数据仓库系列篇—数据仓库建设
Posted 子房小语
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库系列篇—数据仓库建设相关的知识,希望对你有一定的参考价值。
在一个系统访问以及数据比较少的时候,我们只需要把数据存储在mysql、sqlserver这类关系型数据库就够了。等到数据量再稍微大一点,oracle、mysql集群或许也就够了,再不计弄过mysql主从备份、读写分离,将那些不常用的数据放在另外的mysql库里面。这就是数据仓库(ETL)的形成,数据抽取、转换、加载。
数据仓库只是一个理论,其实并不与技术有关。虽然现在大多数数据仓库是用hadoop、hive来构建的,但是早期的mysql或者sqlserver其实也是支持的。只是基于hadoop的三副本存储方式能够更加保证数据安全和备份。以及现在很多开发大数据框架hive、spark、flink等等在数据计算和存储上能够更加方便,因此便选择这些。
下面来讲讲公司的数据仓库架构
1.数据模型架构:如何建立合适的数据模型,构建合适的分层模型数据
现在市面上一般存在的数据模型大体可以总结为三层的方式:原始数据层、中间层、应用层
(1)原始数据层(ODS):把线上的业务数据抽取过来,做最原始的存储。
(2)中间数据层(DW):将原始数据进行整合,其中最为关键的是如何设计粒度,既能够保证数据完整、又尽量少产生冗余数据是难点。
(3)应用层:也称做数据集市,按照不同的业务划分。提供给不同的业务部门使用。
上述合理的三层设计会让数据模型能够应对未来5-10的数据变化,而不会因为业务一直变动。所以如果设计好,是关键。

2.核心数据模型:也就是上面讲述的中间层的粒度划分,即数据仓库的主题划分。如何根据业务合理的划分主题。
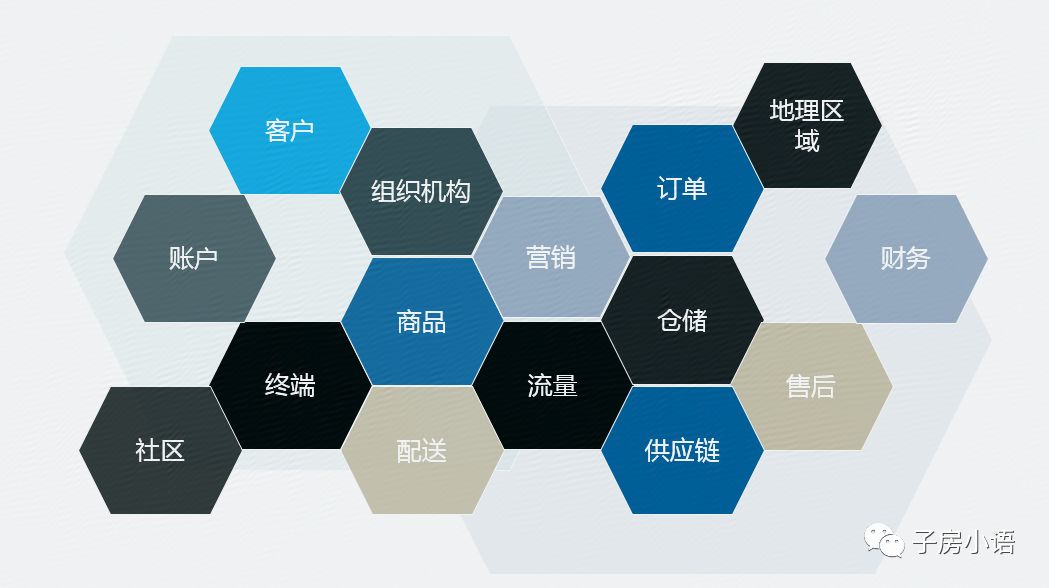
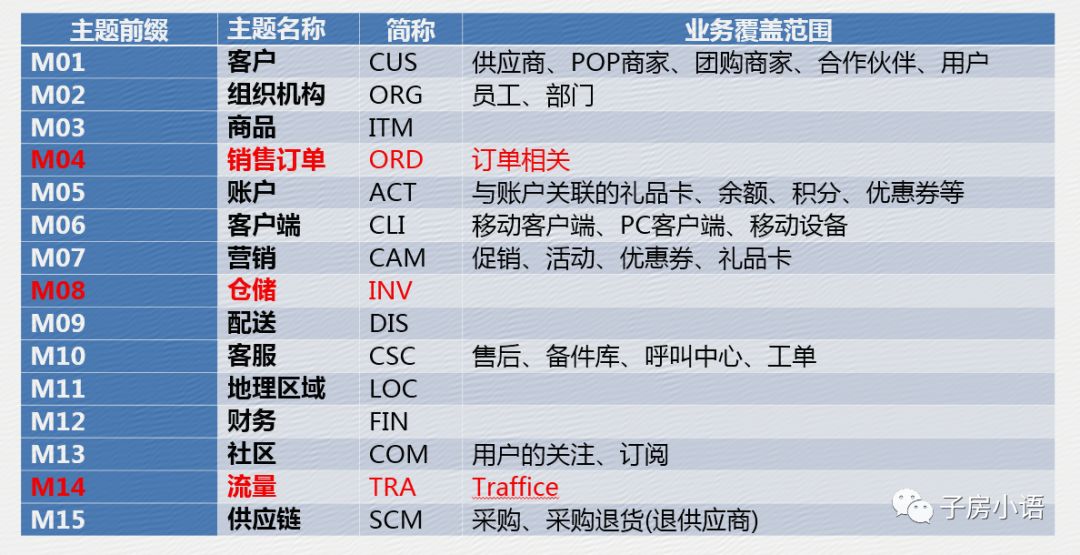
3.大数据架构:上述所建立完成好的数据仓库,需要抽数、推数、查询、监控、展示。因此需要有一套完善的大数据平台来达到自动化实现这些。
(1)抽数和推数:其实就是从线上数据抽数、以及往其他业务推送数据,同时做好定时任务的管理、元数据的管理和数据血缘关系等即可。
(2)查询和计算:如何快速的查询出需要的数据、计算出想要的结果。
(3)监控:大数据监控,参考之前写过的文章
(4)展示:主要涉及到如何做报表展示,更加直观的展示数据的变化。

因此我觉得数据仓库的模型建设和主题划分才是数据仓库的关键。至于是采用哪种技术,只是为了方便、好用而已。
现在绝大多公司虽然常用hive作为数据仓库的离线存储,是考虑了Hadoop的数据备份和可扩展,以及hive的离线查询,并且能够集成spark等计算功能。而据我了解也有一些公司是用hbase来搭建数据仓库的,因此技术至少一种手段而已。
今天讲的内容先到这里,后续会继续展开数据仓库的相关理论和知识。

以上是关于数据仓库系列篇—数据仓库建设的主要内容,如果未能解决你的问题,请参考以下文章