数据仓库设计方法
Posted 胖风烟静
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库设计方法相关的知识,希望对你有一定的参考价值。
1、数据仓库
1.1 数据仓库是什么
数据仓库,通过接收各种源系统数据,并经过ETL过程,将数据进行规范化、验证和清洗,最终装载入数据集市,为数据查询、分析提供支持。
1.2 ETL
ETL操作,全称是Extraction Transformation Loading,是指数据仓库在接收源系统数据时候进行的提取、转换(规范化和清洗)和加载的过程。
1.2.1 Extraction 数据提取
数据提取,包括初始化数据装载和刷新,其中刷新需要解决当源数据发生变化时,如何对数据仓库中相应数据进行追加和更新。
1.2 Transformation 转换
在进行数据转换前,首先要进行数据清洗,避免数据歧义、重复、不完整。数据清洗后,将数据转换成数据仓库所需要的数据,建立统一的数据字典和格式,对数据内容进行归一化。此外,数仓需要的数据有些可能是不直接存在的,需要源系统中多个数据共同确定。
1.3 Loading 加载
数据加载是将处理完成的数据导入到对应的存储空间里,以方便给数据集市提供数据。
一般大公司为了数据安全和操作方便,都是自己封装的数据平台和任务调度平台,底层封装了大数据集群比如Hadoop集群,Spark集群,Sqoop、Hive、Zookeepr、HBase等只提供Web界面,并且对于不同员工加以不同权限,然后对集群进行不同的操作和调用。
以数据仓库为例,将数据仓库分为逻辑上的几个层次。这样对于不同层次的数据操作,创建不同层次的任务,可以放到不同层次的任务流中进行执行(大公司一个集群通常每天的定时任务有几千个等待执行,甚至上万个,所以划分不同层次的任务流,不同层次的任务放到对应的任务流中进行执行,会更加方便管理和维护)。
2、数据仓库分层设计
数据仓库一般会进行分层设计,这主要是为了:
清晰的数据结构:每个数据层都有其作用域,在使用不同表和数据时方便进行定位;
减少重复开发:规范的数据分层,开发一些中间层通用数据,可以减少重复计算提高利用率
复杂问题简单化:将一个复杂的数据问题分步骤处理,每一层只解决单一的问题,比较简单和易于理解,更便于进行数据维护,不用修复所有数据,而只是修复有问题的步骤和数据;
l数据血缘追踪:如果进行了数据分层与数据共用,那么当一个源表出现问题后,我们可以快速定位问题并确定影响范围。
常见的数据分层一般分为三大层,四小层,根据公司业务的不同可能会有差异。
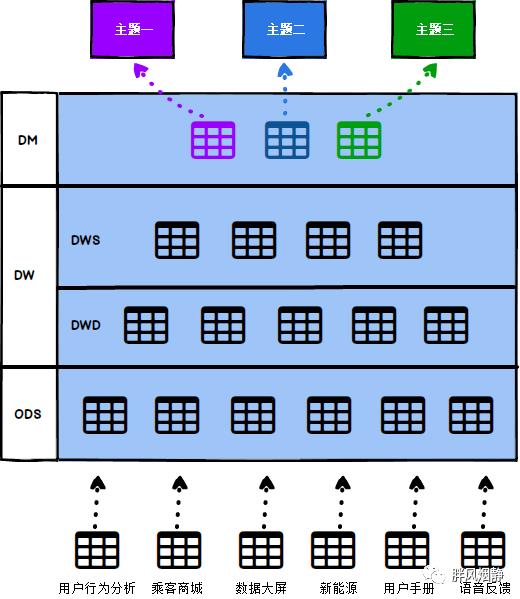
2.1 ODS层
数据准备层,是将源系统数据采集、导入到数据仓库中进行数据准备,该层的数据表结构通常与源系统的数据完全一致。
2.2 DW层
2.2.1 DWD层
Data Warehouse Detail,数据明细层。在数据明细层,数据要完成清洗、转换、加载的步骤,脏数据,格式规范不一致的数据,命名规范不一致的数据,应当被清洗、整合和规范化,形成覆盖全系统、完整、干净,具有一致性、高质量可信的数据层。
2.2.2 DWS层
