数据仓库起因与架构
Posted 数舟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库起因与架构相关的知识,希望对你有一定的参考价值。
数据仓库诞生的原因有很多,但无非是从两个方面衍生出来的。即数据分析和数据积存。
1、数据分析:企业为了满足数据分析的需要,并且为了避免各个部门自己建立独立的数据抽取系统,导致不同部门在不同时间里从业务数据库中抽取的数据不一致,致使决策失误等问题,从而建立的统一的数据仓库来存放数据,为各个部门提供统一的数据,便于企业做数据分析、辅助决策。
2、数据积存:随着企业业务数据增多,业务数据库累积了大量数据,但时间较为久远的历史数据使用频率很低,且堆积在业务库中导致数据库性能下降。于是希望建立统一的数据仓库,用来积存业务库中的历史数据,减轻业务库的负担。

所以数据仓库的目的是为了用于历史数据的存储和分析计算。

因为这两个原因建立的企业数据仓库,在实现上一般会划分为贴源层、ODS层、数据明细层、数据汇总层、主题模型层5个层级。当然不同企业的架构会有不同的删减。
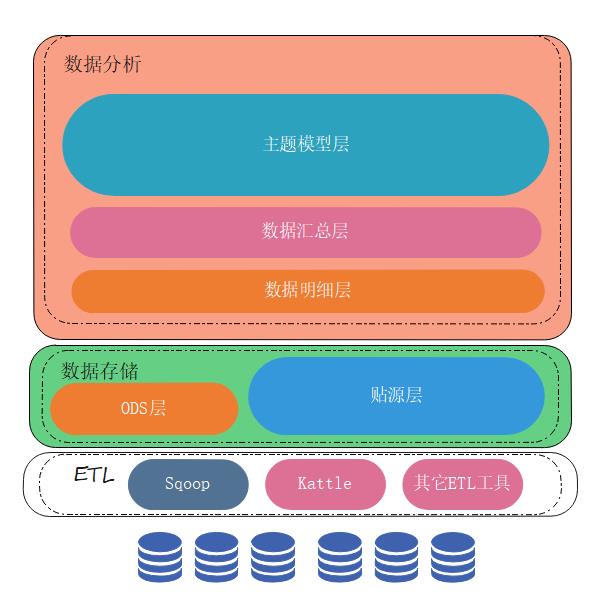
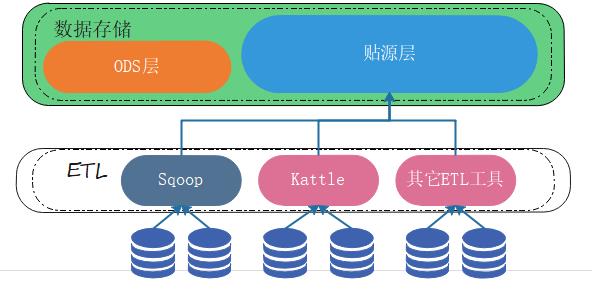
业务数据库定期通过ETL抽取到数据仓库中,会进入到贴源层,这一层的数据与业务库的数据保持一致,目的是存放业务库的历史数据。一般而言,一天会进行一次数据抽取,存放到贴源层中。贴源层的数据不允许修改,是只读的。但允许数据在ETL的时候(进入贴源层之前)加入一些字段,如更新时间、来源系统、更新类型等。(在保证数据一致的情况下,可以适当增加数据,便于管理)
这里说一下数据更新这个新加入的字段,数据在进入到贴源层时,更新类型这一个字段的值统一为INSERT,表明进入数据是直接新增进来的。如果数据更新后,这一这段的值会变为UPDATE,标志数据是更新后的。
但既然贴源层的数据不允许修改,那何来更新这一说呢?
