严选质量数仓建设——数据仓库基本概念
Posted 严选技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了严选质量数仓建设——数据仓库基本概念相关的知识,希望对你有一定的参考价值。

| 数据仓库 |
数据库 |
|
| 适合的工作 | 分析、报告、大数据 | 事务处理 |
| 数据源 | 从多个数据源收集和标准化的数据 | 从单个来源捕获的数据 |
| 数据捕获 | 批量写入操作通常按照预定的批处理计划执行 | 针对连续写入操作进行了优化,因为新数据能够最大程度地提高事务吞吐量 |
| 数据标准化 | 非标准化Schema | 高度标准化的静态Schema |
| 数据存储 | 使用列式存储进行了优化,可实现轻松访问和高速查询性能 | 针对在单行型物理块中执行高吞吐量写入操作进行了优化 |
| 数据访问 | 为最小化IO并最大化数据吞吐量进行了优化 | 大量小型读取操作 |
面向主题
业务数据库中的数据都是面向事务处理进行组织的,但数据仓库是面向主题存放,其目的是为了更好的组织数据,方面数据查询分析。
集成的
数据仓库中的数据来源广泛,通常会从不同的数据源抽取过来,需要在数据仓库中对数据进行清洗转换(编码统一、属性度量统一、描述统一、关键字统一,也就是ETL),重新编排,得到原始表与数据仓库表的映射结果。比如,不同系统中,订单号可能表示为task_id,也可能表示为order_id,当需要订单主题进行集成时,就需要将订单号标准化。
相对稳定
数据仓库的数据通常是批量的方式更新、访问,所涉及的数据操作主要是数据的查询,一般情况下并不会进行修改操作。当数据抽取到操作环境中后,只要没有误操作,数据不会轻易丢失掩盖。
反应历史变化
有的业务数据仅仅保留当前状态,数据进入数据仓库后,都会加上时间关键字以标记,存储历史状态,以此在时间维度上反映数据变化情况,帮助用户进行决策分析。
数据域
指面向业务分析,将业务过程或者维度进行抽象的集合。数据域是需要抽象提炼,并且长期维护和更新的,但不轻易变动,在划分数据域时,既能涵盖当前所有的业务需求,又能在新业务进入时,无影响地被包含进已有的数据域中和扩展新的数据域。
业务过程
指企业的业务活动事件,如下单、支付、退款等,都是业务过程(质量数仓中如提交bug就是业务过程)。业务过程是一个不可拆分的行为事件。
时间周期
用来明确数据统计的时间范围或者时间点,如近30天,自然周,截至当日等。
修饰词
指除了统计维度、时间周期以外,指标的业务场景限定抽象。修饰词隶属于一种修饰类型,如在流量域访问终端类型下,有修饰词PC端、无线端等。
修饰类型
是对修饰词的一种抽象划分,例如流量域的访问终端类型。
主题
主题就是指我们所要分析的具体方面。主题有两个元素:各个分析角度(维度),二是要分析的具体度量,一般通过数值体现。
维
维是用于从不同角度描述事物特征的,一般维都会有多层,每个level都会包含一些共有的或特有的属性。
度量/原子指标
度量就是要分析的具体的技术指标,一般为数值型数据,是业务定义中不可再拆分的指标,具有明确业务含义的名词,如支付金额。
维度
维度是度量的环境,用来反映业务的一类属性,这类属性的集合构成一个维度,也可以称为实体对象。维度属于一个数据域,如地理纬度、时间维度等。
维度属性
维度属性隶属于一个维度,如地理纬度里面的国家名称、省份名称等都属于维度属性。
派生指标
派生指标=一个原子指标+多个修饰词(可选)+时间周期。可以理解为,对原子指标业务统计范围的圈定。
粒度
数据的细分程度。
事实表
事实表是用来记录分析的内容的全量信息的,包含了每个事件的具体要素,以及具体发生的事情。事实表中的每行对应一个度量事件,每行的数据是一个特定级别的细节数据,称为粒度。
维表
维度表包含与业务过程度量事件有关的文本环境,用于描述与“谁、什么、哪里、何时”有关的事件。
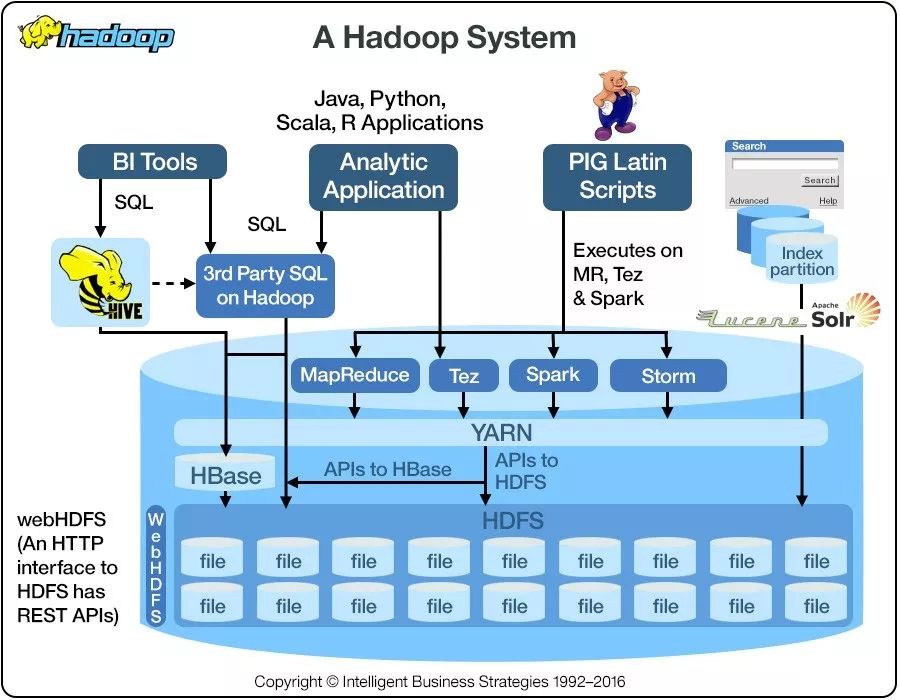
HDFS
