分级存储管理数据仓库系统设计与实现
Posted 中国移动大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分级存储管理数据仓库系统设计与实现相关的知识,希望对你有一定的参考价值。
基于传统关系型数据库和Hadoop,共同构建分级存储管理的,服务于数据挖掘分析的企业海量数据仓库系统。本文对系统设计的基本架构,数据分类放置、数据迁移、存储管理、高可用性等问题进行了阐述,并给出了解决方案。
一
引言
近年来随着大数据技术和应用的发展,数据仓储需求也急剧增加,存储成本大幅提高。在此情况下,分级存储的思想被提出,各种数据分级策略、迁移方法和新的相应存储平台涌现。但由于技术发展的历史过程,目前企业中大量数据仍以二维表的形式存储在关系型数据库中,完全推翻现有系统架构重建新的存储平台,受限于成本、技术实现复杂和对持续提供服务的需求,通常企业无法接受。针对这一问题,本文提出了一种基于传统关系型数据库和Hadoop,共同构建的分级存储管理的数据仓库系统设计,可作为传统数据仓库向分级存储平台逐步过渡演进的中间解决方案。
二
系统框架
如图1所示,数据仓库系统由数据挖掘建模数据库与Hadoop数据仓储集群共同组成。原始数据来源于各类诸如CRM、ERP等的业务支撑系统。根据数据是结构化数据或半、非结构化数据分为两类。其中,结构化数据通常来自关系型数据库的数据源,通过ETL工具从源系统抽取装载到用于数据挖掘分析的数据挖掘建模数据库上。一般原始数据在数据挖掘建模数据库上会再经过一系列建模的数据处理逻辑,转换成用于数据挖掘分析的模型数据。模型数据基于一定的放置迁移策略,一部分存放在数据挖掘建模数据库上,一部分通过数据迁移工具存放到Hadoop集群上。半、非结构化数据由于不方便用二维逻辑表来表示,因而跳过数据挖掘建模数据库,直接存放至Hadoop集群上。
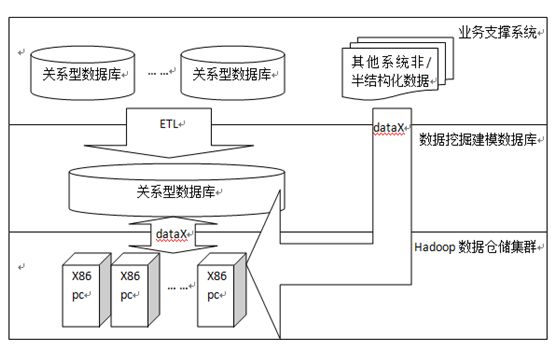 图1 分级存储管理数据仓库系统框架
图1 分级存储管理数据仓库系统框架
在Hadoop集群上存储数据通常会采用HDFS、Hive或HBase。HDFS是Hadoop平台的分布式文件系统,但鉴于直接操作文件比较复杂,可以使用分布式数据库Hive或HBase作为补充。其中,Hive是基于HDFS的数据库,数据文件都以HDFS文件形式存放,存储了表的数据在HDFS上的位置、存储格式等元数据。Hive支持SQL查询,对传统的关系型数据库平台的开发人员更友好。HBase是一个NoSQL数据库,随机查询性能和可扩展性能比较好。
三
数据分类放置
数据分类放置指基于数据的访问、恢复等特征,并根据不同的业务目标进行划分存放,以实现基于信息的重要程度对数据进行存储管理。
对于一个数据模型,通常近期的数据具有较高的访问频度,历史数据具有较低的访问频度。因而最简单的一种分类方式是基于数据的时间周期和业务类型划分在线、离线数据。在线数据保留在数据挖掘建模数据库上,离线数据定期从数据挖掘建模数据库迁移到hadoop集群上存放。为了便于数据分类放置,数据建模的物理模型可以采用按时间周期分表或者按时间周期进行表分区的方式。
选择传统关系型数据库作为数据挖掘建模数据库主要是基于以下几个原因:
1、大量源系统都是关系型数据库,数据是结构化的二维表数据。
2、范式建模法、维度建模法、E-R建模法,其物理建模的结果都是二维表。
3、现有数据仓库很大一部分都是基于关系型数据库建设的。
选择Hadoop集群存放离线数据主要是基于以下几个原因:
1、集群横向扩展相较传统关系型数据库容易。
2、使用x86的pc较传统小型机服务器在硬件成本上更低。
3、较传统磁带更便于数据恢复和访问使用。
4、兼容存放和处理非、半结构化数据。
