MaxCompute数据仓库在更新插入直接加载全量历史表三大算法中的数据转换实践
Posted IT168文库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MaxCompute数据仓库在更新插入直接加载全量历史表三大算法中的数据转换实践相关的知识,希望对你有一定的参考价值。
数据架构及流程
MaxCompute包含临时层、基础数据层、应用层三个层次,数据上云后将数据源中的数据先传输到MaxCompute里的临时层中,并将数据进行处理,接着将数据经过简单的转换传输到基础数据层,最后将数据进一步汇总到应用层进而提供服务。 三个层次的具体介绍如下:
临时层:临时层包含增量数据和全量数据。
基础数据层:基础数据层的优点是可以永久性的保存数据,它包含核心模型和通用汇总,其中核心模型又包含客户、商品、事件、渠道、代码等数据。基础数据层使用数据仓库的实体、属性命名规范来创建模型表,基础数据层表可分为主表、历史表和追加表,且具有保存历史数据、高效地使用、方便的设计原则。
应用层:应用层包含数据集市,即包含客户分析、销售分析、商品库存分析。它不像基础数据层那样可以永久性的保存数据,而是仅保存需要的数据,但它像基础数据层那样适应于使用数据仓库的实体、属性命名规范来创建模型表的原则。
ETL算法
ETL加载转换策略有M1全表覆盖、M2更新插入、M3直接加载、M4全量历史拉链、M5增量历史拉链五种策略,在ETL算法中主要介绍M2更新插入(主表)算法、M3直接加载算法、M4全量历史表算法三种算法。
更新插入(主表)算法
更新插入(主表)算法适用于保留最新状态表的处理。它是指根据主键(或指定字段)进行数据对比,如果目标表存在记录,则更新,否则插入数据。由于MaxCompute中不支持update/delete,因此需使用full outer Join实现。
在使用full outer Join实现过程中,当主键(Source Table)为NULL,主键(Target Table FULL)为NOT NULL时,OUTER JOIN 选取结果为不变数据;当主键(Source Table)为NOT NULL,主键( Target Table FULL)为NULL时,OUTER JOIN 选取结果为新增数据;当主键( Source Table)和主键(Target Table FULL)都为NOT NULL时,OUTER JOIN 选取结果为变化数据。
直接追加算法
直接追加算法是指增量数据直接追加到目标表中,此算法适合流水、交易、事件、话单等增量且不修改的数据。
全量历史表算法
全量历史表中必须包含开始日期(s_date)、结束日期(e_date)这两个字段,通过这两个字段历史表记录了数据的变动轨迹。开始日期(s_date)即数据开始存在的日期,初始加载时,如果业务表中没有日期字段对应,则填最小日期;结束日期(e_date)即数据失效或继续有效的日期,且初始加载时需填最大日期。
对全量历史表算法进行两加载四数据说明,两加载包含初始加载和日常加载,初始加载是指直接把全量数据加载到历史表中,其中开始日期为业务日期或最小日期,结束日期为最大日期;日常加载是指除开始日期、结束日期外的所有字段比对,通过Full Outer Join生成新增、失效、不变三部分数据,直接从历史表中找出已经失效的数据。四数据是指当前新增数据、当前失效数据、当前不变数据、已经失效数据,当前新增数据是指开始日期为数据日期,结束日期为最大日期;当前失效数据是指开始日期不变,结束日期为数据日期;当前不变数据是指开始日期、结束日期都不变;已经失效数据像当前不变数据一样是指开始日期、结束日期都不变,但不同点在于已经失效数据的数据已经无效。以上四部分数据可直接插入到新历史表中。
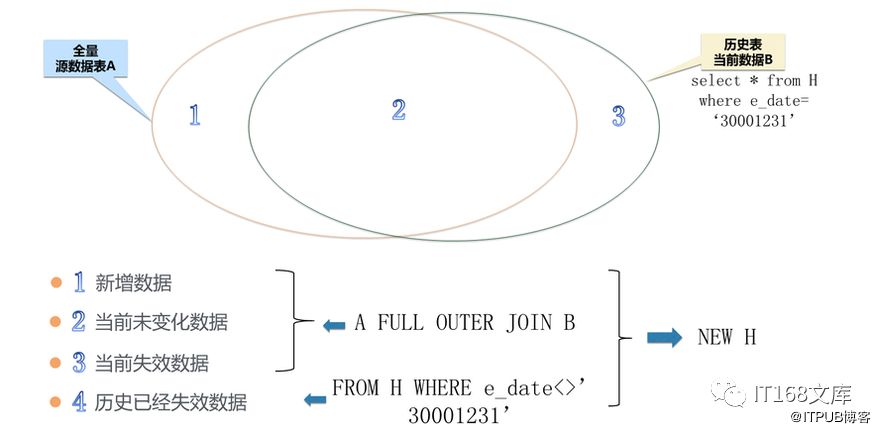 在上图中,左侧是全量源数据表A,右侧是历史表当前数据B,1代表新增数据,2代表当前未变化数据,3代表当前失效数据。通过A FULL OUTER JOIN B后生成新增数据、当前未变化数据、当前失效数据三种数据,再加上原有的历史已经失效的数据,总共四种数据构成NEW H。
在上图中,左侧是全量源数据表A,右侧是历史表当前数据B,1代表新增数据,2代表当前未变化数据,3代表当前失效数据。通过A FULL OUTER JOIN B后生成新增数据、当前未变化数据、当前失效数据三种数据,再加上原有的历史已经失效的数据,总共四种数据构成NEW H。
NULL值处理!!!
