之家数据仓库介绍
Posted 之家技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了之家数据仓库介绍相关的知识,希望对你有一定的参考价值。
汽车之家作为全球访问量最大的汽车网站,为汽车消费者提供看车、买车、用车等所有环节的全面、准确、快捷的一站式服务。经历十五年的发展历程,汽车之家积累丰富的行业经验和海量的业务数据,随着互联网时代的推进,用户的使用需求变的越来越多样化,业务场景变的越来越复杂,之家也提出了基于数据技术的战略转型,重视数据,发挥数据财富的作用,更好的服务于业务。
在汽车之家庞大的业务线条中,业务运营场景多变复杂,一直存在着各种各样的痛点问题:
基于各业务面临的这些痛点问题,需要站在公司层面集成各类数据并统一计算口径以一致的形式对外提供准确、易用、高效、可理解的数据。
汽车之家数据仓库是利用开源大数据技术建立在公司层级按照一定的主题划分进行组织架构的互联网数据仓库,实现了离线、实时计算数据统一,集成了各业务、各系统的数据、日志采集数据、线下文档及非结构化数据等,覆盖全公司各业务生产线及各类A
PP
日志,稳定持续的接入入仓,记录保存其历史变化情况。
如图1所示:之家数据仓库组成主要包括:源系统、数仓E
TL
过程、数据展现、数据应用。
源系统:
包含操作型源业务系统、日志采集系统、外部文档及非结构化数据等,严格意义上源系统不属于数据仓库一部分,从源系统抽取接入的数据不加任务控制。
数仓E
TL
过程:源系统的数据按照增量、全量方式抽取加工到基础数据层(拉链表、流水日志存储);对基础层数据加工整合、轻度聚合、高度聚合后到通用数据层,包含按主题划分的业务过程明细数据和统一维度汇总指标数据,通用数据层也是数据仓库核心层,为数据展示层提供支持。
数据展现:该环节根据项目和业务需求组织数据,使用数仓E
TL
加工处理后的数据,按照统一维度高度聚合的指标数据,支持不同业务组织项目、数据产品、个性化需求的数据展现。
数据应用:即数据的应用场景,是数据仓库产出数据的对外赋能,面向各业务部门和使用数仓的用户提供数据查询、BI产品应用、数据建模分析预测、数据挖掘等。
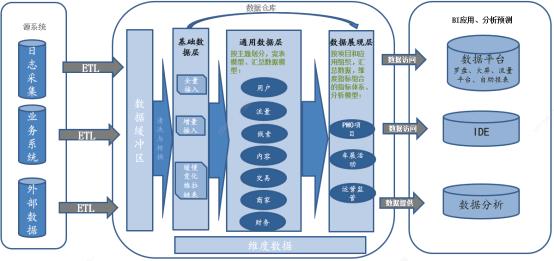
图1-数据仓库组成
图2是之家数仓架构图,采用hadoop分布式架构,实现离线、实时数据统一,丰富的数据产品及高效的数据查询支持。
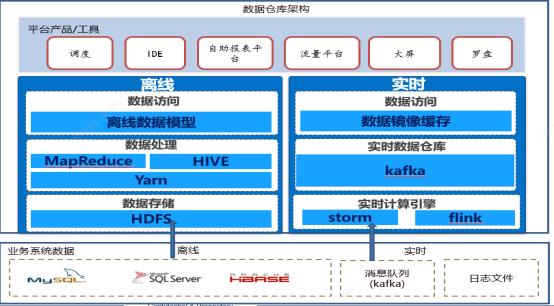
图2-数据仓库架构
之家数据仓库采用主流维度建模、宽表模型建模规范分层架构设计,数据分类、分层管理,包含详细的原子数据及各类多维汇总聚合数据。以一致的形式展现信息,方便的存取信息,为各业务部门提供全方位完整的数据信息,方便各种数据计算统计。
分层
建模
能够从让性能、成本、效率、质量几个方面实现最优的解决方式:
性能:
通过
分层设计对不同颗粒度数据进行聚合
预处理
,
来提升
数据应用
的用户体验
,
提高数据查询效率,
减少数据的I/O吞吐。
成本:
通过分层设计极大地减少了不必要的重复计算,
也能实现计算结果的复用,
从而大大降低
大数据系统中的存储和计算成本。
效率:
通过分层设计可以以用户更易理解的方式发布数据,
改善用户使用数据的体验,
支持大部分的数据需求,
提高使用数据的
便捷性
。
质量:
通过分层设计规范数据统计口径的统一,保证数据质量,避免不同用户对同一业务查询数据不一致的问题
,减少数据计算错误的可能性。
如图3所示分层模型包括:RDM层(数据展现层)、ADM层(聚合数据层)、GDM层(通用数据层)、FDM层(基础数据层)、Stage/BDM层(数据接入层)、维度层dim、临时层tmp。
图3-数据仓库分层设计
R
DM
:按照项目和应用组织数据,以汇总数据为主体,规划多样化、个性化的衍生指标体系、分析模型和数据应用。
ADM:
该层级是通用数据层的扩展,定位业务视角,以业务需求为驱动进行模型设计,作为宽表模型的补充,按照统一维度进行指标轻度、高度聚合,指标标准化为应用层和下游集市提供统一口径。
GDM:
该层的主要功能是基于主题域的划分,面向业务主题、以数据为驱动设计模型,并且基于星型建模,到明细数据粒度,为方便各个指标统计提供基础数据来源支持。
FDM:
该层级主要功能是存储从源系统直接获得的数据(数据从数据结构、数据之间的逻辑关系上都与源系统基本保持一致),模型设计采用拉链表、流水日志两种方式加工存储,数据源来自Stage/BDM层。
Stage/BDM:
按增量、全量抽取接入业务库、日志等数据,结构与业务系统一致,该层只为基础层加工数据服务。
DIM:
该层主要存储简单、静态、代码类的维表,包括从OLTP层抽取转换维表、根据业务或分析需求构建的维表以及仓库技术维表如日期维表等。
TMP:该层级独立于其他层级之外,其来源可以是任意层级,主要存放的是技术过程中需要临时存放的数据。
之家数据仓库结合了Bill
I
nmon提出的范式建模以及
Kimball
大师提倡的
自下而上
理论
的
维度建模思想
,
采取以需求驱动为主、数据驱动为辅的混合模型设计方式,以满足大数据环境下庞大的业务数据及多样频繁变更的数据结构,即能够根据需要快速响应各种复杂的业务需求,又能够以企业视角保证数据的标准化。对业务数据按主题划分并以用户易理解的方式一致性的发布数据,确保数据质量。
准确性:
分层模型设计,数据建模即开始管控数据质量,保证数据准确性。
一致性:
采用企业数据总线建立一致性的维度、指标;
实现离线、实时计算的口径统一。
高效性:
合理使用缓慢变化维、增加冗余,脚本任务高并发调度,数据分区、分桶存储,保证数据计算的高效和查询使用的高效。
之家大数据技术运用不断更新迭代,日趋成熟,为了提升数据生产力,自建了一套大数据服务应用工具链(采集平台、数据直通车、统一调度系统、数据可视化、元数据管理),为数据入仓、加工、管理、展现等全流程提供支持,保证了数据仓库各环节操作的简单、高效:
1、
源系统数据接入的简洁高效性,提供增量、全量接入方式,拉链表、流水日志加工存储方式,借助直通车平台可实现全链路自动化,自动创建调度任务、生成加工脚本、创建库表模型结构,数据自动初始化,大大提高工作效率,减少人工成本。
2、
数据产品指标达到9
0
%以上实时化,完全按照离线口径开发实现,确保实时、离线口径的统一,设计完成了包括实时流量宽表模型、实时推荐搜索模型、U
AS
模型等,目前,依托自研的实时计算平台可支持Flink SQL配置化开发,仅有sql基础的人员亦可完成实时数据开发。
3、 元数据管理系统完美支撑,主要包括血缘关系管理、数据知识管理,提供分层模型介绍查询及追溯数据加工链路,为数据使用人员提供更好的帮助。
数据的应用即是数据仓库产出数据的对外赋能,之家数据仓库是建立在公司层级的统一互联网数据平台,面向各B
U
数据团队、数据分析规划团队、数据B
P
团队等用户开放数据使用,即可以进行简单的数据查询,又支持B
I
数据产品呈现、数据建模分析预测、数据挖掘,同时为高层领导决策提供权威和可信数据支持。
B
I
数据产品:包括之家数据罗盘、数据大屏、流量数据平台、北斗系统等,展现指标数据统一由数据仓库加工输出,确保口径统一、数据准确及时;利用之家自研的可视化配置工具Auto
B
i,拥有丰富的可视化组件库,通过拖拉维度、指标配置实现可视化产品开发。
分析预测:UVBN数据分析模型依托数仓输出的各类统计数据,通过从用户基础属性、用户价值、用户需求方面出发进行分群分析预测,提升高层决策能力,实现数据商业价值,让数据更好的服务于业务。
企业的数据建设是一个任重而道远的征途,目前,各大企业都拥有自己的数据仓库,实现了将业务数据化,但大都停留在
以BI报表看数为主阶段,
想要实现以分析、预测为主,以数据驱动业务,分析把握业务动向、精准预测未来的业务变革,真正实现数据操作的智能化还有很长的路要走,仍需要继续夯实数据基础,加大成本投入来推动企业数据的建设。
汽车之家拥有大量的使用用户,拥有众多大数据技术人才,数据技术不断更新迭代,在基于数据技术战略思想指导下,将会一直驱动我们在数据建设的道路上不断前进,再创辉煌。
欢迎行业内各领域青铜王者交流、探讨,并提出您的宝贵意见,谢谢!
以上是关于之家数据仓库介绍的主要内容,如果未能解决你的问题,请参考以下文章
汽车之家:基于 Flink + Iceberg 的湖仓一体架构实践
汽车之家基于 Flink + Iceberg 的湖仓一体架构实践
在现有ERP系统下如何建立数据仓库?
大数据企业大数据平台的数据仓库架构大数据和人工智能的关系
数据仓库面试题——介绍下数据仓库
数据仓库术语介绍