干货分享RocketMQ命名服务和路由组件——namesrv解析
Posted 苏研大云人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货分享RocketMQ命名服务和路由组件——namesrv解析相关的知识,希望对你有一定的参考价值。
写在前面的话

本文的代码分析基于RocketMQ的4.3.0版本。

1
namesrv在RocketMQ集群中扮演的角色
先允许我从Apache RocketMQ官网盗一张图。RocketMQ集群部署架构图(多Master-多Slave集群)。
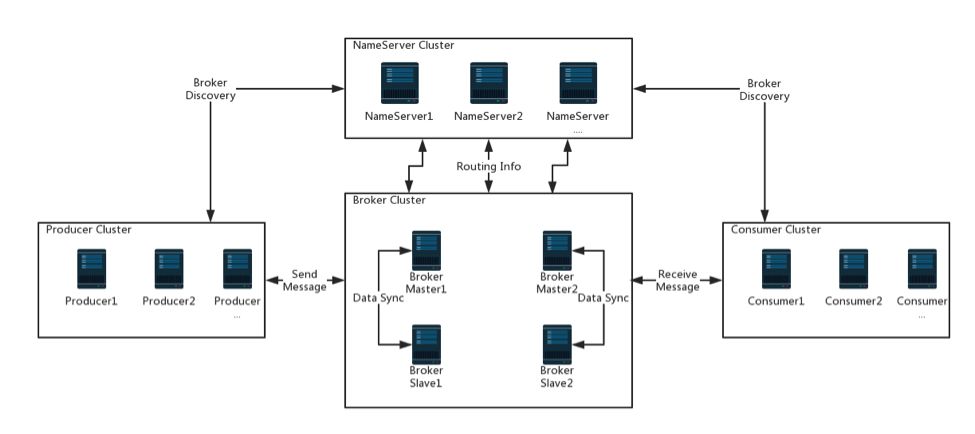
RocketMQ集群分为四部分:生产者、消费者、broker、namesrv。生产者和消费者很好理解,就是消息的生产方和使用方。broker负责消息的接收、存储、投递等。
1.namesrv一般部署为集群模式,每台broker服务器启动时都会向所有namesrv节点注册自己,随后会定时(默认30s)向namesrv集群的每一个节点上报自己。这使得namesrv集群是一个热备份模式。注册和上报的数据包括
broker中topic的信息,封装在请求体中:每个topic的名字,以及该topic下读写队列的个数,该topic在此broker下的读写权限等。
2.客户端(producer/consumer)随机的和namesrv集群中的其中一个节点建立长连接,定时(默认30s)拉取最新的topic路由信息。
3.namesrv集群各节点无状态,具体体现在所有broker上报的数据都存储在内存中,不进行任何的持久化。
4.namesrv集群各节点之间没有通信(其实这么说是不太严谨的,如果namesrv采用ClusterTestRequestProcessor作为请求的处理器,是可能会和其他节点发生通信的),集群内部没有机制保证信息的一致。
2

namesrv 代码结构
先认识下namesrv模块的代码结构和各个类的作用,能使后面源码的阅读分析事半功倍。
1.代码结构
namesrv只有8个java文件,9个类。整个工程代码不超过1000行。
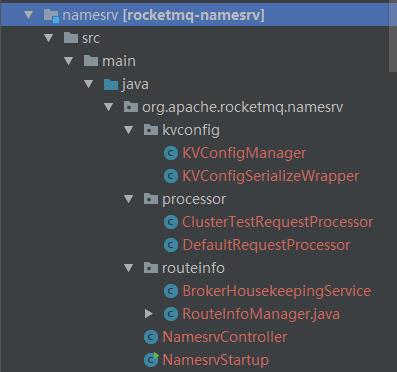
2.各个类的介绍
1.KVConfigManager: key-value配置信息的操作类。提供以下操作方法:
load: 从指定文件(json格式)加载k-v配置到本地缓存configTable。
putKVConfig: 将指定的k-v配置加入到configTable中。
deleteKVConfig:将指定key值、指定namespace的配置从configTable中移除。
getKVConfig:获取指定key值、指定namespace的配置。
getKVListByNamespace:获取指定namespace的所有k-v配置信息。
persist: 持久化configTable到文件。
printAllPeriodically:打印configTable中所有的配置信息。
2.KVConfigSerializeWrapper:是为了方便序列化/反序列化的包装类。它和文件中的json格式数据对应。json字符串和对象间的转化使用了fastjson。
3.DefaultRequestProcessor:默认请求处理器类。用来处理客户端或者broker发来的RPC请求。其中就包括处理broker发来的注册请求。以下为几个常用的处理请求:
注册Broker
注销Broker
根据指定topic获取路由信息
获取集群的全量信息(包括每个集群内所有broker,每个broker的master/slave信息)。
去除broker的写入权限。
获取所有topic名字列表。
从namesrv删除指定topic。
获取指定cluster的所有topic信息。
更新namesrv配置。
获取namesrv配置。
4.ClusterTestRequestProcessor:请求处理类。继承自DefaultRequestProcessor。只重写了一个请求处理方法:根据指定topic获取路由信息。里面只增加了一行关键代码。在本namesrv中找不到请求的topic时,向其他namesrv节点发送请求获取。这里就发生了namesrv节点间通信。只是从其他namesrv拿来的topic路由信息直接返回给原始请求方,并不会更新到本地namesrv。
