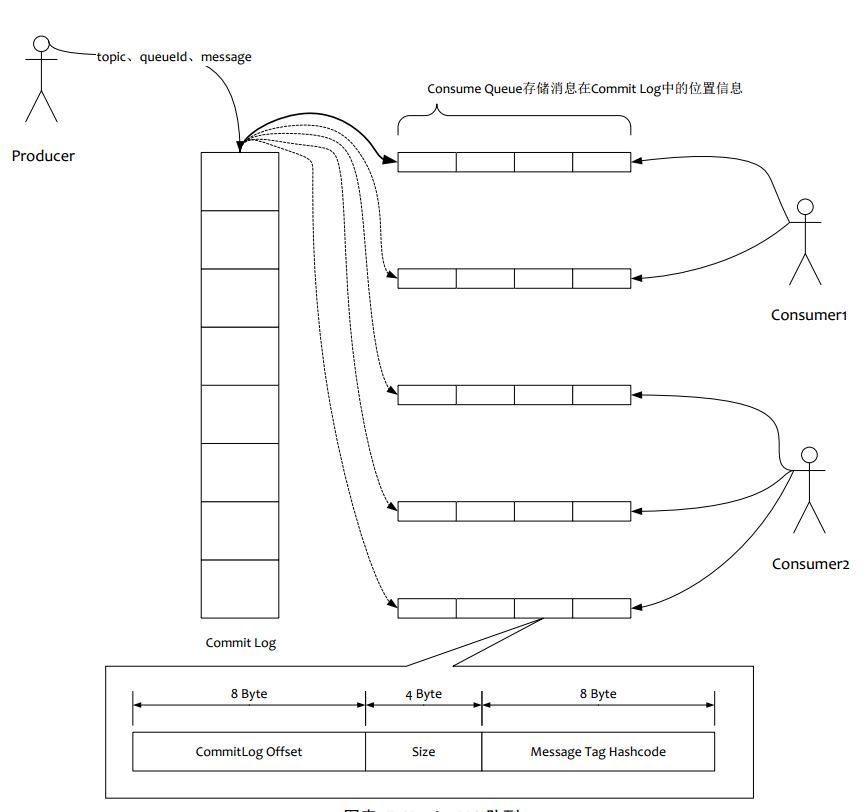
(1)所有数据单独储存到commit Log ,完全顺序写,随机读
(2)对最终用户展现的队列实际只储存消息在Commit Log 的位置信息,并且串行方式刷盘
这样做的好处:
(1)队列轻量化,单个队列数据量非常少
(2)对磁盘的访问串行话,避免磁盘竞争,不会因为队列增加导致IOWait增高
每个方案都有优缺点,他的缺点是:
(1)写虽然是顺序写,但是读却变成了随机读
(2)读一条消息,会先读Consume Queue,再读Commit Log,增加了开销
(3)要保证Commit Log 与 Consume Queue完全的一致,增加了编程的复杂度
以上缺点如何客服:
(1)随机读,尽可能让读命中pagecache,减少IO操作,所以内存越大越好。如果系统中堆积的消息过多,读数据要访问硬盘会不会由于随机读导致系统性能急剧下降,答案是否定的。
a)访问pagecache时,即使只访问1K的消息,系统也会提前预读出更多的数据,在下次读时就可能命中pagecache
b)随机访问Commit Log 磁盘数据,系统IO调度算法设置为NOOP方式,会在一定程度上将完全的随机读变成顺序跳跃方式,而顺序跳跃方式读较完全的随机读性能高5倍
(2)由于Consume Queue存储数量极少,而且顺序读,在pagecache的与读取情况下,Consume Queue的读性能与内存几乎一直,即使堆积情况下。所以可以认为Consume Queue完全不会阻碍读性能
(3)Commit Log中存储了所有的元信息,包含消息体,类似于mysql、Oracle的redolog,所以只要有Commit Log存在, Consume Queue即使丢失数据,仍可以恢复出来
2.刷盘策略
