什么是数据仓库,以及我为什么需要它?
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是数据仓库,以及我为什么需要它?相关的知识,希望对你有一定的参考价值。
数据仓库是一种分析数据库,用于存储和处理数据,以便对数据进行分析。数据仓库的两个主要功能:存储分析数据和处理分析数据。
首先,如果多个业务数据位于不同的数据源,就无法轻易地将它们组合在一起。
其次,你的数据源系统不适合用来运行大量的数据分析,这样做可能会危及业务运行,因为它会给系统带来很重的负载。
数据仓库是分析管道的核心,它有三个主要作用:
存储:在合并 (提取和加载) 步骤,数据仓库将接收和存储来自多个数据源的数据。
处理:在处理 (转换和建模) 步骤,数据仓库将处理大部分 (或全部) 由转换步骤生成的密集处理工作负载。
访问:在生成报告 (可视化和交付) 步骤,首先需要在数据仓库中收集报告,然后将其可视化并交付给最终用户。
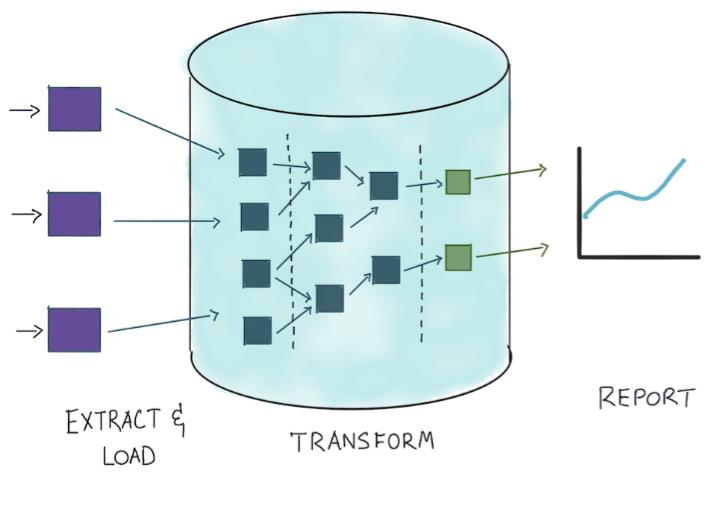
目前,大多数数据仓库使用 SQL 作为主要的查询语言。
简单地说,这取决于公司所处的阶段、所拥有的数据量和预算,等等。
在早期阶段,你可能不需要数据仓库,而是直接使用业务智能 (BI) 工具连接到生产数据库。
如果你仍然不确定数据仓库是否适合你的公司,请考虑以下几点:
首先,你是否需要分析来自不同数据源的数据?
在公司发展的某个阶段,你可能需要将来自不同数据源的数据组合起来,以便做出更好、更明智的业务决策。
例如,如果你是一家餐馆,想要分析订单 / 服务员效率比率 (每周里哪个小时员工最忙和最空闲),就需要将销售数据 (来自 POS 系统) 与员工职责数据 (来自 HR 系统) 结合起来。
对于这些分析,如果数据都位于一个中心位置,就会容易得多。
第二,是否需要将分析数据与事务数据分离?
如前所述,你的事务系统不适合用来进行数据分析。因此,如果你在应用程序中收集了活动日志或其他可能有用的信息,那么将这些数据存储到应用程序的数据库中,并让分析师直接在生产数据库上进行数据分析可能不是一个好主意。
相反,购买一个为复杂查询而设计的数据仓库,并将分析数据保存到数据仓库里,这样会更好。这样,应用程序的性能就不会受到数据分析任务的影响。
第三,原始数据源适合用来查询吗?
例如,绝大多数 BI 工具不能很好地与 NoSQL 数据存储 (如 MongoDB) 搭在一起使用。也就是说,在后端使用 MongoDB 的应用程序需要将数据传输到数据仓库,数据分析人员才能够有效地使用它们。
第四,是否希望提高数据分析的查询性能?
