深入解析数据仓库中的缓慢变化维
Posted 企鹅杏仁技术站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入解析数据仓库中的缓慢变化维相关的知识,希望对你有一定的参考价值。
作者 | 李谦恒
数据工程师。逻辑重于代码,高效胜过勤奋。崇尚 life work balance。
前言
最近公司在招聘数仓开发,笔者负责技术方面的一些问题,缓慢变化维自然是不可缺少的环节。
但出乎笔者预料的是,所有的面试者都没有完整了解 缓慢变化维 的前因后果及处理方式,大都是通过“野路子”碰运气实现几种简单通用的变化方式,甚至有人声称缓慢变化维就是拉链表。
因此,笔者将基于 kimball 的数仓理论和自身对其的理解,对缓慢变化维进行全面且深入的介绍。
什么是缓慢变化维?
要解释缓慢变化维,必须先解释什么是维度。
什么是维度?
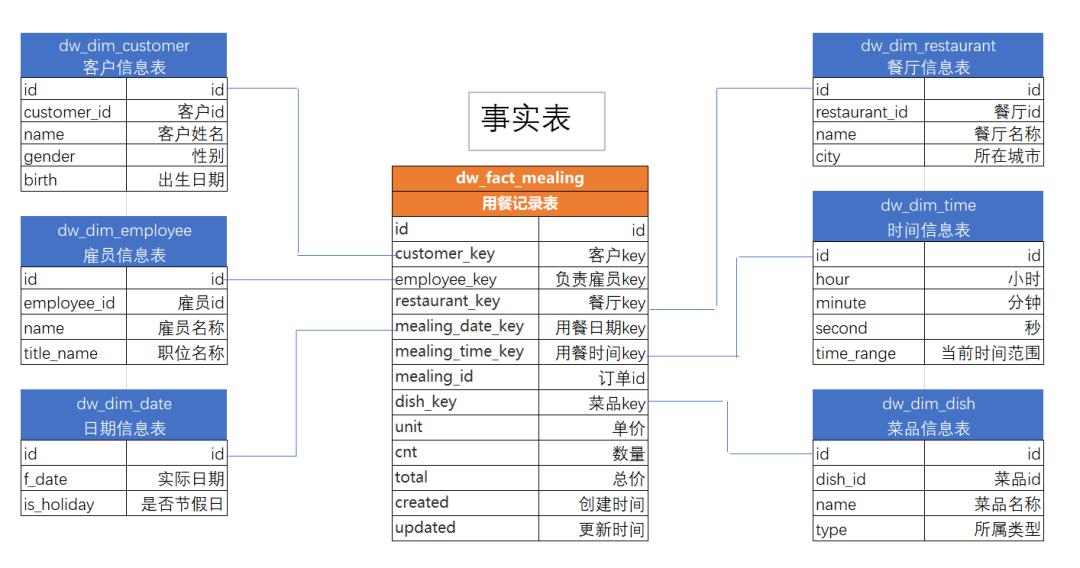
在数据仓库的 DW 层中,表根据用途往往会分为 2 个类型:FACT(事实表)和 DIM(维度表)。
举个例子,如果我们要描述一个餐饮过程:
小明 2020年4月19日下午3点20分 在 海底捞(万达广场) 吃了5道菜,每道菜的单价是4元,总价是20元。
那么这个过程在数仓中,会如此划分:
fact:餐饮过程,单价、数量、总价
dim:小明,餐饮时间,餐饮门店,菜名。
也就是说:吃了多少东西,多少钱——这些属于 fact;在哪里吃、什么时候吃?这些属于 dim。
下面是简单的 ER 图,方便大家更好的理解。
黄色为事实表,蓝色的就是维度表。
什么是缓慢变化维?