5.BrokerHousekeepingService:连接的监听器。实现了ChannelEventListener接口。监听与Broker建立的通道的状态(空闲、关闭、异常三个状态),并调用相应onChannel****方法。通道的空闲、关闭、异常状态均调用RouteInfoManager.onChannelDestory方法,来更新RouteInfoManager类中的5个HashMap对象。在构建NettyRemotingServer时作为参数传入。
6.RouteInfoManager:namesrv中最重要的类。维护着生产者、消费者活动所需要的所有信息。这些信息存储在5个HashMap里,不会进行持久化处理。
private final HashMap<string >topicQueueTable;
private final HashMap brokerAddrTable;
private final HashMap> lusterAddrTable;
private final HashMap brokerLiveTable;
private final HashMap/* Filter Server */> filterServerTable;
8.NamesrvController:namesrv控制类,控制着namesrv的启动、初始化、停止等生命周期。
9.NamesrvStart:namesrv启动类,也即main函数所在类。用于构建NamesrvController,随后初始化和启动namesrv。
3
namesrv源码分析
1.启动流程
namesrv的启动流程并不复杂,参考下图:
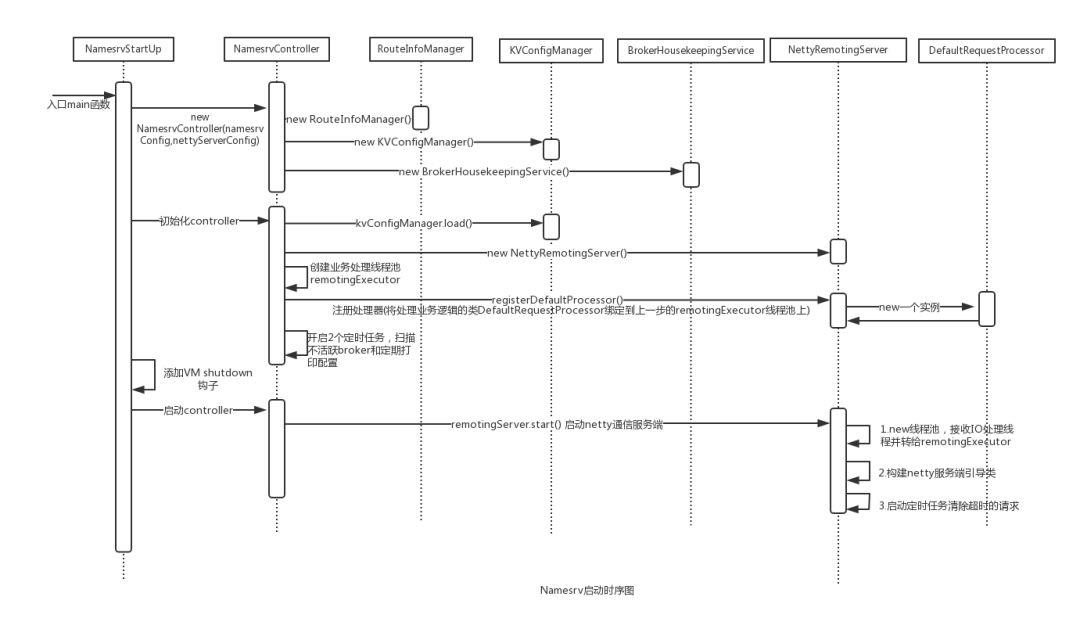
根据该时序图重点关注几个关键的步骤:
1.构建NamesrvController。时序图表述比较简单,构建NamesrvController详细逻辑为:
(1)根据启动namesrv时的系统参数,构建命令行。
(2)构建NamesrvConfig和NettyServerConfig。主要是将命令行中的参数解析到NamesrvConfig/ NettyServerConfig中。如果命令行中指定了参数文件,也会将文件中的所有配置都解析进去。
(3)最后用上一步中构建的NamesrvConfig/NettyServerConfig 创建NamesrvContorller。
2.NamesrvController的初始化。
(1)调用this.kvConfigManager.load(); 将文件中的配置load到内存中。继续看代码可以看到: 拿到配置文件的路径,通常为xxx/xxx/kvConfig.json,然后读到本地缓存configTable中。
public void load() {
String content = null;
try {
content = MixAll.file2String(this.namesrvController.getNamesrvConfig().getKvConfigPath());
} catch (IOException e) {
log.warn("Load KV config table exception", e);
}
if (content != null) {
KVConfigSerializeWrapper kvConfigSerializeWrapper =
KVConfigSerializeWrapper.fromJson(content, KVConfigSerializeWrapper.class);
if (null != kvConfigSerializeWrapper) {
this.configTable.putAll(kvConfigSerializeWrapper.getConfigTable());
log.info("load KV config table OK");
}
}
}
(2) 构建NettyRemotingServer。NettyRemotingServer是RocektMQ对Netty的再一次封装。它负责和客户端进行RPC通信。