rocketmq中的所有消息都是持久化的,先写入系统pagecache,然后刷盘,可以保证内存与磁盘都有一份数据,访问时,可以直接从内存读取
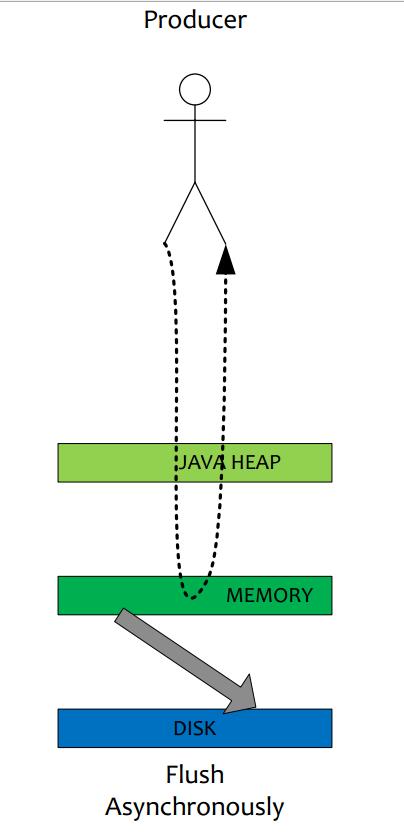
2.1异步刷盘
在有 RAID 卡, SAS 15000 转磁盘测试顺序写文件,速度可以达到 300M 每秒左右,而线上的网卡一般都为千兆网卡,写磁盘速度明显快于数据网络入口速度,那么是否可以做到写完 内存就向用户返回,由后台线程刷盘呢?
(1). 由于磁盘速度大于网卡速度,那么刷盘的进度肯定可以跟上消息的写入速度。
(2). 万一由于此时系统压力过大,可能堆积消息,除了写入 IO,还有读取 IO,万一出现磁盘读取落后情况,会不会导致系统内存溢出,答案是否定的,原因如下:
a) 写入消息到 PAGECACHE 时,如果内存不足,则尝试丢弃干净的 PAGE,腾出内存供新消息使用,策略是 LRU 方式。
b) 如果干净页不足,此时写入 PAGECACHE 会被阻塞,系统尝试刷盘部分数据,大约每次尝试 32 个 PAGE,来找出更多干净 PAGE。
综上,内存溢出的情况不会出现
2.2同步刷盘:
同步刷盘与异步刷盘的唯一区别是异步刷盘写完 PAGECACHE 直接返回,而同步刷盘需要等待刷盘完成才返回,同步刷盘流程如下:
(1)写入 PAGECACHE 后,线程等待,通知刷盘线程刷盘。
(2)刷盘线程刷盘后,唤醒前端等待线程,可能是一批线程。
(3)前端等待线程向用户返回成功。
3.消息查询
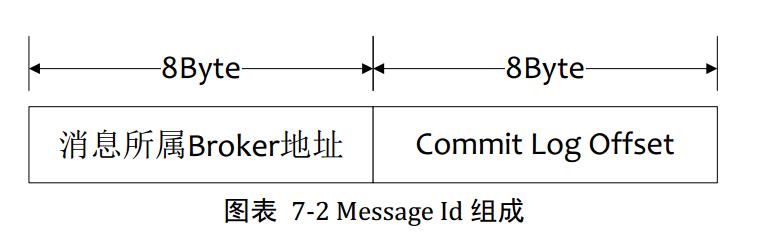
3.1按照MessageId查询消息
3.2按照Message Key查询消息
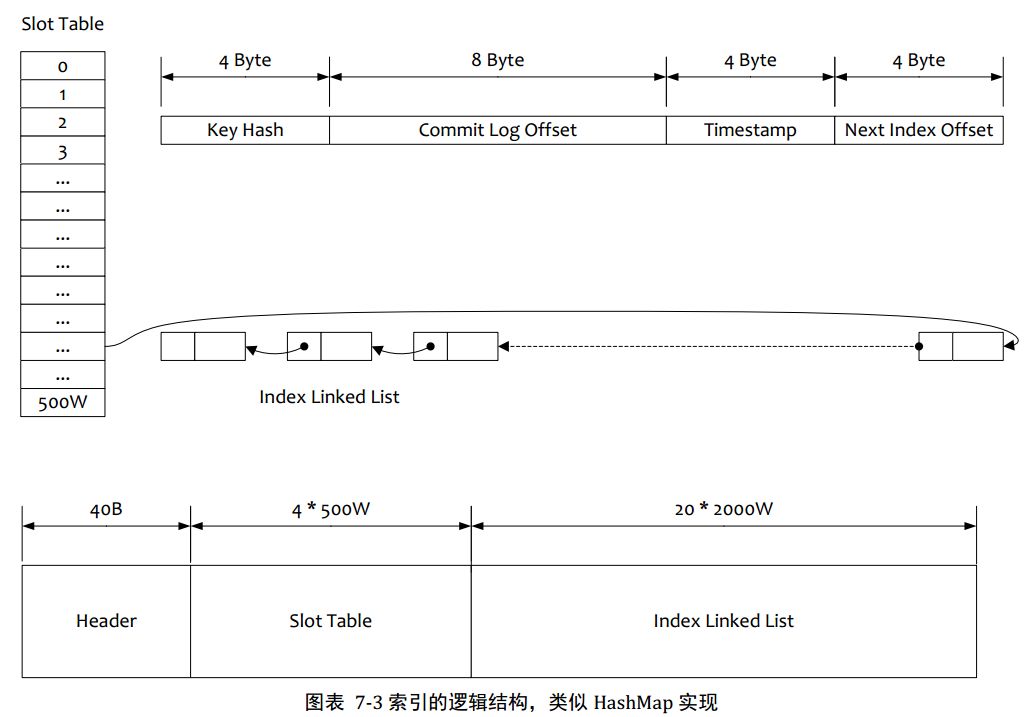
1.根据查询的key的hashcode%slotNum得到具体的槽位置 (slotNum是一个索引文件里面包含的最大槽目数目,例如图中所示slotNum=500W)