Hadoop分布式文件处理系统,是Hadoop体系中,数据存储管理的基础。源自于Google的GFS论文,也既GFS的克隆版。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
Mapreduce
分布式计算框架,Hadoop MapReduce是Google Mapreduce克隆版,是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果;Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。Mapreduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
HBase
Hbase是Google Bigtable的克隆版,是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
Zookeeper
Zookeeper是Google Chubby克隆版。解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Sqoop
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之间传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
Pig
基于Hadoop的数据流系统,由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具,定义了一种数据流语言—Pig Latin,将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
Mahout
数据挖掘算法库,Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
Flume
日志收集工具,Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。
Hive
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。Hive定义了一种类似SQL的查询语言(HQL),将SQL转换为MapReduce任务在Hadoop上执行,通常用于离线分析,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
Yarn
Yarn是下一代Hadoop计算平台,主要是为了解决原始Hadoop扩展性差,不支持多计算框架而提出的。Yarn是一个通用的运行时框架,用户可以编写自己的计算框架,在该运行环境中运行,用于自己编写的框架作为客户端的一个lib,在提交作业时打包即可。该框架提供了资源管理、资源调度组件。
Tez
Tez是Apache最新开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output,Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
Spark
Spark是一个通用的并行计算框架,它提供了一个更快、更通用的数据处理平台,与Hadoop相比,Spark能够让程序在内存中运行时速度提升百倍。
Kafka
Kafka是Linkedin开源的分布式消息队列,主要用于处理活跃的流式数据。活跃的流式数据在web网站应用中非常常见,这些数据包括网站的pv、用户访问了什么内容,搜索了什么内容等。这些数据通常以日志的形式记录下来,然后每隔一段时间进行一次统计处理。
Ambari
Apache Ambari 的作用来说,就是创建、管理、监视 Hadoop 的集群,是为了让 Hadoop 以及相关的大数据软件更容易使用的一个web工具。
以上是关于严选质量数仓建设——数据仓库基本概念的主要内容,如果未能解决你的问题,请参考以下文章