(3) 构建一个默认8个线程的线程池 remotingExecutor。这个线程池就是最终处理业务的线程所在的线程池。 也就是运行DefaultRequestProcessor的processRequest方法的线程池。暂且称它为M2。
(4) 注册处理器。namesrv定义了2种处理器DefaultRequestProcessor和ClusterTestRequestProcessor,后者继承了前者,重写了一个方法getRouteInfoByTopic。即在当前namesrv中拿不到指定topic的路由信息时会到别的namesrv去拿。注册处理器就是在NettyRemotingServer中构建一个 protected PairdefaultRequestProcessor;其中NettyRequestProcessor就是DefaultRequestProcessor,ExecutorService就是remotingExecutor。
private void registerProcessor() {
if (namesrvConfig.isClusterTest()) {
this.remotingServer.registerDefaultProcessor(new ClusterTestRequestProcessor(this, namesrvConfig.getProductEnvName()),
this.remotingExecutor);
} else {
this.remotingServer.registerDefaultProcessor(new DefaultRequestProcessor(this), this.remotingExecutor);
}
}
(5)下面是启动2个定时任务,分别来扫描notActive的broker并移除,打印所有的configTable(前面构建NamesrvController时从内存 加载的)。 需要注意的是这两个定时任务共用一个单线程的线程池scheduledExecutorService。
3.NamesrvController的启动(start方法)
其实就是调用RemotingService的start方法,逻辑如下:
(1) 构建一个线程数为8的线程池defaultEventExecutorGroup(内有8个执行器EventExecutor,每个执行器都只有一个线程)。 这个线程池组暂且称它为M1。后面会详细讲到M1是做什么的。
(2) 使用构建器模式构建netty server端引导类。首先是指明要用的Reactor线程模型,这里的eventLoopGroupBoss为只有一个线程的线程池(暂且叫它1),eventLoopGroupSelector是有 3个线程的线程池(暂且叫它n)。然后指定了Channel类型。下面的几个参数是对端口、TCP机制的设定,这里就不作分析了。然后是指定感兴趣的ip(对连接来的客户端做限制)以及监听端口。
childHandler(new ChannelInitializer() 是重点。在新的连接被接受时,新的Channel被创建,这里的ChannelInitializer就是对这个Channel进行初始化。可以看到在这个Channel的pipeline里添加了几个ChannelHandler,并且这些ChannelHandler共用一个线程池defaultEventExecutorGroup来执行逻辑,也就是在(1)中创建的M1。这些ChannelHandler分别关注不同的I/O事件,当对应的I/O事件被触发后会调用执行里面的方法。对于最后一个NettyServerHandler,最终会被defaultEventExecutorGroup线程池再委托给remotingExecutor来执行(还记得在做NamesrvController的初始化时构建了一个8个线程的线程池M2吗),最终会执行DefaultRequestProcessor的processRequest方法,对请求做真正的处理。
(3)netty server端启动:this.serverBootstrap.bind().sync()。
