分享吧大数据之数据仓库研究
Posted 大连飞创
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分享吧大数据之数据仓库研究相关的知识,希望对你有一定的参考价值。
大数据之数据仓库研究

近年来,随着金融业务的快速发展,各大交易所针对监管的要求也越来越高。除了在实时监管中应用相关大数据技术外,还需要依托大量历史数据从多角度、多维度挖掘客户的违规情况。作为业务系统核心的数据库,面临着扩展性、业务连续性、成本和性能等方面的挑战。与此同时,互联网应用的飞速发展,使分布式技术领域出现了一些支持大规模、突发性、高并发量的分布式应用架构。本文结合大数据相关场景,对分布式数据库GreenPlum进行研究和应用探讨。
GreenPlum简介
1.GreenPlum是什么
对于很多人来说GreenPlum是个陌生的名字。简单的说它就是一个与ORACLE, DB2一样面向对象的关系型数据库。支持行、列、外部表多态存储。使用标准的SQL访问、支持存储过程,学习成本低,适用于OLAP系统。
2.GreenPlum与传统关系型数据库的区别
GreenPlum是一个关系型数据库集群。它实际上是由数个独立的数据库服务组合成的逻辑数据库。每个独立的数据库服务由PostgreSQL数据库提供。与Oracle RAC不同的是,GreenPlum数据库集群采取的是MPP Shared-Nothing架构,通过增加GreenPlum数据计算节点,性能会成线性增长。
3.GreenPlum成本
关于GreenPlum
GreenPlum采用MPP Shared-Nothing架构,因此,GreenPlum具有一些特殊的特性:
1.海量数据存储,数据均匀分布
GreenPlum将数据打散到所有计算节点,使所有计算节点数据均匀分布,每个计算节点存储、计算本计算节点的数据,可以将海量数据拆分成到每个计算节点中。
2.并行处理数据,快速返回结果
GreenPlum主节点和每个计算节点都有自己独立的CPU,内存和外部存储。主节点负责接收客户端请求后,将任务下发到每个计算节点,每个计算节点并行计算本节点的数据,计算后,主节点最后汇总查询结果返回给客户端,由于数据均匀分布在各个节点,因此可以快速返回结果。
3.性能水平扩展
GreenPlum由于每个计算节点有独立的硬件资源和独立的数据,每个节点都可以看作是一个独立的数据库,因此,通过增加计算节点,使每个计算节点的数据减少,整体并行度提高,性能会得到线性提升。
GreenPlum组件
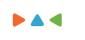
GreenPlum数据库组件分成三个部分Master、Segment以及Master与Segment之间的高效互联Interconnect。
1. Master
Maste,主节点。只负责应用的连接,语法分析,语义解析,执行计划生成并拆分执行计划,把执行计划分配给Segment节点,以及返回最终结果给应用。Master只存储一些数据库的元数据,不负责计算,因此Master不会成为系统性能的瓶颈。这也是GreenPlum与传统MPP架构数据库的一个重要区别。
2. Segment
Segment,计算节点。存储用户的业务数据,并根据得到的执行计划,负责处理业务数据。数据表的数据会打散分布到每个Segment节点。当进行数据访问时,首先所有Segment并行处理与自己有关的数据,如果需要,Segment可通过innterconnect进行彼此的数据交互。Segment节点越多,数据就会打的越散,处理速度就越快。因此与Share Everything数据库集群不同,通过增加Segment节点服务器的数量,GreenPlum的性能会成线性增长。
3. Interconnect
Interconnect组件负责Master和Segment之间,Segment和Segment之间在执行查询语句的时候的数据交换。
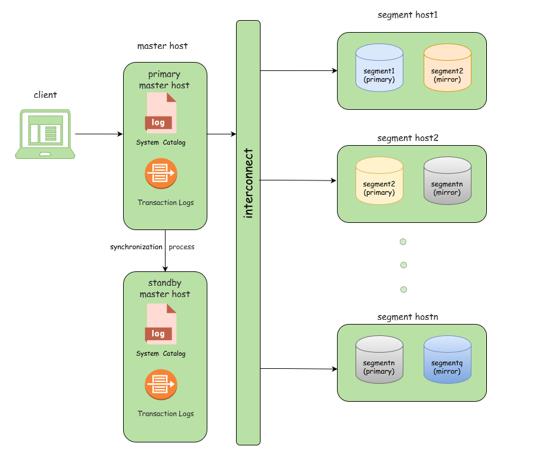
1.Master高可用
启动一个称为Standby(不同主机)的节点作为主节点的备份,通过流复制技术实现主节点和Standby节点两者的事务日志同步。当主节点出故障时,切换到Standby节点,系统继续正常工作,从而实现管理节点的高可用。
2.Segment高可用