非、半结构化数据从源系统获取后直接放置在Hadoop集群上,不再进行进一步分类放置了。
四
数据迁移
如图1所示,数据从挖掘建模数据库迁移到Hadoop集群、从非关系型数据库的源系统到Hadoop集群,均是异构数据源间的迁移,并且挖掘建模数据库,可能存在多个且采用诸如Oracle、DB2、mysql等等不同数据库。非关系数据库的源系统也可能存在多个且采用诸如HDFS、HTTP、Stream等。
DataX是阿里开发的一套开源的异构数据源同步工具框架,通过选用读、写端所用的数据源类型插件,配置迁移作业的xml参数文件,实现异构数据源间的数据迁移。此外,作业的参数文件还可以设定变量参数,实现运行时动态指定的目的。最后,通过开发读、写插件可以扩展DataX支持的数据源类型。
使用DataX有利于统一的数据迁移工具,并且在新增接入的源系统类型时,可显著减少二次开发量。
五
存储管理策略
数据分类放置的策略制定后,通过数据迁移,实际上数据挖掘建模数据库上保留模型数据的数据周期已固定,不需要再进行存储策略的管理。但是随着时间的推移,迁移到Hadoop集群的历史周期数据会积累的越来越多,占用的存储会越来越大。而实际上过旧的数据实际上也会失去使用价值,没必要一直保留。此时需要通过一定的存储管理策略,对历史数据进行定期的清理。
存储管理策略仍基于数据周期,细分为定长数据周期保留和特定数据周期保留两种。定长数据周期保留,即从最近的一个数据周期开始,保留连续的固定数量的数据周期的数据。超过该数据周期范围的数据予以清理删除。特定数据周期保留,即保留指定具体某些数据周期的数据,其他非指定数据周期的数据予以清理删除。也可以将两种策略进行叠加,符合定长数据周期保留或特定数据周期保留中任意一种策略的数据周期保留范围的予以保留,两种策略的数据周期保留范围都不满足的予以清理删除。
、
六
高可用性
传统关系型数据库一般都具有成熟的数据库级的数据同步灾备解决方案,例如Oracle的ADG、DB2的HADR等。
对于Hadoop集群,可以通过配置dfs.name.dir将HDFS的元数据文件备份至远程磁盘(如NFS挂载的目录),来确保namenode故障时,可以恢复元数据文件并重构namenode。此外,在构建集群时也可采用辅助namenode的架构。辅助namenode会在检查点时从主namenode上获取文件系统映像fsimage文件和编辑日志edits文件,当主namenode故障时,使用-importCheckpoint选项启动namenode守护进程,可将辅助namenode用作新的主namenode。不过此时恢到的仅是最近一次检查点的状态,而非最新状态。
数据层面由于HDFS本身具有将文件的数据块复制数个复本放置到集群上数个独立机器(复本的数量,可以通过修改hdfs-site.xml配置中的dfs.replication参数调整),当部分数据块损坏或者机器故障的情况下,丢失的数据块会自动将其他完好的复本复制到另一台可以正常运行的机器上,保证复本数量回到正常水平的机制。无需再采用其它容灾同步备份解决方案。
七
结论
本文提出的基于传统关系型数据库和Hadoop,共同构建分级存储管理的,服务于数据挖掘分析的企业海量数据仓库系统,在架构上保留了传统关系型数据库作为数据挖掘模型数据库,引入Hadoop来作为大量半、非结构化数据以及离线数据的存储系统。并就数据的分类放置策略,采用的数据迁移工具,存储管理策略和两级存储系统的高可用性分别给出了设计。作为传统数据仓库向分级存储平台演进的方案具有过渡平滑,技术成熟,可实施性高的特点。
本文供稿于
“上海移动王之恒,潘钢”
以上是关于分级存储管理数据仓库系统设计与实现的主要内容,如果未能解决你的问题,请参考以下文章