正如上述所言,我们会将分析的各种角度,存放在维度表中。但正如每个人所见,维度里的数据是可能发生变化的——尽管可能跨越极久。
举2个例子:
客户的性别变更
可能在第一次登陆中,我们得到的信息是 该客户性别为男。
但在几年的客户再一次使用中,我们又得到该客户的性别为女。
这就是维度值的一种变化可能
性别一般并不会改变,所以大概率是其中的一次数据有误。但也有可能是客户做了变性手术。
雇员的部门更替
假定有一个雇员叫小杨,他最早是负责运营的——此时他的 title 是"商品运营助理";但因为某些原因,他转组成为数据组的一员,这时 title 就变成了"数据分析专员"。
这是缓慢变化维的一种常见可能
上面提到的这些数据变化,业务系统(CRM、OA等)往往并不会保留历史数据。但在分析角度,我们是一定要保留这些改变的痕迹。这种随着时间可能会缓慢变化的维度,就是 缓慢变化维、也就是 SCD(Slowly Changing Dimensions)
常见的处理方法
kimball 整理的处理方法一共有 8 种,但往往只有 3 种被详细使用。
类型1 重写
与业务数据保持一致,直接 update 为最新的数据。
这种方法主要应用于以下两种情况:
数据必须正确——例如用户的身份证号,如需要更新则说明之前录入错误。
无需考虑历史变化的维度——例如用户的头像 url,这种数据往往并没有分析的价值。因此不做保留。

这种处理方式的优缺点:
优点:
简化 ETL ——直接 update 即可。
节省存储空间——其他存储方法都占用更多空间。
缺点:
无法保留历史痕迹——万一有天想分析呢?
类型2 增加新行
更新历史数据时间戳,新增新行记录新值。
这种方法主要用于 仅需要保存历史数据 的业务场景
具体的 ETL 则如下:
自然键即指有业务意义的唯一 ID,例如用户 ID、身份证号等。代理键则可以简单理解为该表的自增 ID 值
自然键第一次出现时。
新增一行数据,created 为业务系统的创建时间,updated 为9999-12-31
数仓的规范不允许数据存在 NULL 值的情况,因此用9999-12-31代替

类型2的维度发生变化时
将自然键当前记录的 updated 由 9999-12-31刷为最新时间
新增一行记录,记录最新的数据,created 为最新时间,updated 为 9999-12-31
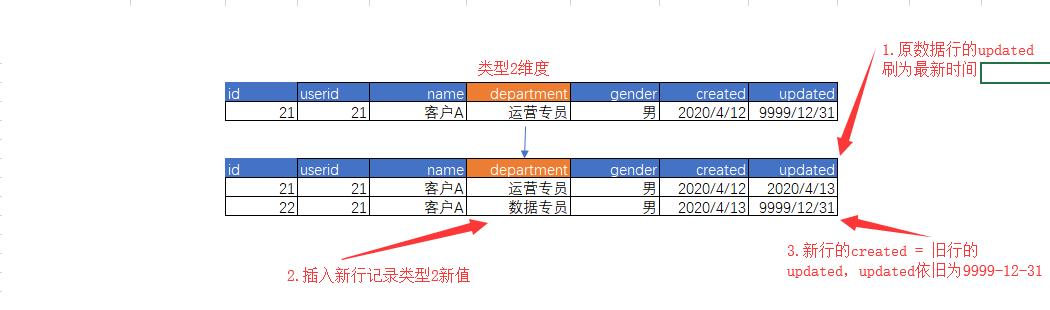
这样一来,因为事实表存储的是维度表的代理键而非自然键,因此在历史数据的查询中会以历史的维度值进行计算。同时在维度值更新后的相关数据自然使用的是新的代理键。完美的解决了大部分缓慢变化维情况。
