UOS 4.0 - RabbitMQ 参数调优分析
Posted 同方有云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了UOS 4.0 - RabbitMQ 参数调优分析相关的知识,希望对你有一定的参考价值。
简介
RabbitMQ是一个支持多种通信协议的通信中间件,RabbitMQ实现了非常灵活的消息传输机制,使用RabbitMQ可以大大的简化分布式系统消息传递的问题,使得整个分布式系统的架构更加灵活、简单、可靠。RabbitMQ是openstack集群中使用最广泛的消息中间件,在openstack集群中发挥着非常重要的作用。RabbitMQ服务的可用性和稳定性直接的影响到openstack各种服务的可用性和稳定性。因此,确保RabbitMQ的高可用对于UOS有着非常重大的意义。

测试架构
测试环境是按照集群的高可用架构部署的,架构如下图所示:
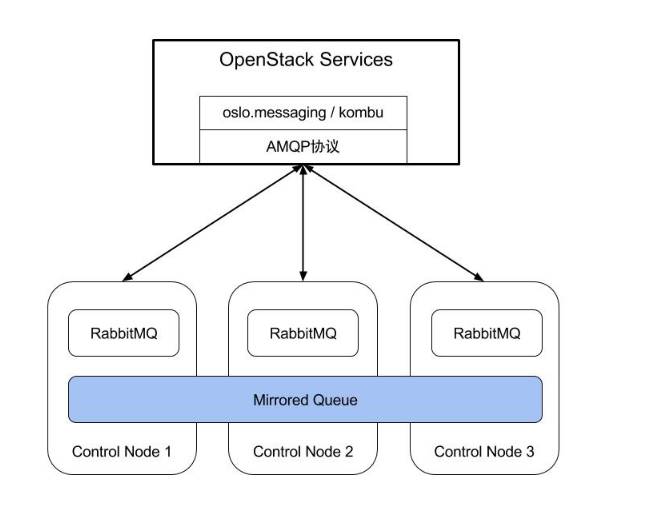
如上图所示,RabbitMQ集群由三个RabbitMQ节点组成。OpenStack的各个组件使用oslo.messaging模块,借助RabbitMQ相互通信,配置文件中的相应配置项为:

RabbitMQ集群通过策略决定队列的mirror行为,保证队列和队列中消息的高可用。RabbitMQ的队列mirror配置策略如下:

