数据仓库发展趋势与架构演进(1996-2020)
Posted 数据仓库与Python大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库发展趋势与架构演进(1996-2020)相关的知识,希望对你有一定的参考价值。
热文回顾:
一、数据仓库概述
1). 概念
Data warehouse is a
subject oriented,
integrated,
non-volatile and
time variant collection of data
in support of management’s decision
— [Inmon,1996]
-
面向主题的 联机交易型或操作型数据库的数据组织面向事务处理任务,而数据仓库中的数据是按照一定的主题域进行组织的。
-
集成的 数据仓库中的数据是在对原有分散的数据库进行数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据库中的不一致,以保证数据仓库内的信息是关于整个企业的一致的全局信息。
-
相对稳定的 数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询。一旦某个数据进入数据仓库以后,一般情况下将被长期保留。也就是说数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
-
反应时间变化的 数据仓库中的数据通常包括历史和实时数据。通过这些信息,可以对企业业务的运营现状、未来趋势等做出定量分析和预测。
-
支持管理决策 数据仓库一般不是面向最终客户,而是面向企业领导、业务部门和内部分析人员,用于决策分析等场景。
2). 发展阶段
-
固定报表阶段 通过预置的固定报表, 解决"what happen"问题。
-
即席分析阶段 通过增加即席查询, 解决"why did it happen"。 -
趋势预测阶段 引入数据建模,预测未来, 解决"what will happen"。 -
实时决策阶段 支持实时数据变化及查询, 解决"what is happening"。 -
主动决策阶段 基于事件驱动,主动决策, 解决"what do I want to happen"。
二、数据分层与建模
、
在数据仓库中,往往采用分层结构。数据逐层处理,每层可采用不同的处理机制及适合的存储方式。
STAGE - 预处理层
存储每天的增量数据,表与ODS层一致。
ODS - 操作数据层
做数据清洗,存储基础原始明细数据。
DW - 数据仓库层
一般采用维度、事实表设计。根据主题定义好事实与维度表,保存最细粒度的事实数据。
DM - 数据集市层
宽表化设计,形成公共指标。数据集市/轻度汇总层,在 DW层的基础之上根据不同的业务需求做轻度汇总所得。
APP - 数据应用层
数据个性化指标,面向最终展示,可做少量计算。
2). 数仓建模
-
ROLAP 关系模型,可细分为ER模型、星型模型和雪花模型等。其特点是与事务实体对应,关系清晰;但一般需要较为复杂的数据准备。在响应前端需求时,一般较快,但取决于计算引擎能力。 -
MOLAP 多维模型,可简单理解为将数据存放在一个n维数组中,而不是像关系数据库那样以记录的形式存放。因此它存在大量稀疏矩阵,人们可以通过多维视图来观察数据。它的优势在于响应较快、分析灵活、但数据准备时间较长。 -
HOLAP 混合OLAP,顾名思义,由MOLAP和ROLAP组成。
三、数据仓库架构演进
1). 传统数仓架构

3). Lambda架构

4). Kappa架构

5). 混合架构
四、数据仓库发展趋势
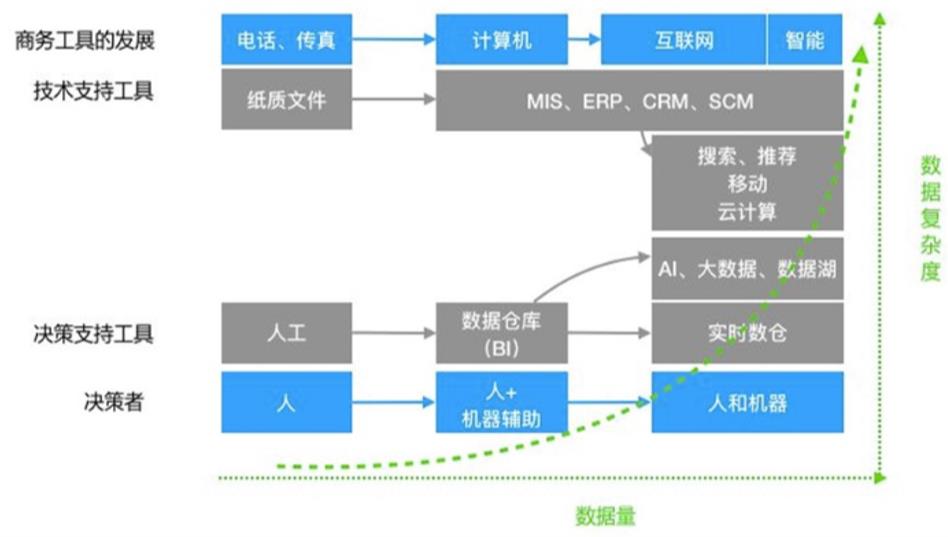
上图摘自网上的一幅图,总结了数仓的发展趋势,总结如下:
-
实时 随着企业数字化转型,对数据的实时性要求越来越高。未来传统离线数仓将逐渐消失,实时方式将成为主流方式。 -
海量 数仓承载的体量将越来越大,十亿、百亿级别、TB甚至PB级别,将成为数仓的容量刚需。 -
多模 半结构化、非结构化数据,将更多被使用在数仓领域,发挥出更大的价值。 -
多元 数据使用方式,将出现多元化特征。除常规的复杂查询、高频点查等外,搜索类、向量计算等也成为常规计算需求。在单一平台提供更加丰富的计算能力,对于客户来说不在需要频繁移动数据,一站式解决。 -
虚拟 传统的大集中方式,存在诸多问题。如果构建轻量化的解决方案,无需搬动数据即可形成虚拟数仓,解决客户问题成为数仓的基本能力。 -
治理 数仓除了传统的数据存储、计算能力外,还需提供完备的数据治理能力。包括元数据、数据血缘、数据质量等等,构成数据全生命周期的管理平台。
-
智能 数据使用上,AI、ML将赋能数据应用,这些都需要在数仓平台提供支持能力。
推荐阅读
往期推荐

(备注:行业-职位-城市)
01. 后台回复「经典」,即可领取大数据数仓经典书籍。
02. 后台回复「中台」,即可领取大厂中台架构高清ppt。
03. 后台回复「加群」,或添加小助微信ID:iom1128 拉您入群(大数据|数仓|分析|Flink|资源)或领取资料。
Q: 关于数据仓库,你还想了解什么?
欢迎大家扫描下方二维码订阅「数据仓库与Python大数据」内容并推荐给更多数据方向的朋友,希望有更多机会和大家交流。
更多精彩,请戳"阅读原文"到"数仓之路"查看
!关注不迷路~ 各种福利、资源定期分享!
以上是关于数据仓库发展趋势与架构演进(1996-2020)的主要内容,如果未能解决你的问题,请参考以下文章