以上逻辑分析对应的代码如下:
@Override
public void start() {
this.defaultEventExecutorGroup = new DefaultEventExecutorGroup(
nettyServerConfig.getServerWorkerThreads(),
new ThreadFactory() {
private AtomicInteger threadIndex = new AtomicInteger(0);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "NettyServerCodecThread_" + this.threadIndex.incrementAndGet());
}
});
ServerBootstrap childHandler =
this.serverBootstrap.group(this.eventLoopGroupBoss, this.eventLoopGroupSelector)
.channel(useEpoll() ? EpollServerSocketChannel.class : NioserverSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024)
.option(ChannelOption.SO_REUSEADDR, true)
.option(ChannelOption.SO_KEEPALIVE, false)
.childOption(ChannelOption.TCP_NODELAY, true)
.childOption(ChannelOption.SO_SNDBUF, nettyServerConfig.getServerSocketSndBufSize())
.childOption(ChannelOption.SO_RCVBUF, nettyServerConfig.getServerSocketRcvBufSize())
.localAddress(new InetSocketAddress(this.nettyServerConfig.getListenPort()))
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline()
.addLast(defaultEventExecutorGroup, HANDSHAKE_HANDLER_NAME,
new HandshakeHandler(TlsSystemConfig.tlsMode))
.addLast(defaultEventExecutorGroup,
new NettyEncoder(),
new NettyDecoder(),
new IdleStateHandler(0, 0, nettyServerConfig.getServerChannelMaxIdleTimeSeconds()),
new NettyConnectManageHandler(),
new NettyServerHandler()
);
}
});
if (nettyServerConfig.isServerPooledByteBufAllocatorEnable()) {
childHandler.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
}
try {
ChannelFuture sync = this.serverBootstrap.bind().sync();
InetSocketAddress addr = (InetSocketAddress) sync.channel().localAddress();
this.port = addr.getPort();
} catch (InterruptedException e1) {
throw new RuntimeException("this.serverBootstrap.bind().sync() InterruptedException", e1);
}
if (this.channelEventListener != null) {
