创业公司数据仓库的建设
Posted 大数据技术与架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了创业公司数据仓库的建设相关的知识,希望对你有一定的参考价值。
本文将重点探讨数据处理层中数据仓库的建设。早期的数据服务中存在不少问题,虽然在做运营Dashboard系统时,对后台数据服务进行了梳理,构建了数据处理的底层公共库等,但是仍然存在一些问题:
中间数据流失,计算结果没有共享。比如在很多数据报告中都会对同一个功能进行数据提取、分析,但是都是各自处理一遍,没有对结果进行共享。
数据分散在多个数据源,如mysql、MongoDB、Elasticsearch,很难对多个源的数据进行联合使用、有效组织。
每个人都需要非常清楚产品业务逻辑才能正确地提取、处理数据,导致大家都将大量时间耗费在基础数据处理中。
于是,我们考虑建设一个适于分析的数据存储系统,该系统的工作应该包含两部分:第一,根据需求抽象出数据模型;第二,按照数据模型的定义,从各个数据源抽取数据,进行清洗、处理后存储下来。虽然数据仓库的学术定义有很多版本,而且我们的系统也没有涉及到多部门的数据整合,但是符合上述两个特点的,应该可以归结到数据仓库的范畴了,所以请允许笔者将本文命名为“数据仓库的建设”。
下图所示,为现阶段我们的数据仓库建设方案。数据主要来源于MySQL和MongoDB中的业务数据、Elasticsearch中的用户行为数据与日志数据;ETL过程通过编写Python脚本来完成,由Airflow负责任务流的管理;建立适于分析的多维数据模型,将形成的数据存入MySQL中,供数据应用层使用。可以看到,数据仓库本身既不生产数据也不消费数据,只是作为一个中间平台集中存储数据,整个系统实现的重点在于数据建模与ETL过程,这也是日常维护中的重点。
要不要Hadoop? 生产业务数据库与用户行为数据增长均比较缓慢,预计在接下来的一年里数据仓库的总存储量不会超过500GB 。因此现阶段接入Hadoop的意义不大,强行接入反而会降低工作效率。而且团队主要技术栈是Python,使用Python操作Hadoop本身就会有性能损耗。
为什么是MySQL? 相比Oracle,团队对MySQL更加熟悉,所以笔者更多的考虑是选择MySQL的哪个存储引擎:Infobright vs. myisam vs. innodb。Infobright引入了列存储方案,高强度的数据压缩,优化的统计计算,但是目前已经没有社区版了,需要收费。抛开底层存储的区别,myisam与innodb在特性上的区别主要体现在三个方面:第一,引用的一致性,innodb有外键,在一对多关系的表之间形成物理约束,而myisam没有;第二,事务,innodb有事务操作,可以保证一组操作的原子性,而myisam没有;第三,锁级别,innodb支持行锁,而myisam只支持表锁。对于外键与事务,并不是数据仓库需要的,而且数据仓库是读多写少的,myisam的查询性能优于innodb,因此myisam成为首选。
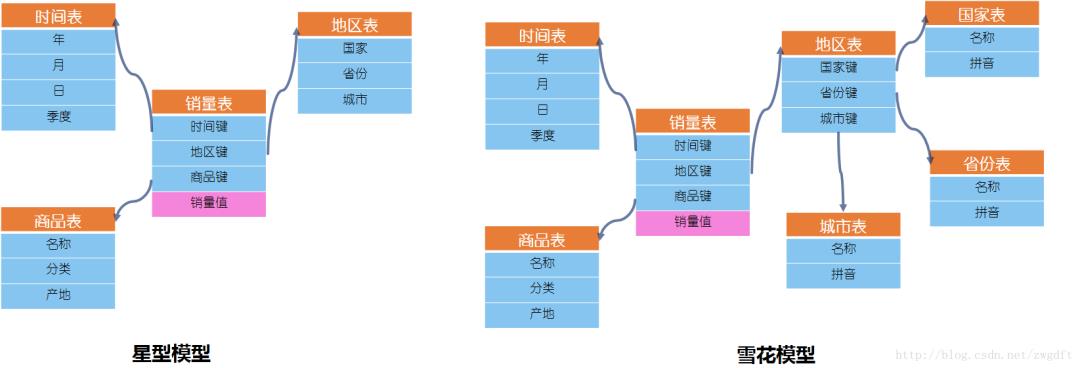