2.根据slotValue(slot对应位置的值)查找到索引项列表的最后一项(倒序排列,slotValue总是指向最新的一个索引项)
3.遍历索引项列表返回查询时间范围内的结果集(默认一次最大返回的32条记录)
4.Hash冲突,寻找key的slot位置时相当于执行了两次散列函数,一次key的hash,一次key的hash取值模,因此这里存在两次冲突的情况;第一种,key的hash值不同但模数相同,此时查询的时候会在比较第一次key的hash值(每个索引项保存了key的hash值),过滤掉hash值不想等的情况。第二种,hash值相等key不想等,出于性能的考虑冲突的检测放到客户端处理(key的原始值是存储在消息文件中的,避免对数据文件的解析),客户端比较一次消息体的key是否相同
5.存储,为了节省空间索引项中存储的时间是时间差值(存储时间——开始时间,开始时间存储在索引文件头中),整个索引文件是定长的,结构也是固定的
4.服务器消息过滤
RocketMQ的消息过滤方式有别于其他的消息中间件,是在订阅时,再做过滤,先来看下Consume Queue存储结构
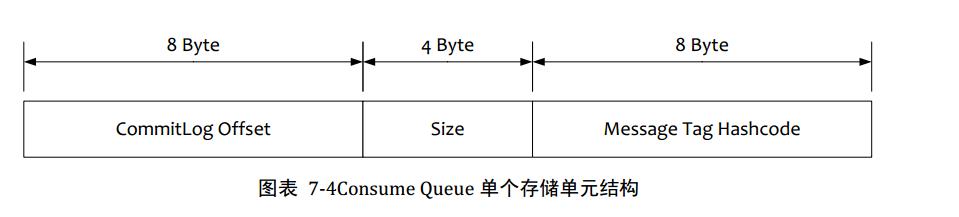
1.在Broker端进行Message Tag比较,先遍历Consume Queue,如果存储的Message Tag与订阅的Message Tag不符合,则跳过,继续比对下一个,符合则传输给Consumer。注意Message Tag是字符串形式,Consume Queue中存储的是其对应的hashcode,比对时也是比对hashcode
2.Consumer收到过滤消息后,同样也要执行在broker端的操作,但是比对的是真实的Message Tag字符串,而不是hashcode
为什么过滤要这么做?