如果事务数据有数十万行,那么创建汇总表可能是一个好主意,它会将数据聚合成容易查询的表单。如果不这样做,查询会非常慢,而且会给数据库带来不必要的负担。

如果你对上述任意一个问题的回答是“是”,那么你很可能需要一个数据仓库。
也就是说,在我们看来,构建一个数据仓库通常是个好主意,因为在云计算时代,数据仓库并不贵。
以下是一些常见的数据仓库,你可以从中选择:
亚马 Redshift
谷歌 BigQuery
Snowflake
ClickHouse(自托管)
Presto(自托管)
如果你才刚开始,还没有确定的想法,那么建议你使用谷歌 BigQuery,原因如下:
BigQuery 前 10GB 存储和前 1TB 查询量是免费的,之后按使用量付费。
BigQuery 是全托管的 (无服务器),不需要启动或管理物理 (或虚拟) 服务器。
BigQuery 的架构是可自动伸缩的:根据查询的复杂性和数据量,BigQuery 将自动确定分配给每个查询多少计算资源,无需手动调整。
但是,如果你的数据量增长速度很快,或者如果你的场景很复杂或者很特殊,就需要仔细评估你的选项。
下面,我们列出了最为流行的一些数据仓库,目的是让你对数据仓库领域最常见的选项有一个高层次的了解。这个清单并不是最完整的,也不足以帮你做出一个最完美的决定。
但我们认为,这是一个良好的开端:
| 名称 | 开发商 | 价格 |
|---|---|---|
| 亚马逊 Redshift | 亚马逊,作为 AWS 产品的一部分 | 按实例付费,每小时 0.25 美元起(一个月大约 180 美元) |
| 谷歌 BigQuery | 谷歌,作为 Google Cloud 产品的一部分 | 按数据查询和数据存储付费,前 10GB 存储和前 1TB 查询量免费 |
| ClickHouse | 由 Yandex 开发,后来开源出来 | 开源免费,可以部署在自己的服务器上 |
| Snowflake | Snowflake 公司 | 按使用量付费 |
| Presto | 由 Facebook 开发,后来开源出来,现在由 Presto 基金(Linux 基金的一部分)负责管理 | 开源免费,可以部署在自己的服务器上 |
这个时候,有些人可能会问:
“数据仓库不是像关系数据库一样,存储数据,然后对数据进行分析吗?难道我就不能使用 mysql、PostgreSQL、MSSQL 或 Oracle 作为数据仓库吗?”
简单地说:可以。
但要细说起来:这个要视情况而定。首先,我们需要了解一些概念。
理解这两种数据库工作负载 (事务工作负载和分析工作负载) 之间的差异是非常重要的。
事务工作负载是指普通业务应用程序的查询工作负载。当访问者在 Web 应用程序中加载一个产品页面时,将向数据库发送一个查询,获取产品信息,并将结果返回给应用程序。
SELECT * FROM products WHERE id = 123
以下是事务工作负载的几个常见属性:
每次查询通常返回一条记录或少量记录 (例如,获取某类别的前 10 篇博文)。
事务工作负载通常包含运行时间非常短 (少于 1 秒) 的简单查询。
在任意时刻都有大量的并发查询,这取决于应用程序的并发访问者数量。对于大型网站来说,这个数字可能是成千上万或数十万。
通常对全数据记录感兴趣 (例如产品表中的每一列)。
分析工作负载是指用于实现分析目的的工作负载。在生成一个数据报告时,一个查询将被发送给数据库,计算结果,然后将结果显示给最终用户。
SELECT category_name, count(*) as num_products FROM products GROUP BY 1
分析工作负载具有以下属性:
每个查询通常会扫描表中的大量数据行。
每个查询都是重量级的,并且需要很长时间 (几分钟,甚至几小时) 才能完成。
并发查询并不多,主要由使用分析系统的报告或内部人员数量决定。
通常只对几列数据感兴趣。
下面是事务工作负载(或数据库)与分析工作负载(或数据库)的比较。
事务工作负载有很多简单的查询,而分析工作负载有一些重量级的查询。
由于上述两种工作负载之间的巨大差异,这两种工作负载的数据库底层后端设计也是非常不一样的。事务数据库的优化目标是高并发的快速短查询,而分析数据库的优化目标是长时间运行的资源密集型查询。
那么它们之间的架构区别是什么呢?这需要专门的文章才能解释清楚,不过简单地说,分析数据库使用以下技术来保证性能:
列式存储引擎:分析数据库不是在磁盘上逐行存储数据,而是将数据的列分组存储。
列式数据的压缩:压缩每个列中的数据,获得更小的存储和更快的检索速度。
查询执行的并行化:现代分析数据库通常运行在数千台机器上。因此,可以将每个分析查询拆分为多个更小的查询,并在这些机器之间并行执行 (分治策略)。
你可能已经猜到了,MySQL、PostgreSQL、MSSQL 和 Oracle 数据库主要用于处理事务工作负载,而数据仓库用于处理分析工作负载。
就像我们之前说的,可以,但要视情况而定。
如果刚开始时只有少量的数据和分析用例,选择一个普通的 SQL 数据库作为数据仓库是可以的 (最流行的是 MySQL、PostgreSQL、MSSQL 或 Oracle)。如果有很多数据,仍然可以这样做,但需要进行适当的调优和配置。
也就是说,随着像 BigQuery、Redshift 这样低成本数据仓库的出现,我们建议使用数据仓库。
不过,如果你必须要选择一个普通的基于 SQL 的数据库 (例如,你的公司只允许数据驻留在自己的网络中),我们建议使用 PostgreSQL,因为它提供的分析功能最多。
在这篇文章里,我们主要谈到了:
数据仓库是存储和处理数据的集中式分析数据库。
构建数据仓库的四个出发点。
一个简单的数据仓库技术列表。
数据仓库为分析工作负载而优化,而传统数据库为事务工作负载而优化。
原文链接:
https://towardsdatascience.com/what-is-a-data-warehouse-when-and-why-to-consider-one-2e826be68e95
你也「在看」吗? 以上是关于什么是数据仓库,以及我为什么需要它?的主要内容,如果未能解决你的问题,请参考以下文章