建模方法论数据仓库系列03
Posted 晓阳的数据小站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了建模方法论数据仓库系列03相关的知识,希望对你有一定的参考价值。
(一)建模的涵义
建模,顾名思义,就是建立模型的意思,为了针对理解产品、业务、应用逻辑之间的相互关系而做的抽象,用于避免理解歧义。建模通常用文字配合模型的方式,将复杂的事物描述清楚,便于自己及他人的理解。如果把数据比作是图书馆里的书,那么建模就相当于合理规划图书馆的布局,能够让读者迅速而合理的找出目标书籍。
(二)为什么需要建模方法论
数据仓库的概念是建立在大数据的基础知识上,而大数据拥有良好的性能、廉价的成本、极高的效率及可控的质量四大优势,但同时大数据又存在业务关联广泛、计算流程复杂、管理难度较大等问题,因而十分需要通过建模方法论来更好的组织和存储相关数据。
举个例子,产品经理提出了一份文档,描述的事件过程如下:
第一步:搭建广告主注册平台,填写广告主名称、网站名称、网址Url、行业属性等基本信息;
第二步,根据已有的注册信息,生成自动化的BaseCode,广告主根据需要将BaseCode部署在使用界面,BaseCode可以获取网页的Header、html、停留时长等信息;
第三步,BaseCode扩展后可提供页面基础检测PageView及页面事件监控Event事件,当页面正常打开时,触发一次PageView事件,记录当前网址Url、追踪Id、停留时间等信息;当页面某个控件被点击时,记录对应的Event组件名称;
第四步,创建落地转化信息,广告主可以创建转化统计Conversion,每个广告主可以创建50个转化统计,创建后只可以修改名称,不能修改规则;
第五步,设定转化统计方式,其一是在BaseCode的基础上添加EventCode,使用Url规则进行统计,其二是自定义代码统计方式,需提交对应的代码详情和部署说明;
第六步,开启转化统计,根据追踪ID,记录每个页面的打开情况,并对应统计页面控件的点击详情,关联其他相关信息,产出报表。
这是一个常见的典型案例,一般情况下产品不会画好UML图让程序员来设计,需要我们数据开发人员自行理解并分析其中包含的关联关系,这时候通过何种方式分析,让不同部门之间能够达成一致,就显得特别重要。
先介绍一些基础的建模方法论,再回过头来看这个例子。
(三)ER模型
百度百科介绍:ER模型,全称为实体联系模型、实体关系模型或实体联系模式图,由美籍华裔计算机科学家陈品山发明,是概念数据模型的高层描述所使用的数据模型或模式图。
E-R模型的构成成分是实体集、属性和联系集,其表示方法有如下三种:
1. 实体集用矩形框表示,矩形框内写上实体名;
2. 实体的属性用椭圆框表示,框内写上属性名,并用无向边与其实体集相连;
3. 实体间的联系用菱形框表示,联系以适当的含义命名,名字写在菱形框中,用无向连线将参加联系的实体矩形框分别与菱形框相连,并在连线上标明联系的类型,即1—1、1—N或M—N。
因此,E-R模型也称为E-R图。下图为一个典型的E-R模型示例:
(四)维度建模
百度百科介绍:维度建模是数据仓库建设中的一种数据建模方法,将数据结构化的逻辑设计方法,它将客观世界划分为度量和上下文,Kimball最先提出这一概念。
维度建模其最简单的描述就是,按照事实表,维度表的方式来构建数据仓库。维度是度量的环境,用来反映业务的一类属性;事实表是维度模型的基本表,每个数据仓库都包含一个或者多个事实数据表。维度建模最被人广泛知晓的一种方式就是星型模式。
阿里巴巴电商系对于维度建模有一些非常好的扩展补充,例如维度表可以分为快照维表、缓慢变化维表等,事实表可以分为事务事实表、周期快照事实表和累计快照事实表,这些概念解释起来非常的复杂,应用场景也比较极限,因而会用独立的文章来分别阐述。
下图为一个典型的维度建模示例:
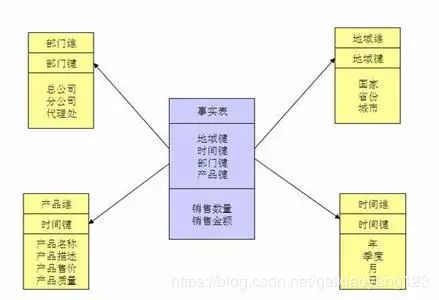
(五)E-R模型与维度模型的异同
E-R模型与维度模型是我们最常用的建模方法论,两种方式之间的异同有必要单独讲一下:
E-R模型备受数据仓库之父Inmon推荐,常用在mysql、Oracle等传统关系型数据库。它的目标是从全局的高度来设计一个满足3NF的模型,并不针对某个具体的业务流程。E-R模型的优点有如下几种:规范好、冗余小、集成度高、一致性强,适用于大型银行这一类的大型企业总体层面上的规划。但E-R模型的缺点就是优点的反面,因为太过于全面和复杂,因而对项目实施的时间和人员的要求非常高。