1.Message Tag存储hashcode,是为了在Consume Queue定长方式存储,节约空间
2.过滤过程中不会访问Commit Log 数据,可以保证堆积情况下也能高效过滤
3.即使存在hash冲突,也可以在Consumer端进行修正,保证万无一失
5.单个JVM进程也能利用机器超大内存
1.Producer发送消息,消息从socket进入java 堆
2.Producer发送消息,消息从java堆进入pagecache,物理内存
3.Producer发送消息,由异步线程刷盘,消息从pagecache刷入磁盘
4.Consumer拉消息(正常消费),消息直接从pagecache(数据在物理内存)转入socket,到达Consumer,不经过java堆。这种消费场景最多,线上96G物理内存,按照1K消息算,可以物理缓存1亿条消息
5.Consumer拉消息(异常消费),消息直接从pagecache转入socket
6.Consumer拉消息(异常消费),由于socket访问了虚拟内存,产生缺页中断,此时会产生磁盘IO,从磁盘Load消息到pagecache,然后直接从socket发出去
7.同5
8.同6
6.消息堆积问题解决办法
1 消息的堆积容量、依赖磁盘大小
2 发消息的吞吐量大小受影响程度、无Slave情况,会受一定影响、有Slave情况,不受影响
3 正常消费的Consumer是否会受影响、无Slave情况,会受一定影响、有Slave情况,不受影响
4 访问堆积在磁盘的消息时,吞吐量有多大、与访问的并发有关,最终会降到5000左右
在有Slave情况下,Master一旦发现Consumer访问堆积在磁盘的数据时,回想Consumer下达一个重定向指令,令Consumer从Slave拉取数据,这样正常的发消息与正常的消费不会因为堆积受影响,因为系统将堆积场景与非堆积场景分割在了两个不同的节点处理。这里会产生一个问题,Slave会不会写性能下降,答案是否定的。因为Slave的消息写入只追求吞吐量,不追求实时性,只要整体的吞吐量高就行了,而Slave每次都是从Master拉取一批数据,如1M,这种批量顺序写入方式使堆积情况,整体吞吐量影响相对较小,只是写入RT会变长。
服务端安装部署
我是在虚拟机中的CentOS6.5中进行部署。
1.下载程序
2.tar -xvf alibaba-rocketmq-3.0.7.tar.gz 解压到适当的目录如/opt/目录
3.启动RocketMQ:进入rocketmq/bin 目录 执行
nohup sh mqnamesrv &
4.启动Broker,设置对应的NameServer
nohup sh mqbroker -n "127.0.0.1:9876" &
编写客户端
可以查看sameple中的quickstart源码 1.Consumer 消息消费者
/**
* Consumer,订阅消息
*/
public class Consumer {
public static void main(String[] args) throws InterruptedException, MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("QuickStartConsumer");
consumer.setNamesrvAddr("127.0.0.1:9876");
consumer.setInstanceName("QuickStartConsumer");
consumer.subscribe("QuickStart", "*");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.println(Thread.currentThread().getName() + " Receive New Messages: " + msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
System.out.println("Consumer Started.");
}
}
2.Producer消息生产者
/**
* Producer,发送消息
*
*/
public class Producer {
public static void main(String[] args) throws MQClientException, InterruptedException {
DefaultMQProducer producer = new DefaultMQProducer("QuickStartProducer");
producer.setNamesrvAddr("127.0.0.1:9876");
producer.setInstanceName("QuickStartProducer");
producer.start();
for (int i = 0; i < 1000; i++) {
try {
Message msg = new Message("QuickStart",// topic
"TagA",// tag
("Hello RocketMQ ,QuickStart" + i).getBytes()// body
);
SendResult sendResult = producer.send(msg);
System.out.println(sendResult);
}
catch (Exception e) {
e.printStackTrace();
Thread.sleep(1000);