每个Segment实例都会有另外一个Segment(不同主机)实例作为镜像。处于正常工作状态的Segment实例称为Primary Segment,它的备份称为Mirror Segment。对于每一个Segment实例,它的状态以文件的形式保存在本地存储介质中。这些本地数据可以分成三大类:本地系统表、本地事务日志和本地表分区数据。Segment通过以文件复制的方式保证Primary Segment和Mirror Segment之间的数据、状态一致,实现计算节点的高可用。
Segment表数据分布方式
Greenplum是分布式关系型数据库,因此,GreenPlum数据表中的数据是分散到各个计算节点中的。创建表时需要指定表的分布键,目的在于将数据平均分布到各个Segment。目前表的数据分布支持两种方式:
1. Hash
可以选择表的一个或者多个列作为分布键。分布键做Hash算法来确认数据存放到对应的Segment上,相似的Hash值的数据会放到同一个Segment节点上。在多表关联的时候,如果关联字段都是分布键,就可以在每个Segment节点关联后,Segment节点把结果发送到Master节点,再由Master节点汇总,将最终的结果返还客户端。
2.Randomly
数据会被随机分到Segment上,相同记录可能会存放在不同的Segment上。随机分布可以保证数据平均。在多表关联的时候,就需要将数据发送到所有Segment节点,Segment节点关联后将结果发送到Master节点,再由Master节点汇总,将最终的结果返还客户端。
执行计划
GreenPlum优化器GPORCA依靠计算CBO的方式来确定具体采用何种执行计划。常规的表扫描、连接和聚合的执行方式产生的代价外,还需要考虑数据的分布状态、数据重分布的代价,数据广播的代价以及集群计算节点数量对执行效率的影响,因为它最终是要生成一个分布式的查询计划。
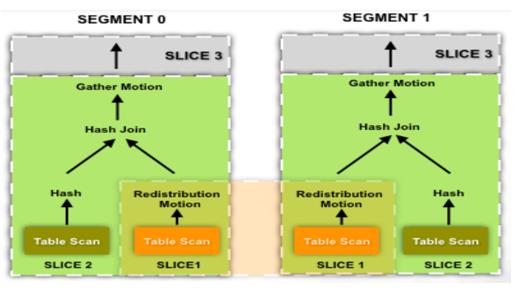
1.Gather
聚合,在master上将子节点所有的数据聚合起来。一般的聚合规则是哪一个子节点的数据先返回到master上就将该节点的数据先放在master上。
2.Broadcast
广播,发生在两表关联的时候。将每个节点上的某个表的数据全部发送到所有节点,这样每个节点都相当于有全量数据。一般,计算节点在关联小表的时候采用广播的方法将数据广播到所有计算节点。
3.Redistribution
重分布,发生在两表关联的时候和Group by的时候。当不满足广播的条件或者广播的代价太大的时候,选择重分布,即按照新的分布键将各个节点上的数据重新打散到各个节点后,进行计算。
4.Slice
切片,在实现分布式执行计划的时候,需要将SQL拆分成多个切片,每个Slice是单读执行的一部分SQL,每一个广播或者重分布会产生一个切片,每一个切片在每一个数据结点上都会对应的发起一个进程来处理该slice负责的数据,上一层负责该slice的进程会读取下级slice广播或重分布的数据,之后进行相应的计算。
与其他主流数据仓库对比
Oracle Exadata、Ibm Netezza、Apache Hbase都是目前主流的数据仓库,都可以支持大数据量的数据检索,以下内容为这几款数据库对比结果描述。
1.Oracle
Exadata 是目前大商所针对OLTP系统使用的业务数据库,具有极好的数据处理性能,但是Exadata 不易于扩展,成本较高,性能依据硬件条件的不同,会出现相应的处理瓶颈。
2.Ibm
Netezza是目前大商所针对OLAP系统使用的数据仓库,和Greenplum采用同样的MPP架构。但是Netezza不能扩展,成本较高,可调优空间小。
3. Apache
Hbase 是目前较为通用的数据仓库,采用Key-Value式存储,查询相应速度快。但是Hbase非关系型数据库,多维度数据查询灵活度低,数据冗余大。
4.Pivotal
GreenPlum是分布式关系型数据库,数据冗余低。数据库开源,使用成本低,增加计算节点即可线性提升性能,在海量数据下也可保持极高的性能。在大数据量下查询以及并发测试中,性能表现强劲。

GreenPlum的其他优势
强大的SQL支持能力和非常丰富的统计函数和统计语法支持,还可以用多种语言来编写存储过程,学习成本低。对于Madlib、R以及大数据算法的支持也很好。

以上是关于分享吧大数据之数据仓库研究的主要内容,如果未能解决你的问题,请参考以下文章