类型3 增加当前值属性
在大部分的维度模式中,很多的源数据变化将产生类型 1 和类型 2 变化。有时两种技术都不能满足需求——当需要分析所有 伴随着新值或旧值的变化前后 记录的事实时,需要采用类型 3 变化。
很多人都难以理解类型 3 的重要性,因此笔者举一个例子——一个无法用类型 1 和类型 2 处理的例子:
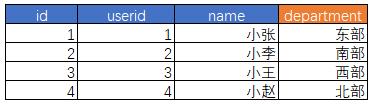
假定一家公司的销售是按照销售区域进行分组:
突然有一天,领导灵机一动,决定 精细化销售,将东部、南部、北部重新划分为东南、东北部
但由于发送的过于仓促,因此销售人员是立刻使用了新的部门划分;但同样希望保留旧的名称——至少要暂时保留,用以比较今年和去年的业绩。即:
拥有使用 新区域 分析所有事实的能力,无论变化前还是变化后
拥有使用 旧区域 分析所有事实的能力,无论变化前还是变化后
第一个需求——新区域分析——允许立即采用新的分组,所有历史订单都能分为东南、东北等新类别;
第二个需求——旧区域分析——允许公司采用旧分组,所有的订单可以根据旧值分组——就好像一切都没发生过变化。
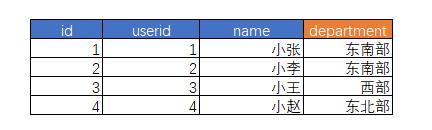
这时,就会发生一些问题:先前的技术不适合——无论是类型1还是类型2,都不能同时满足这两个需求;
类型 1 可以满足第一种需求,使用新值写旧值。但显然它无法实现第二个需求;
类型 2 则更糟,它不能满足任意一个需求——旧的事实和旧的维度相连;而新的维度值和以后的事实相连。毫无疑问,它既不能分析旧数据、也不能分析新数据。
此时引入类型 3 处理方法:新增字段同时储存新旧值。
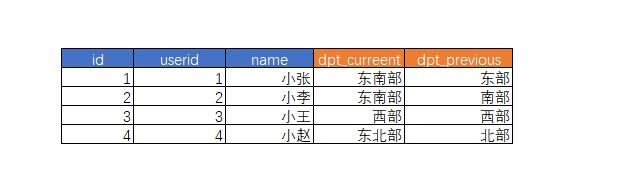
如果发生第二次变化,当前的 current 会被更新到 previous 中,新的变化值则会写入 current。
需要注意的是:类型 3 不保存事实的历史内容
需要注意的是,类型 3 的改变往往并不是一个仅此一次的过程——它能发生 1 次就有可能发生 2 次甚至更多次。类型 3 变化只保护变化属性的一个旧版本,一旦发生第二次变化,第一次变化前的值就要被废弃了。如果想要用变化 3 来实现更多的版本,那只能增加更多的列来实现(例如 dpt2018,dpt2019)——这无疑是非常愚蠢的。因此,除非特定需要,应尽量避免使用类型 3 的变化。
其他类型
剩下的 5 种类型基本都不被采用,但值得一提。
类型 0 不做调整