}
}
producer.shutdown();
}
}
3.首先运行Consumer程序,一直在运行状态接收服务器端推送过来的消息
23:18:07.587 [main] DEBUG i.n.c.MultithreadEventLoopGroup - -Dio.netty.eventLoopThreads: 16
23:18:07.591 [main] DEBUG i.n.util.internal.PlatformDependent - Platform: Windows
23:18:07.592 [main] DEBUG i.n.util.internal.PlatformDependent - Java version: 7
23:18:07.592 [main] DEBUG i.n.util.internal.PlatformDependent - -Dio.netty.noUnsafe: false
23:18:07.593 [main] DEBUG i.n.util.internal.PlatformDependent0 - java.nio.ByteBuffer.cleaner: available
23:18:07.593 [main] DEBUG i.n.util.internal.PlatformDependent0 - java.nio.Buffer.address: available
23:18:07.593 [main] DEBUG i.n.util.internal.PlatformDependent0 - sun.misc.Unsafe.theUnsafe: available
23:18:07.593 [main] DEBUG i.n.util.internal.PlatformDependent0 - sun.misc.Unsafe.copyMemory: available
23:18:07.593 [main] DEBUG i.n.util.internal.PlatformDependent0 - java.nio.Bits.unaligned: true
23:18:07.594 [main] DEBUG i.n.util.internal.PlatformDependent - sun.misc.Unsafe: available
23:18:07.594 [main] DEBUG i.n.util.internal.PlatformDependent - -Dio.netty.noJavassist: false
23:18:07.594 [main] DEBUG i.n.util.internal.PlatformDependent - Javassist: unavailable
23:18:07.594 [main] DEBUG i.n.util.internal.PlatformDependent - You don't have Javassist in your class path or you don't have enough permission to load dynamically generated classes. Please check the configuration for better performance.
23:18:07.595 [main] DEBUG i.n.util.internal.PlatformDependent - -Dio.netty.noPreferDirect: false
23:18:07.611 [main] DEBUG io.netty.channel.nio.NioEventLoop - -Dio.netty.noKeySetOptimization: false
23:18:07.611 [main] DEBUG io.netty.channel.nio.NioEventLoop - -Dio.netty.selectorAutoRebuildThreshold: 512
23:18:08.355 [main] DEBUG i.n.util.internal.ThreadLocalRandom - -Dio.netty.initialSeedUniquifier: 0x8c0d4793e5820c31
23:18:08.446 [NettyClientWorkerThread_1] DEBUG io.netty.util.ResourceLeakDetector - -Dio.netty.noResourceLeakDetection: false
Consumer Started.
4.再次运行Producer程序,生成消息并发送到Broker,Producer的日志冲没了,但是可以看到Broker推送到Consumer的一条消息
ConsumeMessageThread-QuickStartConsumer-3 Receive New Messages: [MessageExt [queueId=0, storeSize=150,
queueOffset=244, sysFlag=0, bornTimestamp=1400772029972, bornHost=/10.162.0.7:54234,
storeTimestamp=1400772016017, storeHost=/127.0.0.1:10911, msgId=0A0A0A5900002A9F0000000000063257,
commitLogOffset=406103, bodyCRC=112549959, reconsumeTimes=0, preparedTransactionOffset=0,