之前说到,数据仓库的目的之一是为了存储业务数据库的历史数据,帮助业务库减负。既然是减负,那么数据在进入到数仓后,业务库一定会删除相应的历史数据。
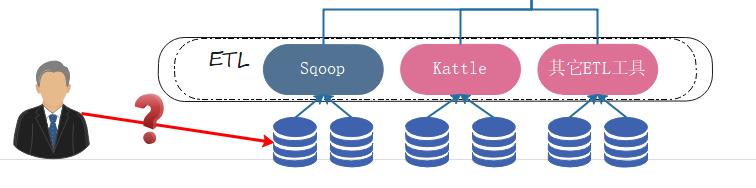
历史数据虽然访问的频率不高,但业务中肯定会有查询甚至修改的操作,那这些操作在业务库找不到对应的数据,就会落到数据仓库的贴源层中。
但贴源层数据是只读的,不允许进行数据修改,于是ODS层就出现了,数据仓库中的ODS层的作用就是从贴源层中读取数据,然后进行处理,处理后看情况再放回到贴源层中。
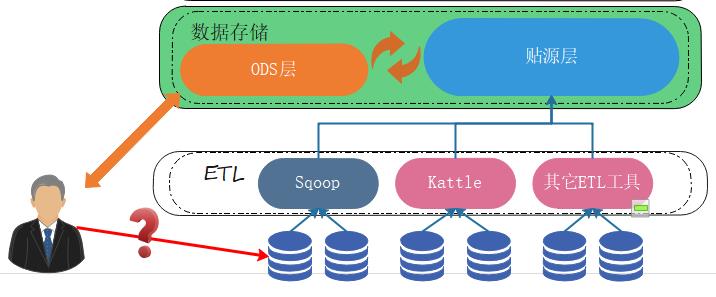
ODS层不用来存储数据,它只是业务与数据仓库的一个接口,用来查询和操作数据仓库的数据。
那么业务中对于历史数据的查询,就可以直接落到ODS中,ODS查询后将结果返回,那业务如果对历史数据的修改也是在ODS中完成的,ODS从贴源层拿到数据,修改后再追加到贴源层中,那么之前数据的更新标志位INSERT,在ODS中将数据修改后,再追加到贴源层中,标志位就会变成UPDATE。
贴源层和ODS层完成了历史数据的存储,减少了业务数据库的数据积存。那还有一个问题待解决-----数据分析。
贴源层中的数据来自不同的业务库,而且可能每个省份都有一个业务数据库。那么这些数据抽取到贴源层之后可能是多张表(一个省份一张),于是需要对数据进行轻度汇总,将多张表进行汇总,然后存储到数据明细层中,完成对数据的初步整理。
数据明细层的数据是不能直接用来分析计算的,因为明细层的数据还是满足三范式的,所以在数据分析的时候性能会比较差,会涉及到大量表的join合并。需要根据分析计算的主题,对明细层的数据进行合并,处理成大宽表后存储到数据汇总层中,为数据分析做准备。
数据汇总层中的数据已经脱离了三范式,完全满足分析计算的需要。于是数据分析任务会落到数据汇总层中进行计算,计算得到的结果会保存到主题模型层中。
主题模型层其实就是我们所说的数据集市。因为数据仓库是为了数据分析而生的,数据存储在数据仓库中直接暴露给前端进行OLTP的查询、处理会对性能造成很大的影响。而且数据仓库本身并不能满足业务的多种需求(并发查询、搜索检索)。
所以数据集市负责对处理后的数据进行存放,满足业务的不同需求,如果是要进行并发查询,那一般会进行预处理计算,并做成CUBE模型,然后存储到HBase中。如果要满足搜索检索业务,那会将结果数据存储到ES中。
数据集市是为业务而生的,提高了业务的查询效率,并满足业务的多种要求,且减轻了数仓的压力。
关于数仓的建设,不同企业有不同的方案,层次的划分也略有不同。在实现上,也会采用多种不同数据库来共同完成数仓搭建。但数仓需要解决的问题和原理是相同的。
看到这里,关于数据仓库,你懂了吗?记得订阅,下期见!
以上是关于数据仓库起因与架构的主要内容,如果未能解决你的问题,请参考以下文章