Data Warehouse Service,数据服务层,也叫“轻度汇总层”,基于DWD上的基础数据,整合汇总成分析某一主题域的服务数据,一般为宽表。
2.3 DM层
Data Market,数据集市层,面向特定主题,是针对某一业务领域建立的模型。在DM层完成报表和指标的统计,DM层已经不包括明细数据,是粗粒度的数据汇总。
2.4 公共维度层和临时表
2.4.1 DIM 公共维度层
这一层是指一些公共的数据,比如国家代码和国家名、地理位置、中文名、国旗图片等信息就存在DIM层中。
2.4.2 TMP 临时表
每一层的计算都会有很多临时表,专设一个DW TMP层来存储我们数据仓库的临时表。
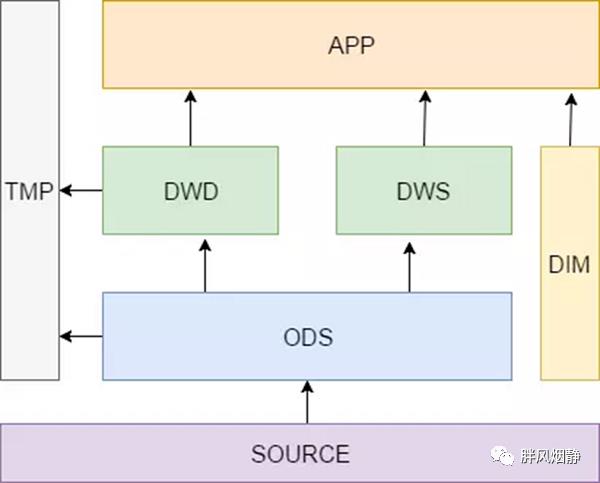
3、数据仓库规范
3.1 数据仓库命名规范
为了让数据所有相关方对于表包含的信息有一个共同的认知。比如说属于哪一层(ODS、DW明细、DW汇总、DM)?哪个业务/部门?哪个维度(用户、车机设备)?哪个时间跨度(天、月、年、实时)?增量还是全量?
命名格式:层次_业务/部门_修饰/描述_范围/周期
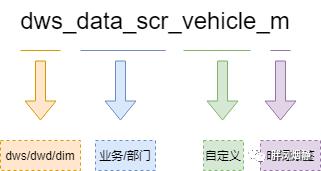
数仓层次 |
|
公用维度 |
dim |
DM层 |
dm |
ODS层 |
ods |
DWD层 |
dwd |
DWS层 |
dws |
4、数据库表建模方法
4.1 为什么需要对数据建模
数据库的四大操作:增,删,改,查中,除了查,其他三个都可归为更新操作。ER建模和关系建模的目的,就是为了避免因大量冗余数据导致的数据库更新异常。
4.1.1 更新异常
更新异常包括插入异常、删除异常和修改异常。

插入异常:当我们需要插入一条数据的时候,还被迫必须要插入另一条数据,例如,我们新建一个活动模式叫“太太团”,这时候必须要在上图的数据中插入一条实际的“太太团”活动,才可以获得新增的“太太团”ModelName。
删除异常:当我们要删除一条数据时,还需要删除另一条实际数据,例如,如果我们要在上图中删除“家庭团”这种模式,那么就需要删除掉使用“家庭团”模式的两条实际活动数据。
修改异常:当我们修改一个数据的时候,还需要重复修改多条数据。例如,如果我们想要将“散客团”改为“尊享团”,那么我们就必须在数据中将所有ModelName为“散客团”的活动改为“尊享团”才可以。
以上这些问题,都可以通过规范化的设计来避免。
4.1.2 函数依赖
函数依赖是指关系中属性间(即表中列)的对应关系。
在关系R中,Y由X唯一确定(对于任意一个X,只有唯一的一个Y与X对应),则称Y函数依赖于X,函数依赖存在多种依赖方式,以下几种与数据库表的范式建模有关。
完全函数依赖:库表中一列Y中的数值,完全由属性集合X(即联合主键)唯一确定,且属性集合X中的任何一列或者子集都无法单独决定Y的数值,则称为完全函数依赖;
部分函数依赖:不同于完全函数依赖,如果库表中的一列数值,可以由主键集合以及主键集合的子集确定,则称为部分函数依赖;
传递函数依赖:A决定B且B不决定A,B决定C,从而A决定C,则称C传递依赖于A。
4.1.3 规范化设计