toString()=Message [topic=QuickStart, flag=0,
properties={TAGS=TagA, WAIT=true, MAX_OFFSET=245, MIN_OFFSET=0}, body=29]]]
Consumer最佳实践
1.消费过程要做到幂等(即消费端去重)
RocketMQ无法做到消息重复,所以如果业务对消息重复非常敏感,务必要在业务层面去重,有以下一些方式:
(1).将消息的唯一键,可以是MsgId,也可以是消息内容中的唯一标识字段,例如订单ID,消费之前判断是否在DB或Tair(全局KV存储)中存在,如果不存在则插入,并消费,否则跳过。(实践过程要考虑原子性问题,判断是否存在可以尝试插入,如果报主键冲突,则插入失败,直接跳过) msgid一定是全局唯一的标识符,但是可能会存在同样的消息有两个不同的msgid的情况(有多种原因),这种情况可能会使业务上重复,建议最好使用消息体中的唯一标识字段去重
(2).使业务层面的状态机去重
2.批量方式消费
如果业务流程支持批量方式消费,则可以很大程度上的提高吞吐量,可以通过设置Consumer的consumerMessageBatchMaxSize参数,默认是1,即一次消费一条参数
3.跳过非重要的消息
发生消息堆积时,如果消费速度一直跟不上发送速度,可以选择丢弃不重要的消息
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.println(Thread.currentThread().getName() + " Receive New Messages: " + msgs);
long offset=msgs.get(0).getQueueOffset();
String maxOffset=msgs.get(0).getProperty(MessageConst.PROPERTY_MAX_OFFSET);
long diff=Long.parseLong(maxOffset)-offset;
if(diff>100000){
//处理消息堆积情况
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
如以上代码所示,当某个队列的消息数堆积到 100000 条以上,则尝试丢弃部分或全部消息,这样就可以快速追上发送消息的速度
4.优化没条消息消费过程
举例如下,某条消息的消费过程如下
1. 根据消息从 DB 查询数据 1
2. 根据消息从 DB 查询数据2
3. 复杂的业务计算
4. 向 DB 插入数据3
5. 向 DB 插入数据 4
这条消息的消费过程与 DB 交互了 4 次,如果按照每次 5ms 计算,那么总共耗时 20ms,假设业务计算耗时 5ms,那么总过耗时 25ms,如果能把 4 次 DB 交互优化为 2 次,那么总耗时就可以优化到 15ms,也就是说总体性能提高了 40%。
对于 Mysql 等 DB,如果部署在磁盘,那么与 DB 进行交互,如果数据没有命中 cache,每次交互的 RT 会直线上升, 如果采用 SSD,则 RT 上升趋势要明显好于磁盘。
个别应用可能会遇到这种情况:在线下压测消费过程中,db 表现非常好,每次 RT 都很短,但是上线运行一段时间,RT 就会变长,消费吞吐量直线下降
主要原因是线下压测时间过短,线上运行一段时间后,cache 命中率下降,那么 RT 就会增加。建议在线下压测时,要测试足够长时间,尽可能模拟线上环境,压测过程中,数据的分布也很重要,数据不同,可能 cache 的命中率也会完全不同
Producer最佳实践
1.发送消息注意事项
(1) 一个应用尽可能用一个 Topic,消息子类型用 tags 来标识,tags 可以由应用自由设置。只有发送消息设置了tags,消费方在订阅消息时,才可以利用 tags 在 broker 做消息过滤。
(2)每个消息在业务层面的唯一标识码,要设置到 keys 字段,方便将来定位消息丢失问题。服务器会为每个消息创建索引(哈希索引),应用可以通过 topic,key 来查询这条消息内容,以及消息被谁消费。由于是哈希索引,请务必保证 key 尽可能唯一,这样可以避免潜在的哈希冲突。
(3)消息发送成功或者失败,要打印消息日志,务必要打印 sendresult 和 key 字段
(4)send 消息方法,只要不抛异常,就代表发送成功。但是发送成功会有多个状态,在 sendResult 里定义
SEND_OK:消息发送成功
FLUSH_DISK_TIMEOUT:消息发送成功,但是服务器刷盘超时,消息已经进入服务器队列,只有此时服务器宕机,消息才会丢失
FLUSH_SLAVE_TIMEOUT:消息发送成功,但是服务器同步到 Slave 时超时,消息已经进入服务器队列,只有此时服务器宕机,消息才会丢失
SLAVE_NOT_AVAILABLE:消息发送成功,但是此时 slave 不可用,消息已经进入服务器队列,只有此时服务器宕机,消息才会丢失。对于精确发送顺序消息的应用,由于顺序消息的局限性,可能会涉及到主备自动切换问题,所以如果sendresult 中的 status 字段不等于 SEND_OK,就应该尝试重试。对于其他应用,则没有必要这样
(5)对于消息不可丢失应用,务必要有消息重发机制
2.消息发送失败处理
Producer 的 send 方法本身支持内部重试,重试逻辑如下:
(1) 至多重试 3 次
(2) 如果发送失败,则轮转到下一个 Broker