这里的数据定义与类型 1 类似,但不同点在于 类型 0 绝不允许 ETL 对该维度进行更新——你真要改的话就手动改表吧。
例如数仓中的代理键
类型4 微型维度
当变化频率加快时候,并且维度表包含几百万行的维度表。如果对变化的跟踪采用可靠的 SCD2 技术对浏览和查询性能具有负面影响——太多行且无必要。采用新的独立的维度表消除频繁分析或者频繁变化的属性,这一维度技术叫做微型维度。
例如 employee 的 年龄、薪资、税收金额
年龄每年一变,薪资、税收金额也经常改变
这里要注意:
这些“易变化”的值并非存储其准确的值,而是其范围值;
例如年龄,我们不会存“23",而是会存"20-30"。收入我们不会存”999“,而是”0-1000“。如果存准确值的话,数据量会过于高。从分析角度,我们往往也只需要一个模糊的范围即可。
如果需要记录准确值,可以考虑使用 无事实的事实表 单独记录。
微型维度没有自然键,只有值的笛卡尔积组合。
你不会在表中看到 user_id 这种自然键,因此类型 4 中微型维度只能在事实表中出现。
如果想把维度表和相关的微型维度连起来,那就是类型 5 了。
常见的微型维度表结构:
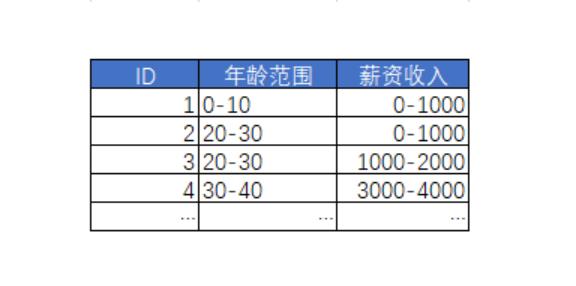
可以看到,该微型维度是由 年龄和薪资的笛卡尔积组合构成。
你可以在建立时就将所有可能组合都预计算存入——缺点是表一开始就较大,但优点是省去了 ETL 的功夫
也可以出现一个存一个,维度表的稀疏性表明了实际数据量并不会那么多。
常见的维度表、微型维度、事实表组合:查看餐饮时雇员的职位和年龄。

可以看到,微型维度表与维度表通过事实表相连,并不直接连接。
类型5 类型1+微型维度
类型5,即是将类型 4 与类型1组合起来的方法合并。该技术的特点是增加当前微型维度主键作为主维度的一个属性。该属性在主维度中以类型1进行变化更新——从而避免主维度表行的爆炸增长 
这样一来:
可以从主维度表获取到其对应的微型维度数据——虽然只有最新的。
可以从相关事实表中获取微型维度历史变更的信息。
类型 6 类型1+类型2+类型3
类型 6,即是将类型1、2、3的联合使用。
主要解决的业务场景是:
该维度列变化频次较高,但即使这样也希望历史业务能以最新的值来分析。
无法确定每次该维度的变更时间。
希望保留历史数据方便追溯
下图为例:
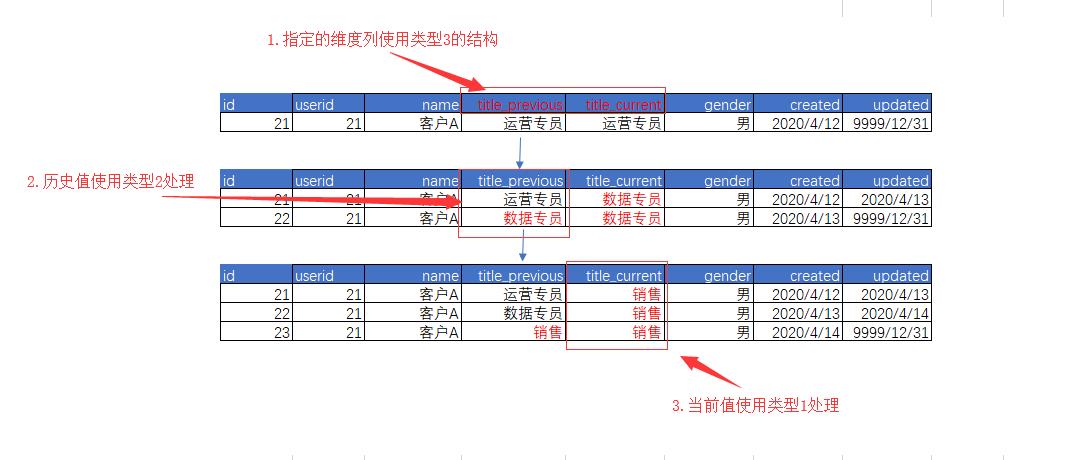
ETL步骤:
记录需要如此处理的列,分别创建 previous 和 current 两列。
新数据插入时,current = previous.
