每天进步一点点:生产环境上的代码迁移:重写Uber 无范式数据仓库的分片层
Posted Go技术大全
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每天进步一点点:生产环境上的代码迁移:重写Uber 无范式数据仓库的分片层相关的知识,希望对你有一定的参考价值。
In 2014, Uber Engineering built Schemaless, our fault-tolerant and scalable datastore, to facilitate the rapid growth of our company. For context, we deployed more than 40 Schemaless instances and many thousands of storage nodes in 2016 alone.
As our business grew, so did our resource utilization and latencies; to keep Schemaless performant, we needed a solution that would execute well at scale. After determining that our datastore could reap significant performance gains if we rewrote Schemaless’ fleet of Python worker nodes in Go (a language that features built-in support for lightweight concurrency), we migrated our product systems from the old implementation to the new one—all while still in production. Referred to as project Frontless, this process demonstrated that it was possible for us to rewrite the front-end of a massive datastore without disrupting an active service.
In this article, we discuss how we migrated the Schemaless sharding layer from Python to Go, a process that enabled us to handle more traffic with less resources and led to improved user experiences across our services.
Schemaless background
Schemaless was first launched in October 2014 as project Mezzanine, an initiative to scale the core trip database of Uber from a single Postgres instance into a highly available datastore.
The Mezzanine datastore, containing core trip data, was built as the first Schemaless instance. Since then, more than 40 instances of Schemaless have been deployed for numerous client services. (For a full history of our in-house datastore, check out our three-part series outlining Schemaless’ design, architecture, and triggers).
In mid-2016, several thousand worker nodes were running across all Schemaless instances, with each worker utilizing a large amount of resources. The worker nodes were originally built using Python and a Flask microframework inside of a uWSGI application server process that was delivered by nginx, with each uWSGI process handling one request at a time.
The model was simple to set up and easy to build on, but could not efficiently scale to meet our needs. To handle additional simultaneous requests, we had to spin up more uWSGI processes, each serving as a new Linux process with its own overhead, thereby inherently limiting the number of concurrent threads. In Go, goroutines are used to build concurrent programs. Designed to be lightweight, a goroutine is a thread managed by Go’s runtime system.
To investigate the optimization gains of rewriting the Schemaless sharding layer in Go, we created an experimental worker node that implemented a frequently used endpoint with high resource consumption. The results of this rewrite showed an 85 percent reduction in latency and an even greater reduction in resource consumption.
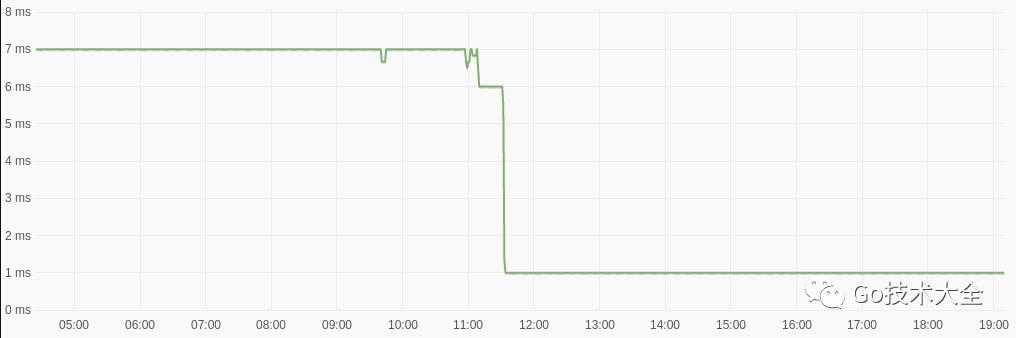
Figure 1: The graph depicts the median request latency for the endpoint implemented in Frontless.
After conducting this experiment, we determined that this rewrite would enable Schemaless to support its dependent services and worker nodes across all of its instances by freeing up CPU and memory. With this knowledge, we launched the Frontless project to rewrite the entire sharding layer of Schemaless in Go.
Designing the Frontless architecture
To successfully rewrite such an important part of Uber’s tech stack, we needed to be sure that our reimplementation was 100 percent compatible with our existing worker nodes. We made the key decision to validate the new implementation against the original code, meaning that every request to a Python worker would yield the same result in a new Go worker.
We estimated that a complete rewrite would take us about six months. Throughout this period, new features and bug fixes implemented in Uber’s production system would land in Schemaless, creating a moving target for our migration. We chose an iterative development process so that we could continuously validate and migrate features from the legacy Python codebase to the new Go codebase one endpoint at a time.
Initially, the Frontless worker node was just a proxy in front of the existing uWSGI Schemaless worker nodes through which all requests passed. An iteration would start by reimplementing one endpoint, which would then be validated in production; when no errors were observed, the new implementation would go live.
From a deployment perspective, the Frontless and uWSGI Schemaless workers were built and deployed together, which made the rollout of Frontless uniform across all instances and enabled validation of all production scenarios at once.