范式分为第一范式、第二范式、第三范式、BC范式,以及第四、第五范式,但是第五、第六范式基本上不会用到,一般符合第三范式的库表设计,即为规范化的库表设计,可以避免上面提到的更新异常情况。
1)关系数据库表基础概念
实体:现实世界中客观存在并可以被区别的事物。比如“一个学生”、“一本书”、“一门课”等等。值得强调的是这里所说的“事物”不仅仅是看得见摸得着的“东西”,它也可以是虚拟的,比如“老师与学校的关系”。
属性:实体所具有的某一特性。在关系数据库中,属性又是个物理概念,属性可以看作是“表的一列”。
元组:表中的一行就是一个元组。
分量:元组的某个属性值。在一个关系数据库中,它是一个操作原子,即关系数据库在做任何操作的时候,属性是“不可分的”。否则就不是关系数据库了。
码:表中可以唯一确定一个元组的某个属性或属性组,如果这样的码有不止一个,那么大家都叫候选码,我们从候选码中挑一个出来做老大,它就叫主码。
全码:如果一个码包含了所有的属性,这个码就是全码。如,关系模式R(T,C,S),属性T表示教师,属性C表示课程,属性S表示学生。假如设一个教师可以讲授多门课程,某门课程可以有多个教师讲授,学生可以听不同教师讲授的不同课程,那么,要区分关系中的每一个元组,这个关系模式R的码(主键)应为全属性T、C和S,即All-key
主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
外码:一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
2)范式
第一范式(1NF):属性不可分;
第二范式(2NF):符合1NF,并且是完全函数依赖;即库表中的每一列,都是被联合主键决定;
第三范式(3NF):符合2NF,且不存在传递函数依赖;也就是说,每一列都是唯一被联合主键决定,任何一列都与其他单列的取值无关;
BC范式(BCNF):符合3NF,并且主属性不依赖于主属性;若一个关系达到了第三范式,并且它只有一个候选码,或者它的每个候选码都是单属性,则该关系自然达到BC范式。
通过ER图与关系建模设计出的库表,基本符合第三范式,所以我们需要通过ER图与关系建模来进行数据库表的设计。
4.2 关系建模
数据库中存储的都是现实中的事物,而现实中的事物以各种关系互相关联,关系模型即是通过模仿现实中的事物关系,构建数据关系模型,进行数据的存储和使用。
关系建模分为三个步骤,ER建模、关系建模(逻辑建模)和物理建模。
4.2.1 ER建模
ER建模,是关系建模的需求分析阶段,他通过ER图,对需要建模的业务领域进行需求可视化绘制。
1)基本概念
1.1)实体 Entity
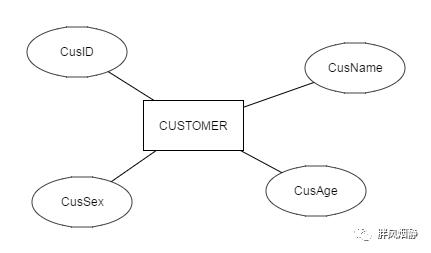
实体:标示客观世界的各种主体,如人、订单、商品等;在ER图中,实体通常用矩形表示;
1.2)属性 Attribute
属性:每个实体都有属性,例如人有性别、年龄、国籍;订单有下单时间、订单商品、订单价格、订单状态等等。用椭圆表示并用来描述实体各个特征;
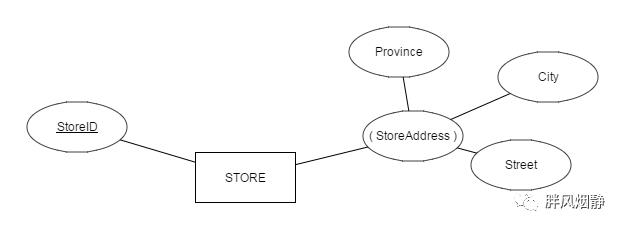
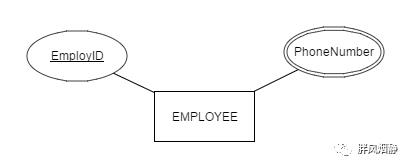