该列有新值时,
历史 previous 使用类型 2 方法处理——旧数据只处理 updated,新行存储新值。
当前 current 使用类型 1 方法处理——所有该自然键的值都刷成最新值。
类型7 双类型1+类型2
在上面的类型 6 有一个缺点——需要额外增加一个 current 列。
如果有大量的维度都需要如此处理的话就会有问题:假定该维度表有 150 列,如果我们都用类型 6 处理,则会变成 300 列——这无疑是令人无法接受的。
类型7就是 解决以上困难的。有很多种实现方法,下面会介绍2种比较常见的
双重外键——应用于类型1&类型2的维度表
事实表对于该维度表存储 2 个外键,如下图
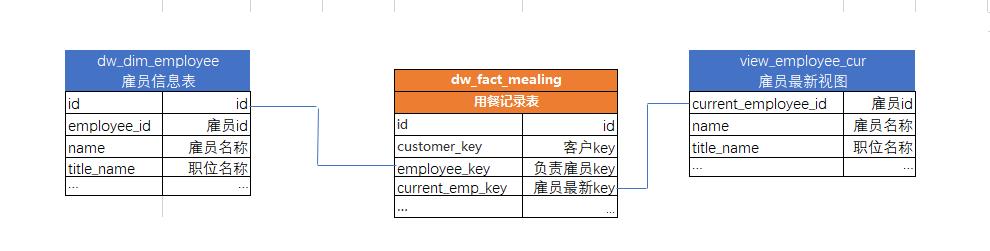
这么一来,如果想要了解雇员在用餐发生瞬间历史的状态,关联至左边的维度表即可得知;如果想要以雇员最新的状态进行分析。则直接取右边的表即可。
最新视图获取:右边表可以通过视图展示(比如只取 updated == '9999-12-31'的数据),也可以生成一个实际表来存储。
视图主键ID:对应的主键 currentemployeeid 则有多种取法,笔者建议使用超自然键,如系统无超自然键的话也可以用普通的自然键来替代。
超自然键:更为持续的自然键;一般自然键是由 OLTP 系统生成,但他们有可能发生改变——例如员工离职又入职,他的 userid 自然会变化。因此,完整的 OLAP 系统会自己生成一个和实际事务对应的自然键——即超自然键。
单外键
也可以更节省一些——事实表连外键都不需要增加。
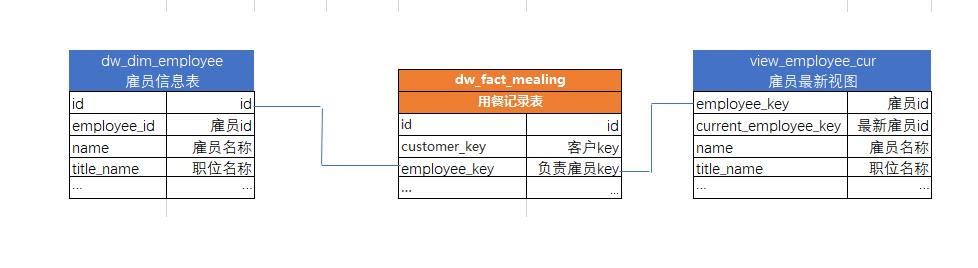
这种处理方法的主要难点在于右表——不再只需一个自然键。
下图是左表(实际维度表)的变化——标准的类型 1&类型 2
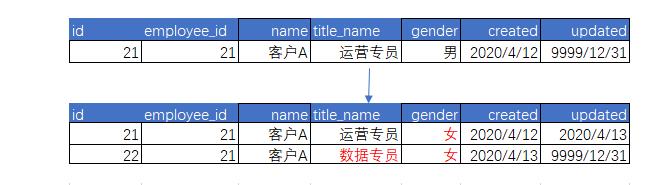
下图是右表(最新视图)的变化
可以看到,在右表的所有相关字段中,维度列无论是类型1、2 都更新成了最新的值。
双重外键的处理方法需要事实表多一个值,单重外键则需要ETL制造出一个存储最新值的维度表(逻辑较复杂,且查询会较慢)。具体采用哪种方法需要视具体业务场景
总结
全文完
以下文章您可能也会感兴趣:
我们正在招聘 Java 工程师,欢迎有兴趣的同学投递简历到 rd-hr@xingren.com 。
以上是关于深入解析数据仓库中的缓慢变化维的主要内容,如果未能解决你的问题,请参考以下文章