this.nettyEventExecutor.start();
}
this.timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
try {
NettyRemotingServer.this.scanResponseTable();
} catch (Throwable e) {
log.error("scanResponseTable exception", e);
}
}
}, 1000 * 3, 1000);
}
2.namesrv使用的线程模型:
Reactor多线程模型(1+n+M1+M2)
通过namesrv的启动流程,可以看到其中创建了许多的线程池(1,n,M1,M2),来执行客户端请求或者是执行定时任务。这就是我们下面要讨论的namesrv的RPC通信+业务处理的线程模型:1+n+M1+M2线程模型。
namesrv(RocektMQ的其他组件也是)的PRC通信采用Netty, Netty的设计就是Reactor线程模型(Reactor的三种线程模型感兴趣的同学可以学习下),但Netty不是采用的传统的Reactor多线程模型(1+n,即一个线程接收连接、一组线程处理IO事件),而是在此基础上加以扩展,发展成了1+n+M1+M2。
下面的图描述了线程之间的关系以及分工。
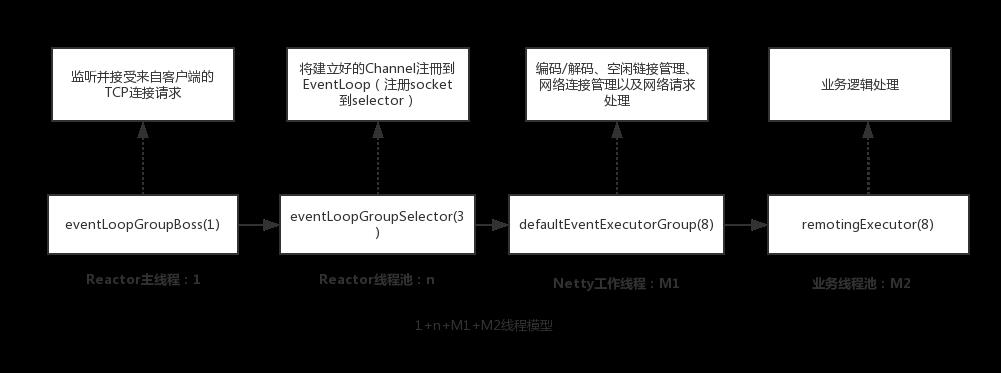
1.其中的1是eventLoopGroupBoss,他的任务是负责监听并接受来自客户端的TCP连接请求。连接建立好以后马上扔给eventLoopGroupSelector,也就是n。
2.eventLoopGroupSelector工作就是在前一步的基础上将建立好的Channel注冊到EventLoop上(这里是NioEventLoop),对应到java底层就是调用NIO接口将SocketChannel注册到selector上。然后监听网络数据,拿到网络数据后,丢给defaultEventExecutorGroup(M1)线程池。
3.defaultEventExecutorGroup主要负责处理网络通信相关的,具体是编码/解码、空闲链接管理、网络连接管理以及网络请求处理,分别对应如下几个ChannelHandler:NettyEncoder/NettyDecoder、IdleStateHandler、NettyConnectManageHandler、NettyServerHandler。M1在处理好这些任务后,将最终处理业务逻辑的工作交给M2,remotingExecutor。
ServerBootstrap childHandler =
this.serverBootstrap.group(this.eventLoopGroupBoss, this.eventLoopGroupSelector)
.channel(useEpoll() ? EpollServerSocketChannel.class : NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024)
.option(ChannelOption.SO_REUSEADDR, true)
.option(ChannelOption.SO_KEEPALIVE, false)
.childOption(ChannelOption.TCP_NODELAY, true)
.childOption(ChannelOption.SO_SNDBUF, nettyServerConfig.getServerSocketSndBufSize())
.childOption(ChannelOption.SO_RCVBUF, nettyServerConfig.getServerSocketRcvBufSize())
.localAddress(new InetSocketAddress(this.nettyServerConfig.getListenPort()))
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline()
.addLast(defaultEventExecutorGroup, HANDSHAKE_HANDLER_NAME,