派生属性:部分属性可从其他属性或者其他数据(如当前日期)派生出来,这类属性在ER图上用虚线椭圆标识。
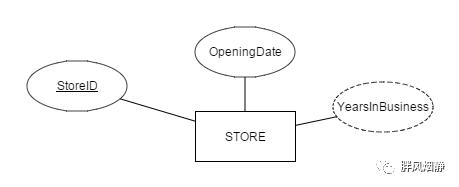
上图中士多店的YearsInBusiness属性表示店铺开张了多少年,这个属性可以结合当前日期与OpeningDate属性算到,因此用虚线椭圆标识。
可选属性:部分属性可能有也可能没有取值,比如说职工奖金。ER图上这类属性通过在属性名后面添加(0)标识。
1.3)联系 Relation
联系:实体与实体之间的关联关系,在ER图中用菱形表示。比如某职员向某主管汇报。
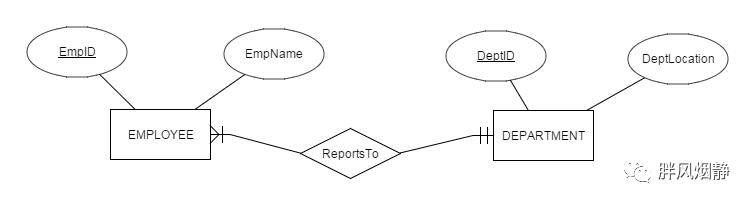
实体间连线的两端,写有一些符号。这些符号被称为基数约束(cardinality constraint),用来表示实体可以有多少实例与另一实体的实例存在联系。
基数约束共有四种形态:
形态一,强制多个对应,表示一个实体A对应多个实体B。
形态二,可选多个对应,表示一个实体A对应0个或多个实体B。
形态三,强制单个对应,表示一个实体A对应一个实体B。
形态四,可选单个对应,表示一个实体A对应0个或1个实体B。
此外,ER图中还有很多概念,用来描述各种复杂关系,这里不一一赘述了。
4.2.2 关系建模(逻辑建模)
通过ER图进行了需求可视化之后,便可根据这个ER图设计相应的关系表了。
从ER图到具体关系表的建立还需要经过两个步骤:逻辑模型设计(即关系建模)和物理模型设计。其中前者将ER图映射为逻辑意义上的关系表,后者则映射为物理意义上的关系表。
逻辑意义上的关系表是单纯意义上的关系表,它不涉及到表中字段数据类型,索引信息,触发器等等细节信息。
这里举一个简单的例子,说明逻辑建模。
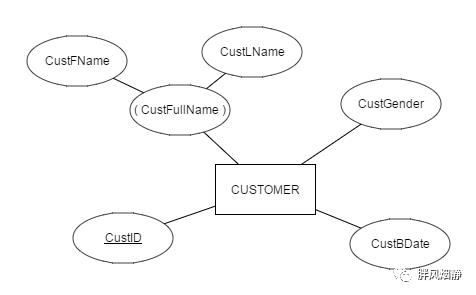
映射为关系:
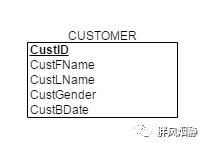
这类映射中,复合属性的各子属性会映射到的新的关系中,但是复合属性名本身不会。
虽然关系中没有出现符合属性名了,但数据库上层的前端应用可能会利用到复合属性名。也就是ER图在各个阶段都有可能用到,不是说映射为关系后就没啥事了。
4.3 维度建模
当我们要进行关系建模时,我们需要通过ER图,理清各个实体、联系等等之间的关系,自上而下的对整体的关系进行建模,这种方式需要对整体业务有较强的把握,费时费力。而维度建模方法,是针对某个主题、领域的细节进行建模的方式,他不需要对整体有较强的理解,就可以快速的构建出符合当前业务领域的库表。
在维度建模中,数据库表分为维度表和事实表。其中,维度是描述事实的角度,例如一笔交易发生的时间、地点、商品,一种商品的供应商、类别等;事实是对事实要度量的指标,如交易额、销售额、客户数等;常见的星型模型、雪花模型、星座模型就是通过维度建模法建立的。
4.4 规范化的数据仓库建模方式
规范化的数据仓库建模,应当先对ETL得到的数据通过关系建模建立一个规范化的数据仓库,而后面向各个主体领域,通过维度建模,建立各领域各部门需要的数据集市。
以上是关于数据仓库设计方法的主要内容,如果未能解决你的问题,请参考以下文章