关于数据仓库不得不说的那些“事”
Posted 厦门巨龙信息
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于数据仓库不得不说的那些“事”相关的知识,希望对你有一定的参考价值。
对于大多数非从业者或者初学者来说,数据仓库(Data Warehousing)与数据挖掘(Data Mining)是很容易混淆的两个概念。有个形象的比喻说:如果把数据仓库比做一个大型的矿坑,那么数据挖掘就是入坑采矿的工作,数据挖掘需要有非常好的数据基础,没有丰富完整的数据,是挖掘不出好内容的。数据仓库可以说是数据挖掘最理想的地基。

数据仓库
要将非常庞大又复杂的数据转化成有用的信息,首先需要做的是有效率地收集数据,于是数据仓库应运而生。数据仓库是一个环境,而不是一件产品;数据仓库是面向主题的、集成的、相对稳定的、随时间不断变化(不同时间)的数据集合,提供用户用于决策支持的当前和历史数据。数据仓库技术是为了有效的把操作型数据集成到统一的环境中,以提供决策型数据访问的各种技术和模块的总称。
根据这个定义,数据仓库也可看成是某个组织的数据存储库,用于支持战略决策。数据仓库的功能是以集成的方式存储某组织的历史数据,来反应这个组织和企业的多个方面。数据仓库中的数据永远不会更新,仅用于相应终端用户的查询。一般来说,数据仓库非常的大,存储了数以亿计的记录。
数据仓库的数据全部来源于外部,它本身并不“生产”任何数据,同时自身也不需要“消费”任何数据。在数据架构上面,数据仓库通常采用层次化的模型架构,这种模式成本最低,基础数据和应用指标的一致性最好。
虽然存在数据仓库并不是数据挖掘的先决条件,但实际上,若能访问数据仓库,数据挖掘的任务就会变得容易的多。数据仓库的主要目标是增加决策过程的“情报”和此过程的相关人员的知识。
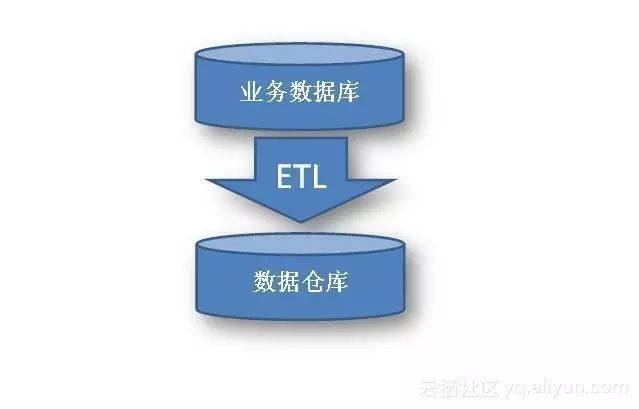
从业务数据库到数据仓库的的转化过程中,需要运用到ETL技术(extract提取、transform转换、load加载)。在整个数据仓库的构建中,ETL工作占整个工作的50%-70%。
ETL负责将分散的、异构数据源中的数据如关系数据、平面数据文件等抽取到临时中间层后,进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘提供决策支持的数据。
在业务背景中,用户需要通过构建海量历史数据的区域,海量结构化的存储、管理和查询分析服务,来满足数据的归档、即时在线查询以及离线统计分析需求。
巨龙大数据集成管理系统——高效的ETL抽取工具
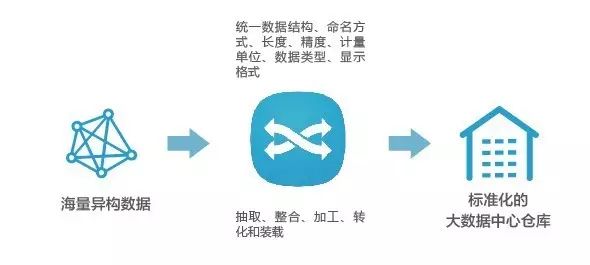
巨龙大数据集成管理系统,是基于云计算和分布式存储之上的ETL抽取工具,采用标准化、规范化的抽取模式,实现对结构化、半结构化、非结构化资源的统一抽取、整合、加工、转化、和装载。

产品架构图

产品特点
全面适配主流大数据库技术的ETL任务
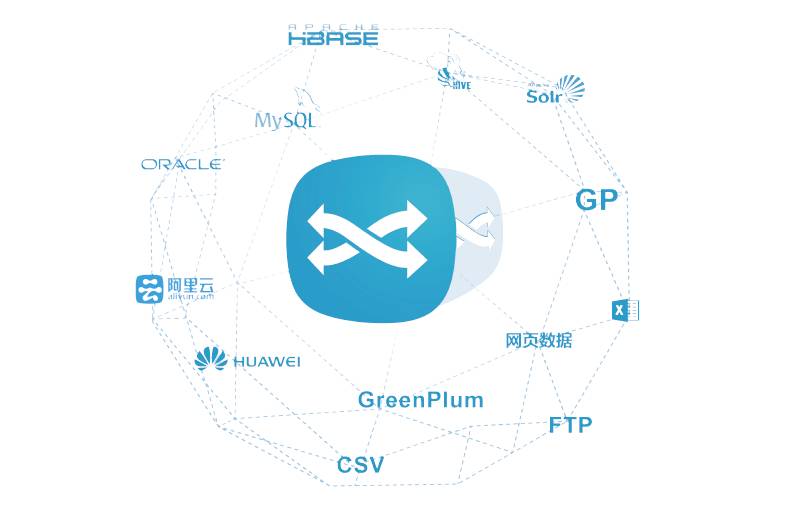
全面支持海量异构数据分析,按业务标准化需求进行整合、清洗、转换
插件化整合业务,方便整合逻辑提升ETL的扩展性
巨龙大数据集成管理系统,为公安海量数据历提供集数据转换、库抽取、库加载、文件处理、预评估等服务,不仅解决了海量异构数据的抽取和管理难题,还可为未来进一步的数据挖掘打造基础数据平台。同时构建于普通PC Server之上的Hadoop平台具有硬件廉价,系统高容错、水平灵活扩展、运行高效等特点。
以上是关于关于数据仓库不得不说的那些“事”的主要内容,如果未能解决你的问题,请参考以下文章
SQL开发实战技巧系列(十八):数据仓库中时间类型操作(进阶)INTERVALEXTRACT以及如何确定一年是否为闰年及周的计算