new HandshakeHandler(TlsSystemConfig.tlsMode))
.addLast(defaultEventExecutorGroup,
new NettyEncoder(), //编码
new NettyDecoder(), //解码
new IdleStateHandler(0, 0, nettyServerConfig.getServerChannelMaxIdleTimeSeconds()), //空闲连接管理
new NettyConnectManageHandler(), //网络连接管理
new NettyServerHandler() //网络请求处理
);
}
});
其中最后一个NettyServerHandler是进行网络请求处理的ChannelHandler。代码如下:
class NettyServerHandler extends SimpleChannelInboundHandler<RemotingCommand> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, RemotingCommand msg) throws Exception {
processMessageReceived(ctx, msg);
}
}
再追进去:
public void processMessageReceived(ChannelHandlerContext ctx, RemotingCommand msg) throws Exception {
final RemotingCommand cmd = msg;
if (cmd != null) {
switch (cmd.getType()) {
case REQUEST_COMMAND:
processRequestCommand(ctx, cmd);
break;
case RESPONSE_COMMAND:
processResponseCommand(ctx, cmd);
break;
default:
break;
}
}
}
可以看到根据当前是Client端(接收到的是回复)还是Server端(接收到的是请求),而进行不同处理。以Server端为例:
public void processRequestCommand(final ChannelHandlerContext ctx, final RemotingCommand cmd) {
final Pair<NettyRequestProcessor, ExecutorService> matched = this.processorTable.get(cmd.getCode());
final Pair<NettyRequestProcessor, ExecutorService> pair = null == matched ? this.defaultRequestProcessor : matched;
final int opaque = cmd.getOpaque();
if (pair != null) {
//将请求封装成可执行任务
Runnable run = new Runnable() {
@Override
public void run() {
try {
//调用DefaultRequestProcessor的processRequest方法执行业务逻辑
final RemotingCommand response = pair.getObject1().processRequest(ctx, cmd);
//省略代码
} catch (Throwable e) {
//省略代码
}
}
};
//省略代码
try {
//将上面的可执行任务再封装为RequestTask,放到线程池remotingExecutor中。
final RequestTask requestTask = new RequestTask(run, ctx.channel(), cmd);
pair.getObject2().submit(requestTask);
} catch (RejectedExecutionException e) {
//省略代码
}
}
}