RabbitMQ集群的配置方法可以参考RabbitMQ集群配置文档。
测试方案
3.1 测试样本
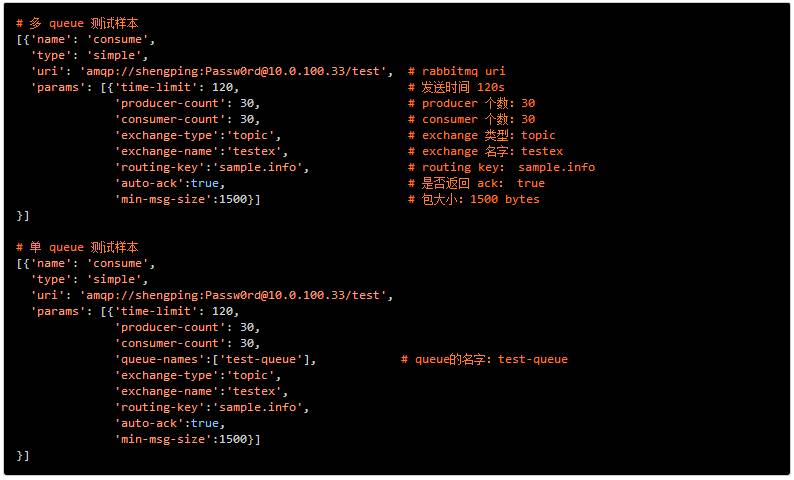
3.2测试分类
单个 queue 发送消息:
配置hipe_compile / 不配置 hipe_compile
num_tcp_acceptors 数量 10 , 20, 40
delegate_count 数量 64, 128
多 queue 发送消息:
配置 hipe_compile / 不配置 hipe_compile
num_tcp_acceptors 数量 10 , 20, 40
