数据仓库之创作者分层模型服务构建
Posted 一个数据人的自留地
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库之创作者分层模型服务构建相关的知识,希望对你有一定的参考价值。
是新朋友吗?记得先点蓝字关注我哦~
关注免费获取资料
1、可免费领取数据相关的面试题+面试攻略。
2、可免费领取<中台>相关的资料;
3、进交流群,认识更多的数据小伙伴。
前言
一、数据流程方案
二、数据接入
INSERT OVERWRITE TABLE tmp_zapee_creator_follow_detail_di PARTITION(dt = '2020-03-04')SELECTid,userId AS user_id,targetUserId AS target_user_id,app,(CASE WHEN deleted = 1 then 1 WHEN deleted = 0 then 0 else -1 end) deleted,creation,modificationfrom Follow.FollowWHERE modification < '2020-03-05 00:00:00'MSCK REPAIR TABLE prod_creator.tmp_zapee_creator_follow_detail_di;INSERT OVERWRITE TABLE {0}_creator.ods_zapee_creator_follow_hiSELECTid,user_id,target_user_id,app,deleted,creation,modification,'{1}' AS start_date,'9999-12-31' AS end_datefrom prod_creator.tmp_zapee_creator_follow_detail_diWHERE dt = '2020-03-04'
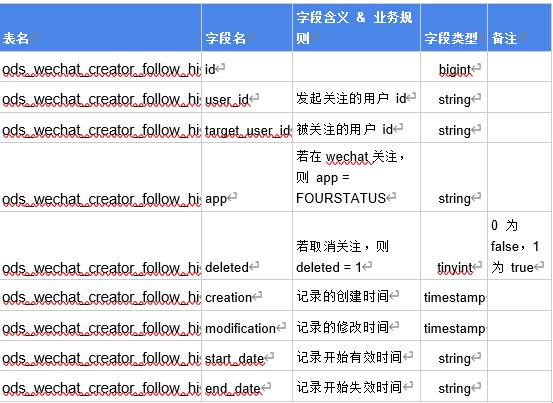
三、数据ETL逻辑
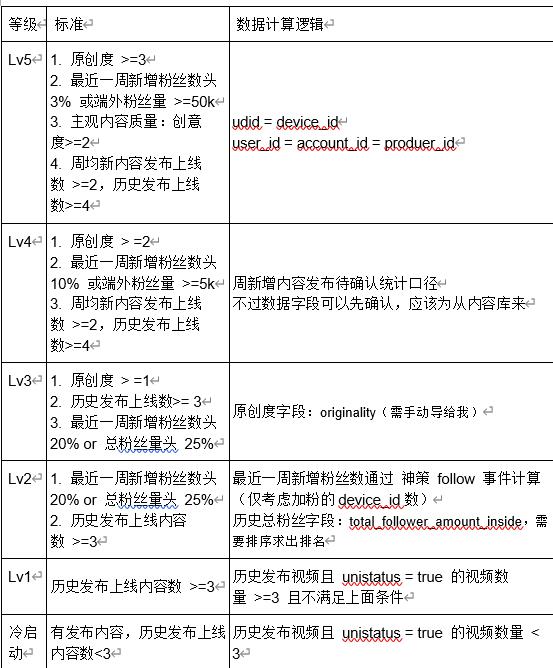
四、创作者分层关联指标
一个数据人的自留地是一个助力数据人成长的大家庭,帮助对数据感兴趣的伙伴们明确学习方向、精准提升技能。
扫码关注我,带你探索数据的神奇奥秘
以上是关于数据仓库之创作者分层模型服务构建的主要内容,如果未能解决你的问题,请参考以下文章