上面的代码中getObject2就是remotingExecutor(M2),也就是此时将后续逻辑交给了它处理。
4.remotingExecutor处理业务逻辑。根据上一步的分析,最终执行的其实就是DefaultRequestProcessor的processRequest方法。
3.namesrv中服务线程总结
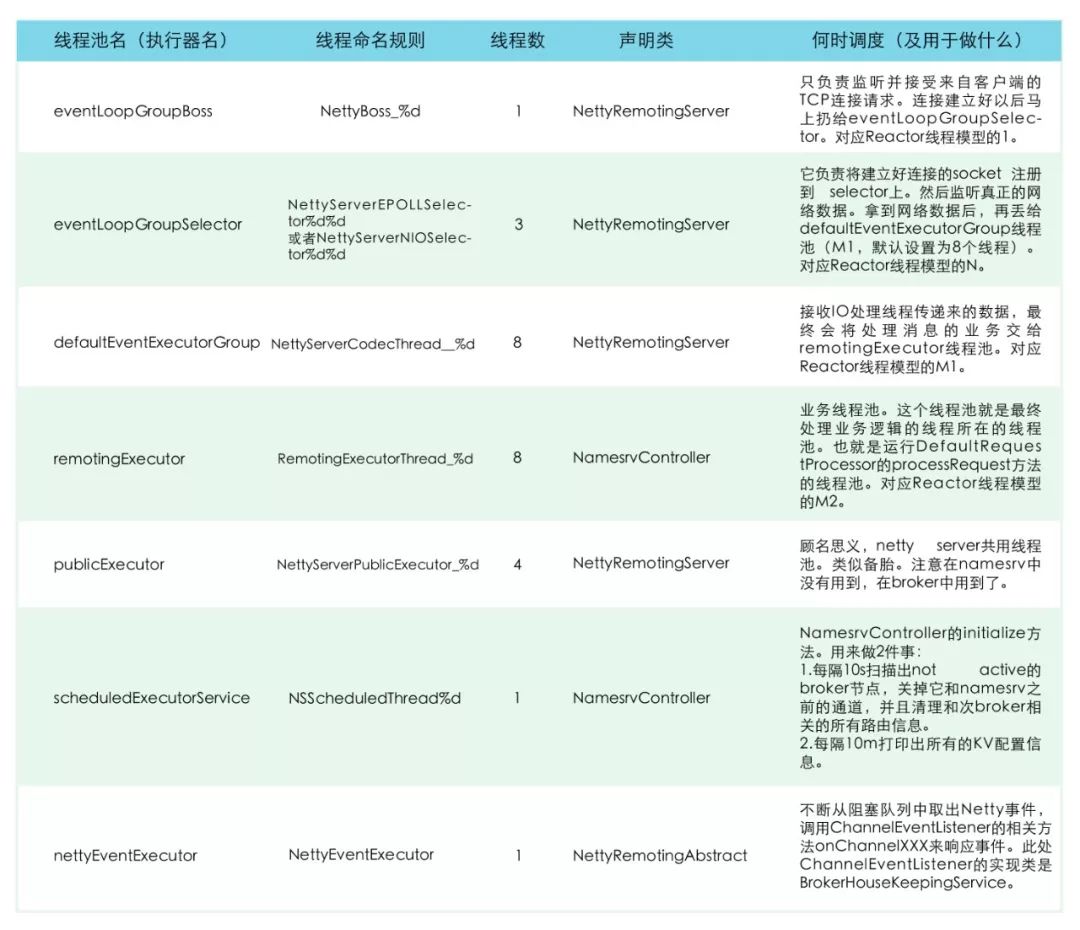
4
1.编程式设定
DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");
producer.setNamesrvAddr("name-server1-ip:port;name-server2-ip:port");
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name");
consumer.setNamesrvAddr("name-server1-ip:port;name-server2-ip:port");
sh mqadmin command-name -n name-server-ip1:port;name-server-ip2:port -X OTHER-OPTION
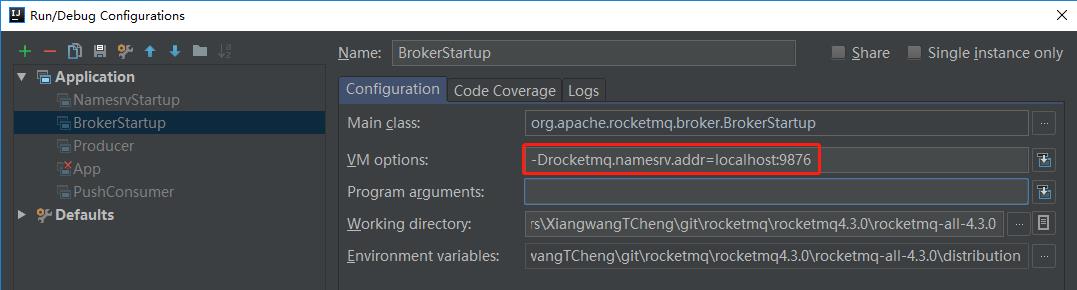
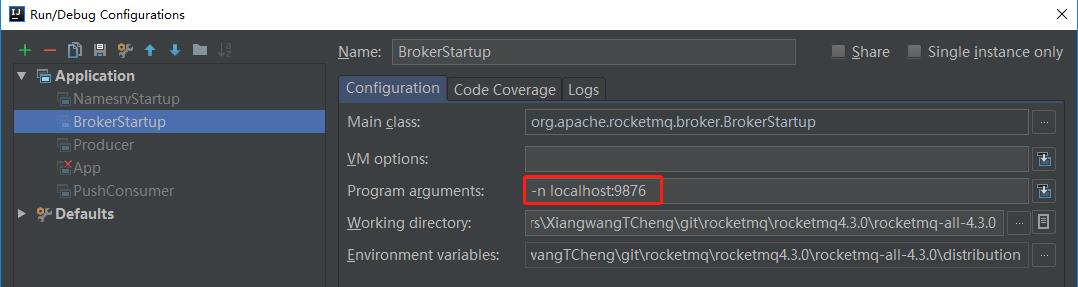
2.JVM/Java启动参数中指定
-Drocketmq.namesrv.addr=name-server1-ip:port;name-server2-ip:port
3.环境变量中指定
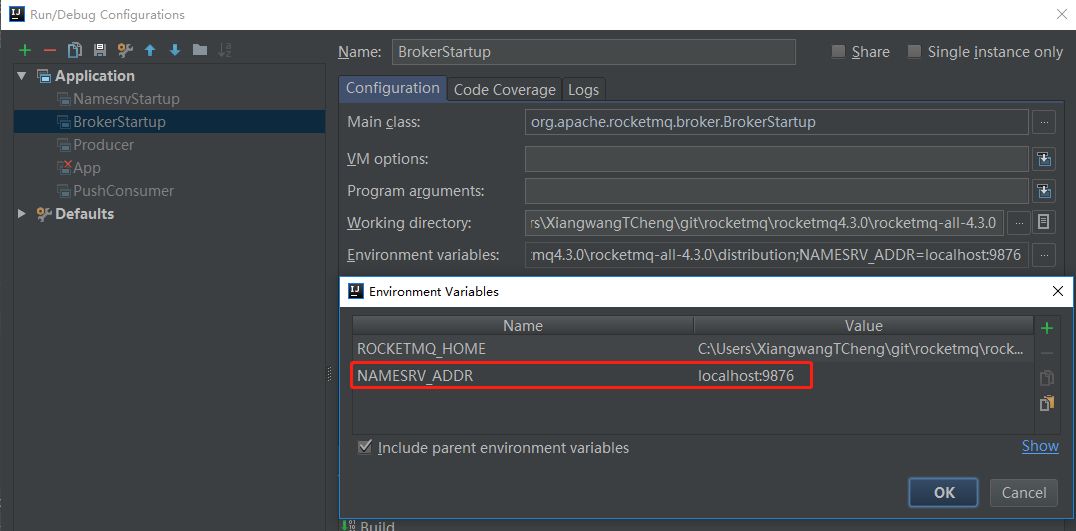
前面2和3主要用于在本地通过源码启动RocketMQ时采用。
4.http方式获取
http://jmenv.tbsite.net:8080/rocketmq/nsaddr
producer/consumer客户端启动时会从配置的namesrv列表中随机选择一个建立TCP连接。broker端则会和所有的namesrv建立长连接。 注意,以上4种方式的优先级是:
1.编程式设定 > 2.JVM/Java启动参数中指定 > 3.环境变量中指定 > 4.http方式获取
5
客户端/broker端如何保持与nameserver集群稳定连接
我们知道broker与所有nameserver都保持一个长连接,broker侧topic信息如有变化,则向所有nameserver都发送消息。而客户端(生产者和消费者)只是跟某一台nameserver节点保持联系。
假定一个场景,如果某个broker的topic配置发生了变化,它向所有nameserver发布通知,但是此时如果某一台nameserver推送失败(超时或者挂掉了),则nameserver集群之间的信息是不一致的,这种情况下RocketMQ如何保证数据的一致性?
再假定一个场景,如果客户端从namesrv拉取topic路由信息时,namesrv挂掉导致原先一直保持的长连接断开,客户端如何保证能获取到最新的路由信息?
让我们来看看RocektMQ是如何应对这些场景的。首先RocketMQ在进行任何RPC请求之前都会检查长连接的状态,如果channel的状态不OK,会尝试进行重连。
对以上2种场景分来来讲。第一个场景,broker与namesrv。如果namesrv没有真的挂掉,只是瞬间网络不稳定没有响应,经过重连后长连接恢复,则不会产生数据不一致。如果网络不稳定时间比较长,导致本次topic上报没有成功,在下一次上报(broker会定期上报给namesrv)之前长连接恢复,namesrv会接受到上次没接收到的信息。这期间会出现短暂的数据不一致。所以namesrv之间确实是弱一致性,这是namesrv提供高性能所牺牲的地方。即使namesrv真的挂掉,在恢复后broker与namesrv的连接也会自动重连。
第二个场景,客户端与namesrv。如果与该客户端一直保持长连接状态的namesrv挂掉。客户端会有failover(故障转移)机制。当检查到长连接无效后则会自动连接其他namesrv(轮询机制)。
6
为何弃zookeeper重新开发namesrv