维度表与事实表。维度表,描述的是事物的属性,反映了观察事物的角度。事实表,描述的是业务过程的事实数据,是要关注的具体内容,每行数据对应一个或多个度量事件。比如,分析“某地区某商品某季度的销量”,就是从地区、商品、时间(季度)三个角度来观察商品的销量,维度表有地区表、商品表和时间表,事实表为销量表。在销量表中,通过键值关联到三个维度表中,通过度量值来表示对应的销量,因此事实表通常有两种字段:键值列、度量值列。
星型模型与雪花模型。两种模型表达的是事实表与维度表之间的关系。当所有需要的维度表都直接关联到事实表时,看上去就是一颗星星,称之为星型模型;当有一个或多个维表没有直接关联到到事实表上,而是通过其他维度表连接到事实表上时,看上去就是一颗雪花,称之为雪花模型。二者的区别在于,雪花模型一定程度上降低了信息冗余度,但是合适的冗余信息能有效的帮助我们提高查询效率,因此,笔者更倾向于星型模型。
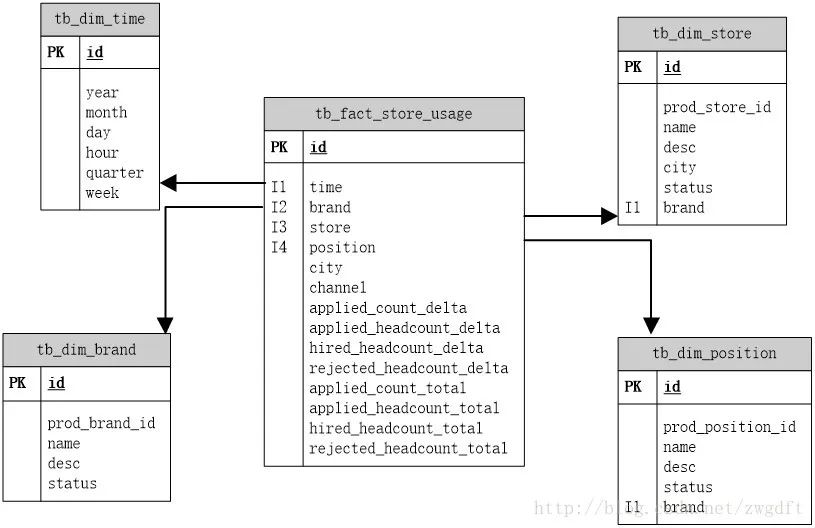
基本的维度建模思路。维度建模的基本思路可以归纳为这么几点:第一,确定主题,即搞清楚要分析的主题是什么,比如上述的“某地区某商品某季度的销量”;第二,确定分析的维度,准备从哪几个角度来分析数据;第三,确定事实表中每行的数据粒度,比如时间粒度细化到季度就可以了;第四,确定分析的度量事件,即数据指标是什么。
可以看到我们只建立了四张维度表,地区维度和渠道维度是直接以字符串的形式放到事实表中的。这是维度设计中经常遇到的一个问题:如果这个维度只有一个属性,那么是作为单独的一张表还是作为事实表的一部分?其实并没有完全对与错的答案,只有是否适合自己的答案。这里,城市与渠道的信息并不会发生变化,所以放入事实表中可以避免联合查询。
建立了统一的时间维度,可以支持各种时间统计方案,避免在查询时进行时间值运算。
在品牌维度、门店维度、职位维度三张表中,都有prod_xxxx_id的字段,其值是产品业务数据库中相应数据的id,作用是为了与业务数据库中的信息进行同步。当业务数据库中的相关信息发生变化时,会通过ETL来更新数据仓库中的信息,因此我们需要这样的一个字段来进行唯一标识。
建立一张temp表,表中有last_update_time与etl_name两个字段;
每次更新时,首先查询出相应的etl_name的最近一条记录,取其中的last_update_time作为起始时间,取当前时间为结束时间;
抽取数据源中在这段时间内变化的数据,作为ETL过程的输入,进行处理;
更新成功时,插入一条数据,last_update_time为当前时间。
查看任务的执行时间和进展不方便。每次需要查看某个任务的执行情况时,都要登录到服务器上去查看命令行的执行时间、log在哪里,通过ps来查看当前进程是否在运行等等。
任务跑失败后,没有通知与重试。
任务之间的依赖关系无法保证,完全靠预估,然后在crontab里设定执行时间间隔,经常出现上游还没有处理完,下游就启动了,导致脏数据的产生。
文章不错?点个【在看】吧! 以上是关于创业公司数据仓库的建设的主要内容,如果未能解决你的问题,请参考以下文章