维度模型备受另一位大师Kimball所倡导,常用在NoSql等大数据仓库结构上。它的目标是从分析决策的层面出发构建模型,针对大规模复杂业务场景的响应性能有较好的表现。典型的代表是我们比较熟知的星形模型、雪花模型等。维度建模理解起来比较容易,上手比较快,但由于冗余了很多信息,修改起来灵活性就不太理解。在PB及以上数量级的数据仓库中,一般情况下以性能为优先,庞大的集群对于数据的冗余是可以接受的,并且因为DWS中间层的建设减少了非一致性的问题,因而多采用维度模型来构建数据仓库。
(六)DataVault模型
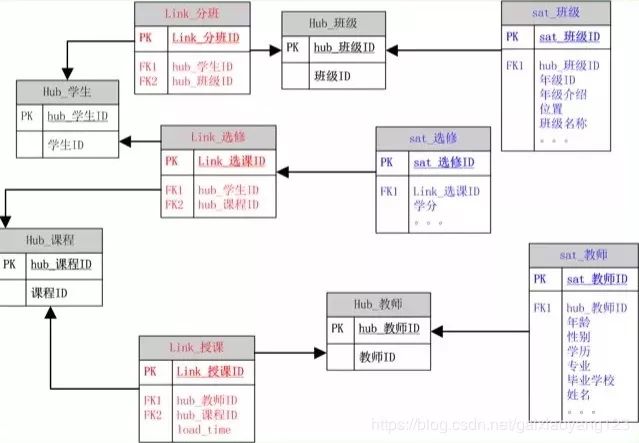
DataVault是E-R模型的衍生版本,针对复杂笨重的E-R模型,强调有基础数据层的扩展性和灵活性,同时强调历史性、可追溯性和原子性,不要求对数据进行过度的一致性处理。DataVault模型是一种中心辐射式模型,其设计重点围绕着业务键的集成模式,业务键是存储在多个系统中的、针对各种信息的键,用于定位和唯一标识记录或数据。DataVault有三种基本结构:中心表(Hub):唯一业务键的列表,唯一标识企业实际业务,企业的业务主体集合;链接表(Link):表示中心表之间的关系,通过链接表串联整个企业的业务关联关系;卫星表(Satellite):历史的描述性数据,数仓中数据的真正载体。
下图为一个典型的DataVault模型示例:
(七)Anchor模型
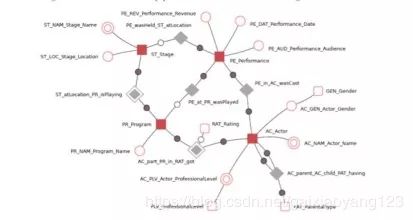
Anchor模型可以说是DataVault模型的衍生版本,做了进一步规范化的处理,设计初衷是为了更高可扩展性的模型,其核心思想是通过添加而非修改的方式来改进模型,因此将模型规范增加到了6NF。Anchor模型的组成有四种:Anchors,类似于DataVault中的Hub,代表业务实体,只有主键;Attributes,类似于DataVault中的Satellite,但全部存储为K-V结构,一个表只有一个Anchors的属性描述;Ties:描述Attributes之间的关系,单独用表来描述,类似于DataVault中的Link,用于提升模型关系的扩展能力;Knots,代表可能会在多个Anchors中公用的属性提炼,例如性别、状态等。
下图为一个典型的Anchor模型示例:
(八)随便说说UML
UML全称是Unified Modeling Language,统一建模语言,是用来针对建模方法论而使用的工具,并非建模方法论本身。在一些比较随意的场景中,理解对象之间的关系,我们可以随便写写画画就搞定,但是在跨团队、跨公司等情况下,没有一套系统的工具来统一大家的思想是不行的,这也是UML使用的初衷。
(九)为什么要学习建模方法论
回到开头的例子,这个例子笔者并不会在这里说明做的思路,因为后面会单独写一篇文章来说明这个需求的处理过程。
这里提一下,为什么要学习建模方法论?
很多时候,我们接到的并不是一份整理好的需求,大概率是一份产品的设计和使用文档,在此基础上,我们需要从中拆解出模块之间的关系,并设计对应的架构与关联关系。因此,我可以把产品提出的文档,当做是一个“问题空间”。那么针对这个问题空间,我需要有对应的方法来解决这个问题,我可以把使用的方法称之为“方法论”。在此基础上,我们就有了一种特定的解决问题的方式,称之为“解决方案空间”。标准的概念图如下所示:
为什么要有这个过程,是为了让数据开发人员、产品人员及平台开发人员达成模型上的一致性。也就是说,产品负责尽可能多的提供产品的描述方案,也就是“用例集”,开发人员之间通过相同的方法论,就可以针对这一批的“用例集”进行拆解,最终达成一致的:领域模型。概念图如下:
说到这里可能很多人不太理解这个思路,不要紧,后面会有专门的文章来阐述这种思路。但笔者这里要说的是,数据仓库建模方法论并非无用的知识,也并非读一读概念就可以理解,它需要你有实际的项目,这个项目要有一定的复杂性和团队合作性,要能够让你认识到跨团队合作的痛点。在此基础上,多花一些时间,尝试不同的建模方法论来描述你的项目,并与其他部门及产品进行反复的沟通,经历了这种过程之后,你才能体会到解释清楚一个项目有多么的难,也才能深刻的体会到建模方法论它其中的精妙之处。换句话说,如果只是单纯的学习建模方法论的概念,那么这是没有用的,方法论一定要有具体的项目来结合学习,才能起到它应有的效果。
以上是关于建模方法论数据仓库系列03的主要内容,如果未能解决你的问题,请参考以下文章