NULL是一个SQL关键字,代表着未知的数据或值,它既不具备数据类型也不具备数据特征,任何值与NULL的比较都返回false,结果为空。在OLTP系统中,大多数表字段都存在NULL。
在使用包含NULL值的字段做表关联或字段聚合时,可能会出现与业务人员期望不一致的
结果;因此,在数据进入数据仓库表时,建议对字段的NULL值进行非NULL的处理,但特
殊情况例外。同时,NULL问题属于数据库技术处理的范畴,由于NULL值的存在可能会运算出与业务人员需求不一致的结果,因此NULL值在进行SQL和数据分析时需要特别注意。
ETL
统一的ETL脚本开发
ETL程序从MaxCompute元数据表中读取表的column schema时,可根据column schema生成统一的脚本。由于ETL逻辑固定,因此可以使用ETL程序生成相应的算法脚本,然后对脚本NULL处理部分内容进行修改即可。在安装Python、安装python odps插件的前提下,将程序命名为scripts_gen.py,并设定odps配置文件、目标表名、源表名、主键字段、ETL算法参数,通过参数的配置生成名为”.sql”的脚本文件。
ETL任务映射
在进行ETL转换任务开发之前,为了方便进行任务的开发及相关进度记录,需先整理好任务之间的映射关系;在开发过程或开发完成后,为了方便对任务的统一管理维护,需要对字段级的映射及转换进行详细的文档映射记录。
ETL转换任务开发-举例
如上图所示,根目录应为02_数据转换格式,DataWorks任务目录结构应按主题划分子目录,存储主题表的任务脚本,且任务名称为表名。
如上图所示,在任务开发过程中,具体操作流程为点击主题目录→鼠标右键→新建任务→填写任务名称→创建任务→在出现的任务脚本中将转换脚本拷贝进行保存→在任务脚本页面使用运行或提交→测试运行进行任务测试→在右上角点击调度配置相关调度属性。
ETL开发步骤
ETL开发步骤可分为ETL脚本生成、Dataworks任务创建、测试上线三大步,具体流程如下:
执行scriptsGen.py脚本生成器程序,根据ETL算法输入相应的参数,生成统一的ETL脚本文件,并对脚本文件NULL值处理部分进行修改。
在Dataworks数据开发页面,创建相应的目录、任务,将相应的脚本文件SQL拷贝到新建的任务中。
测试运行,然后设置调度配置,点击提交。
ETL开发经过以上三大步后,任务就可以日常自动运行了。
投稿邮箱:qinli@it168.com
合作微信:zhaoyuyingycq
IT168文库APP
专业的IT技术交流分享平台!扫码安装,与众多技术同好交流!
IT168文库|中国专业的IT文档分享平台,拥有百万活跃的IT技术精英!我们致力于有效帮助IT人士提升职业素养。
以上是关于MaxCompute数据仓库在更新插入直接加载全量历史表三大算法中的数据转换实践的主要内容,如果未能解决你的问题,请参考以下文章
如何基于MaxCompute快速打通数据仓库和数据湖的湖仓一体实践