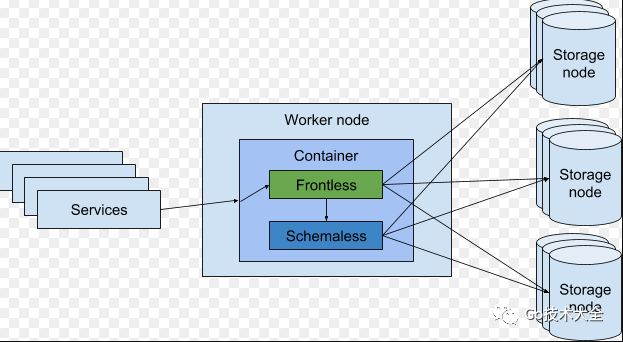
Figure 2: During our migration, a service called the worker node where Frontless and Schemaless were running together in one container. Frontless then received the request and decided if it should be forwarded to Schemaless or handled by Frontless. Finally, either Schemaless or Frontless fetched the result from the storage nodes and returned it to the service.
Read endpoints: validation by comparison
We first focused on re-implementing the read endpoints in Go. In our original implementation, read endpoints handled an average of 90 percent of the traffic on a Schemaless instance and consumed the most resources.
When an endpoint was implemented in Frontless, a validation phase would initiate to check for correctness against the Python implementation. Validation occurs by letting both the Frontless and Schemaless worker execute the request and compare the response.
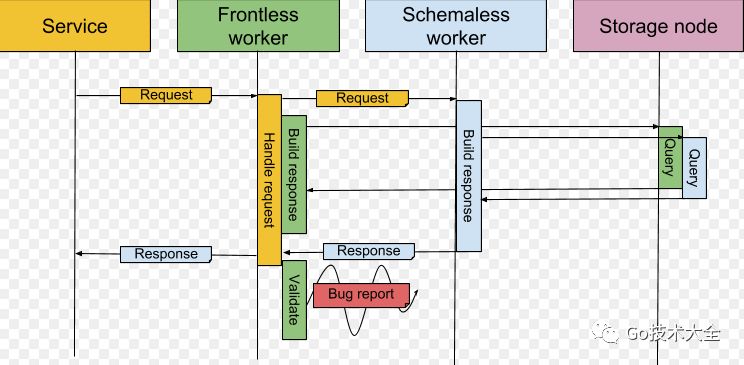
Figure 3: When a service sends a request to Frontless, it will forward the request to Schemaless, which will generate a response via querying the storage node. Then, the response made by Schemaless will be returned to Frontless, which forwards it to the service. Frontless will also create a response by querying the storage node. The two responses built by Frontless and Schemaless are compared, and if any differences arise, the result is sent as a bug report to the Schemaless Development team.
Validating a request using this method doubled the number of requests sent to the storage worker nodes; to make this increase in requests feasible, configuration flags were added to activate validation for each endpoint and adjust the percent threshold of requests to validate. This made it possible to enable and disable validation in production for any fraction of a given endpoint within seconds.
Write endpoints: automated integration tests
A Schemaless write request was only able to succeed once, so to validate these we could not use the previous strategy. However, since write endpoints in Schemaless are much simpler to work with than read endpoints, we decided to test them through automated integration tests.
Our integration tests were set-up so that we could run the same test scenario against both a Frontless worker and a Schemaless worker. The tests were automated and could be executed locally or through our continuous integration in minutes, which expedited development cycle.
To test our implementation at scale, we set up a Schemaless test instance where test traffic simulated production traffic. In this test instance, we moved write traffic from Schemaless’ Python implementation to Frontless and ran validation to check that the cells were written correctly.
Finally, once the implementation was ready for production, we slowly migrated write traffic from Schemaless’ Python implementation onto the Frontless worker by having runtime configurations that could move a percentage of the write traffic to the new implementation in seconds.
Frontless results
By December 2016, all read endpoints for the Mezzanine datastore were handled by Frontless. As depicted in Figure 2, below, the median latency of all requests decreased by 85 percent and the p99 request latency decreased by 70 percent:
Figure 4: The graph above demonstrates the time it takes for Python (the Schemaless worker, in red) and Go (the Frontless worker, in blue) requests to be processed by our datastore.
Following our Go implementation, the Schemaless CPU utilization decreased by more than 85 percent. This efficiency gain let us cut down on the number of worker nodes used across all Schemaless instances, which, based on the same QPS as before, led to improved node utilization.
Figure 5: The graph above demonstrates CPU usage during a steady stream of requests handled by Python (the Schemaless worker, in red) and Go (the Frontless worker, in blue) in our datastore.
A Frontless future
Project Frontless showed that it is possible for us to rewrite a critical system in an entirely new language with zero downtime. By re-implementing the service without changing any of Schemaless’ existing clients, we were able to implement, validate, and enable an endpoint within days instead of weeks or months. Specifically, the validation process (in which new endpoints were compared against existing implementations in production) gave us confidence that Frontless and Schemaless workers would surface the same results.
Most importantly, however, our ability to rewrite a critical system in production demonstrates the scalability of Uber’s iterative development process.
If building a fault-tolerant and scalable datastore with global impact interests you, consider applying for a role on our team!
以上是关于每天进步一点点:生产环境上的代码迁移:重写Uber 无范式数据仓库的分片层的主要内容,如果未能解决你的问题,请参考以下文章