(3) 这个方法的总耗时时间不超过 sendMsgTimeout 设置的值,默认 10s所以,如果本身向 broker 发送消息产生超时异常,就不会再做重试
如:
如果调用 send 同步方法发送失败,则尝试将消息存储到 db,由后台线程定时重试,保证消息一定到达 Broker。
上述 db 重试方式为什么没有集成到 MQ 客户端内部做,而是要求应用自己去完成,基于以下几点考虑:
(1)MQ 的客户端设计为无状态模式,方便任意的水平扩展,且对机器资源的消耗仅仅是 cpu、内存、网络
(2)如果 MQ 客户端内部集成一个 KV 存储模块,那么数据只有同步落盘才能较可靠,而同步落盘本身性能开销较大,所以通常会采用异步落盘,又由于应用关闭过程不受 MQ 运维人员控制,可能经常会发生 kill -9 这样暴力方式关闭,造成数据没有及时落盘而丢失
(3)Producer 所在机器的可靠性较低,一般为虚拟机,不适合存储重要数据。 综上,建议重试过程交由应用来控制。
3.选择 oneway 形式发送
一个 RPC 调用,通常是这样一个过程
(1)客户端发送请求到服务器
(2)服务器处理该请求
(3)服务器向客户端返回应答
所以一个 RPC 的耗时时间是上述三个步骤的总和,而某些场景要求耗时非常短,但是对可靠性要求并不高,例如日志收集类应用,此类应用可以采用 oneway 形式调用,oneway 形式只发送请求不等待应答,而发送请求在客户端实现层面仅仅是一个 os 系统调用的开销,即将数据写入客户端的 socket 缓冲区,此过程耗时通常在微秒级。
RocketMQ不止可以直接推送消息,在消费端注册监听器进行监听,还可以由消费端决定自己去拉取数据
/**
* PullConsumer,订阅消息
*/
public class PullConsumer {
//Java缓存
private static final Map<MessageQueue, Long> offseTable = new HashMap<MessageQueue, Long>();
public static void main(String[] args) throws MQClientException {
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("PullConsumerGroup");
consumer.setNamesrvAddr("127.0.0.1:9876");
consumer.start();
//拉取订阅主题的队列,默认队列大小是4
Set<MessageQueue> mqs = consumer.fetchSubscribeMessageQueues("TopicTestMapBody");
for (MessageQueue mq : mqs) {
System.out.println("Consume from the queue: " + mq);
SINGLE_MQ:while(true){
try {
PullResult pullResult =
consumer.pullBlockIfNotFound(mq, null, getMessageQueueOffset(mq), 32);
List<MessageExt> list=pullResult.getMsgFoundList();
if(list!=null&&list.size()<100){
for(MessageExt msg:list){
System.out.println(SerializableInterface.deserialize(msg.getBody()));
}
}
System.out.println(pullResult.getNextBeginOffset());
putMessageQueueOffset(mq, pullResult.getNextBeginOffset());
switch (pullResult.getPullStatus()) {
case FOUND:
// TODO
break;
case NO_MATCHED_MSG:
break;
case NO_NEW_MSG:
break SINGLE_MQ;
case OFFSET_ILLEGAL:
break;
default:
break;
}
}
catch (Exception e) {
e.printStackTrace();
}
}
}
consumer.shutdown();
}
private static void putMessageQueueOffset(MessageQueue mq, long offset) {
offseTable.put(mq, offset);
}
private static long getMessageQueueOffset(MessageQueue mq) {
Long offset = offseTable.get(mq);
if (offset != null){
System.out.println(offset);
return offset;
}
return 0;
}
刚开始的没有细看PullResult对象,以为拉取到的结果没有MessageExt对象还跑到群里面问别人,犯2了
特别要注意 静态变量offsetTable的作用,拉取的是按照从offset(理解为下标)位置开始拉取,拉取N条,offsetTable记录下次拉取的offset位置。
以上是关于轻松搞定RocketMQ入门的主要内容,如果未能解决你的问题,请参考以下文章