rocketmq设计的早期阶段是很大程度参考借鉴了kafka的,比如早期的rocketmq也是依赖zookeeper来进行集群管理,提供服务发现和服务治理能力。但现在的版本去掉了zookeeper,重新设计开发了更加轻量的namesrv。rocketmq为什么要重新造轮子呢?要理解这一点,我们还要对zookeeper和kafka都有一定的认识。
1.Kafka分区原理
首先我们通过一张图来了解一下kafka。
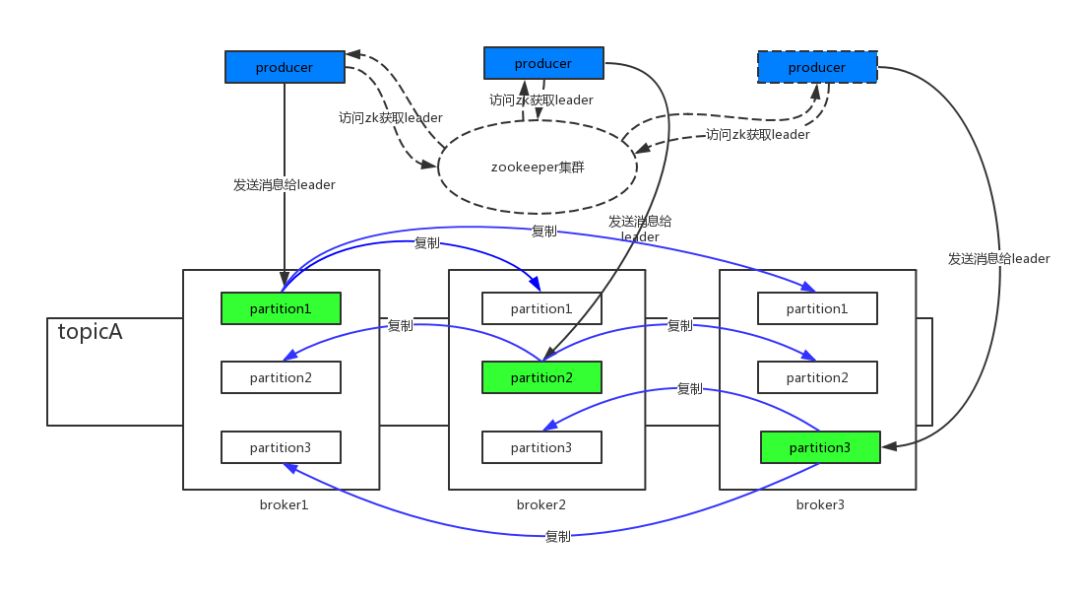
登场人物介绍:
broker:一台kafka服务器就是一个broker。和RocektMQ中的broker概念类似,不同的是RocektMQ中的一个broker可能对应于多个服务器(一个Master复数个Slave)。
zookeeper:对应RocketMQ中的namesrv概念,是服务发现和路由角色。除了保存broker/topic/partition等路由信息外,还负责为每个partition选举产生leader。
topic:标识一类消息的逻辑名字。
partition:分区。kafka引入这个概念是为了解决2个问题,性能和高可用。首先,如果某个topic的消息只存在一个broker中,这个broker就会成为并发瓶颈,无法水平扩展。自然而然就会想到将消息分布到整个集群,提高并发。由此引入分区的概念。这是一个物理概念,每个分区对应一个文件夹,文件夹中存储具体的消息。每个分区可以指定多个副本,其中一个为leader partition,其他为follower partition,这就是为了解决高可用问题了,当leader partition所在的broker宕机时,分布于其他broker上的follower partition同样拥有完整的消息信息。
producer:生产者,和RocektMQ中的生产者没有分别。
在上图中,topicA共有3个partition,每个partition有3个副本,分别分布在broker1~broker3中。对于partition1,生产者发消息时自然不是向3个副本都发送,而是向其中一个leader partition发送,然后leader partition采用同步或异步的方式将消息复制给其他的follower partition。那这个leader partition是如何产生的?又是在哪里维护的?生产者是从哪儿得知leader partition是在哪个broker上,从而准确的将消息发送给该broker?
这就是zookeeper所做的了。zookeeper会保存每个partition的信息,并且会选举产生一个leader partition。当生产者发送消息时,首先会根据策略计算出发往哪一个partition,然后根据从zookeeper获取的分区信息,找到该partition的leader partition所在的broker并将消息发往该broker。当某个有leader partition的broker宕机时,由zookeeper负责选出新的leader partition并通知给生产者。
2.RocketMQ主从架构
RocketMQ的架构在文章的开始已经叙述。broker一般采用Master-Slave方式。即在部署阶段已经明确主从节点,主从节点也不会发生切换。生产者只会和主节点通信。没有选举动作。
通过以上分析,zookeeper除了提供命名服务外还承担着选举leader的责任。不仅如此,zookeeper在处理数据的逻辑关系上比较繁琐。而RocektMQ不会用到zookeeper中的选举功能,与其使用笨重的zookeeper,短短1000多行代码的namesrv稳定性和性能肯定会更好。
7
总结
文章阐述了namesrv在集群中的作用以及和其他组件的关系,然后以namesrv的启动流程为引分析了关键代码,重点分析了namesrv中使用的1+n+M1+M2线程模型并总结了启动的线程服务,最后对为什么使用namesrv而非zookeeper进行了分析、阐述。文章中的观点如果有理解不到位、表述不清晰的地方,欢迎指出。
END
1.
2.
3.
以上是关于干货分享RocketMQ命名服务和路由组件——namesrv解析的主要内容,如果未能解决你的问题,请参考以下文章