delegate_count 数量 64, 128
CPU 与 MEM 资源消耗对比
30 个 publishers,30 个consumers,从一个queue 上获取消息
普通单 queue:
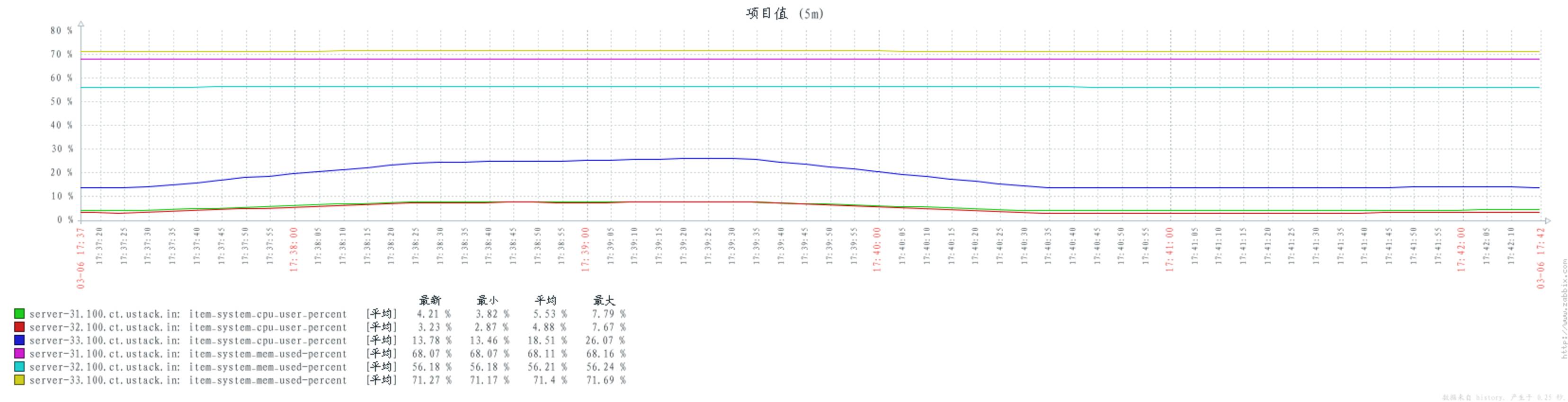
配置 hipe_compile:
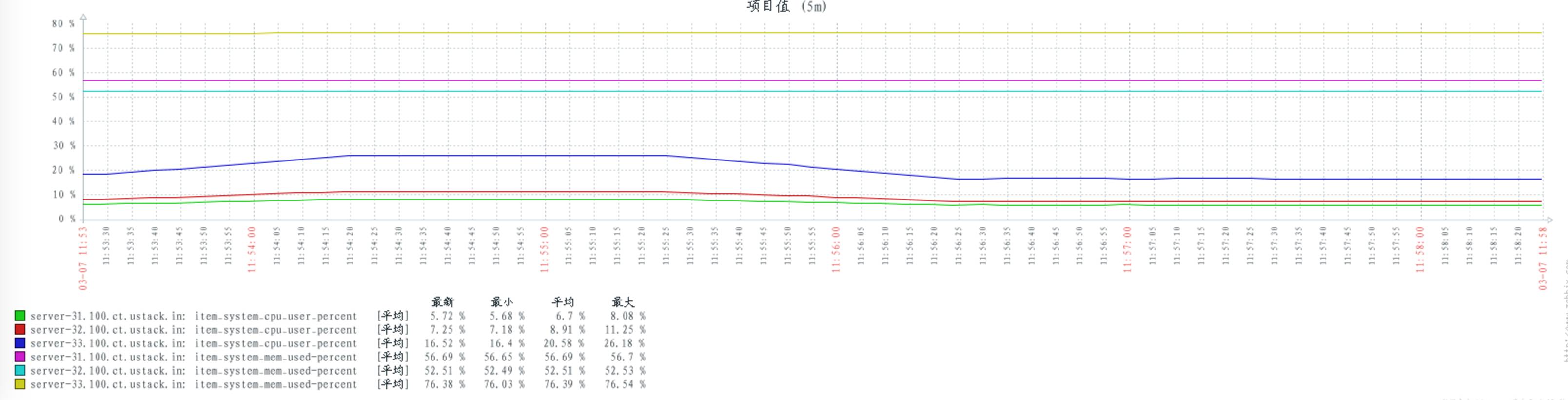
配置 num_tcp_acceptors 数量 10:
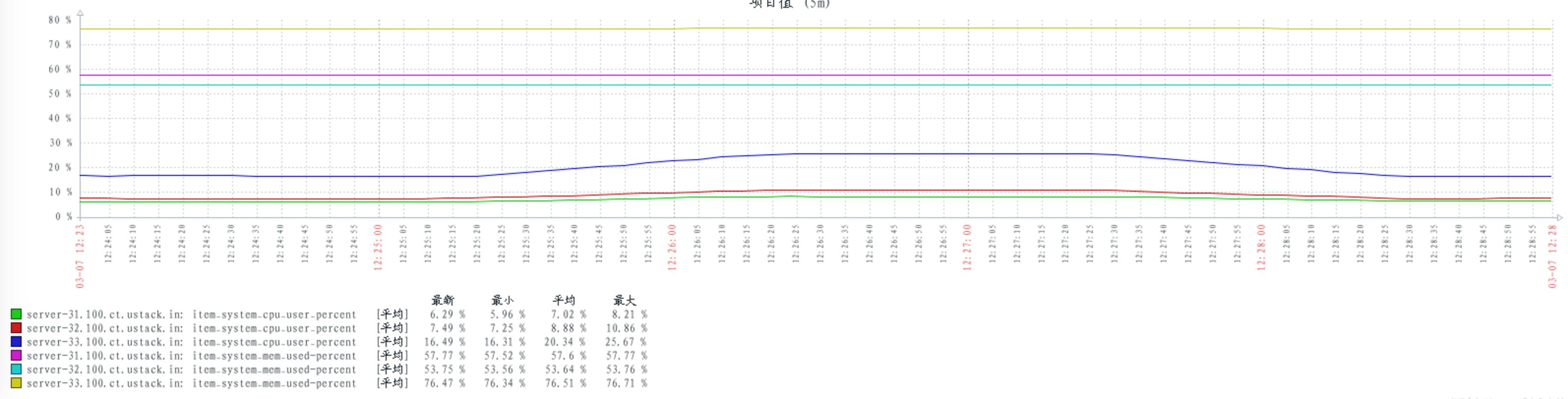
配置 num_tcp_acceptors 数量 20:
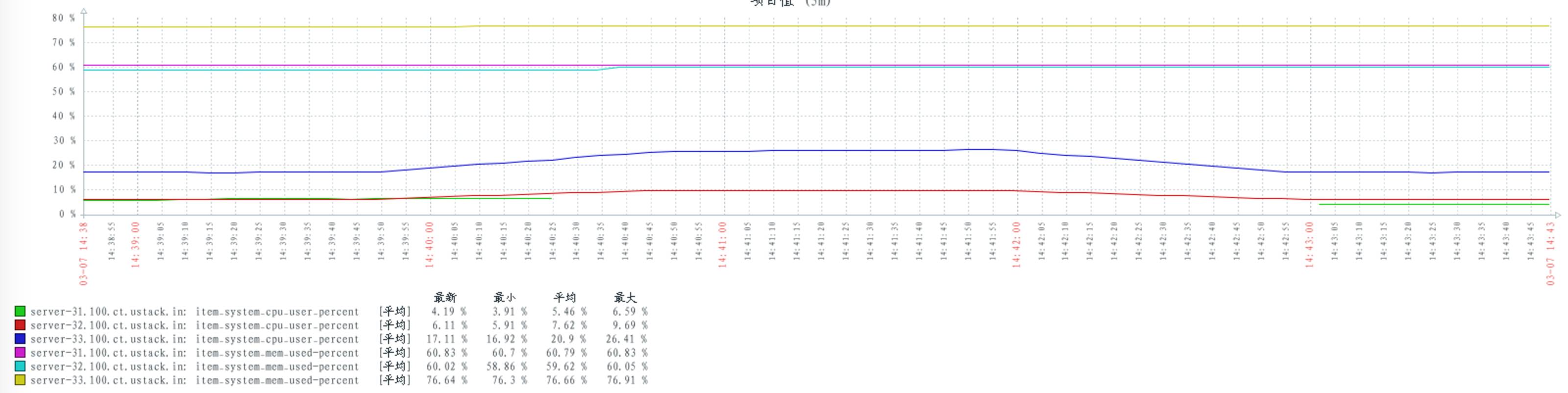
配置 num_tcp_acceptors 数量 40:
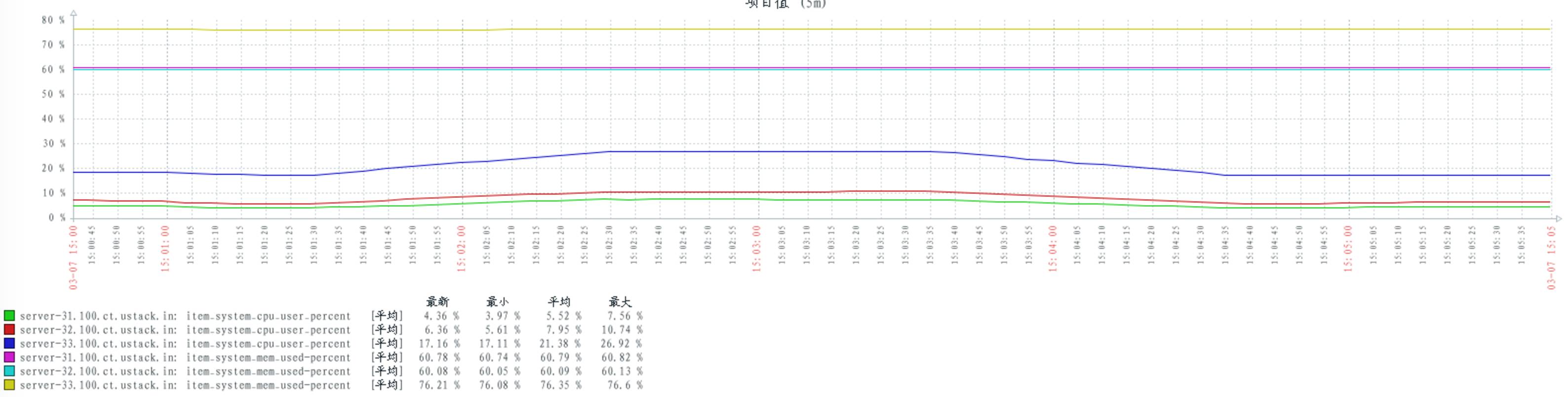
配置 delegate_count 数量 64:
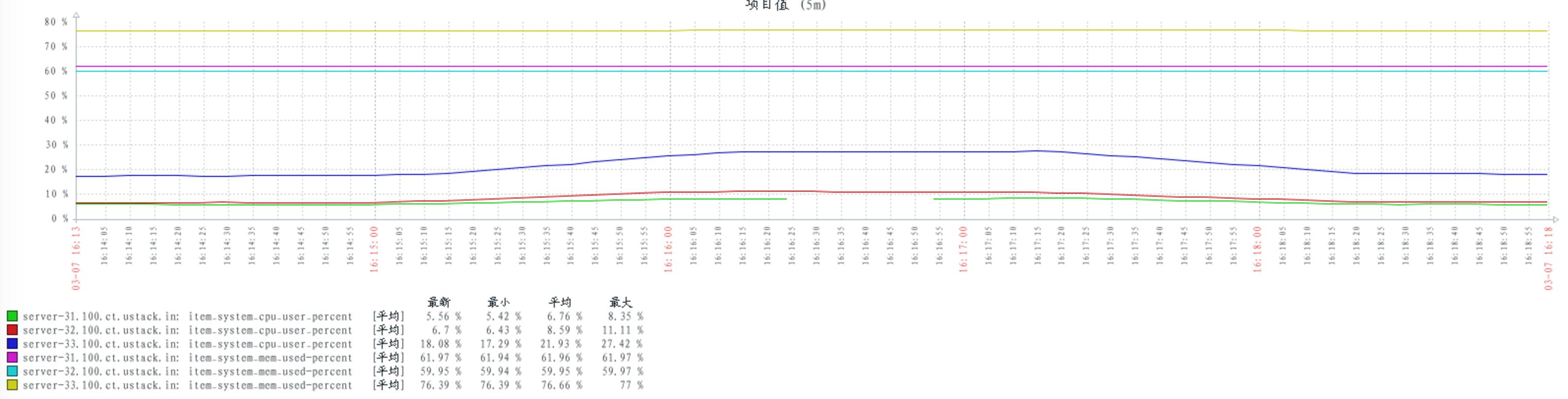
配置 delegate_count 数量 128:
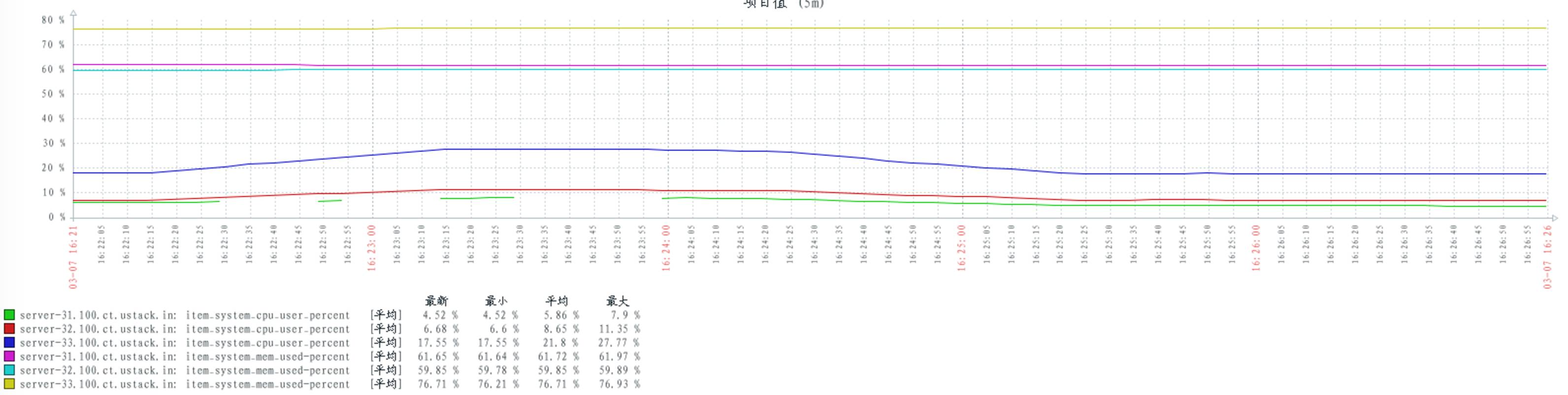
30 个 publishers,30 个consumers,分别从 30 个 queue 上获取消息 :
普通多 queues
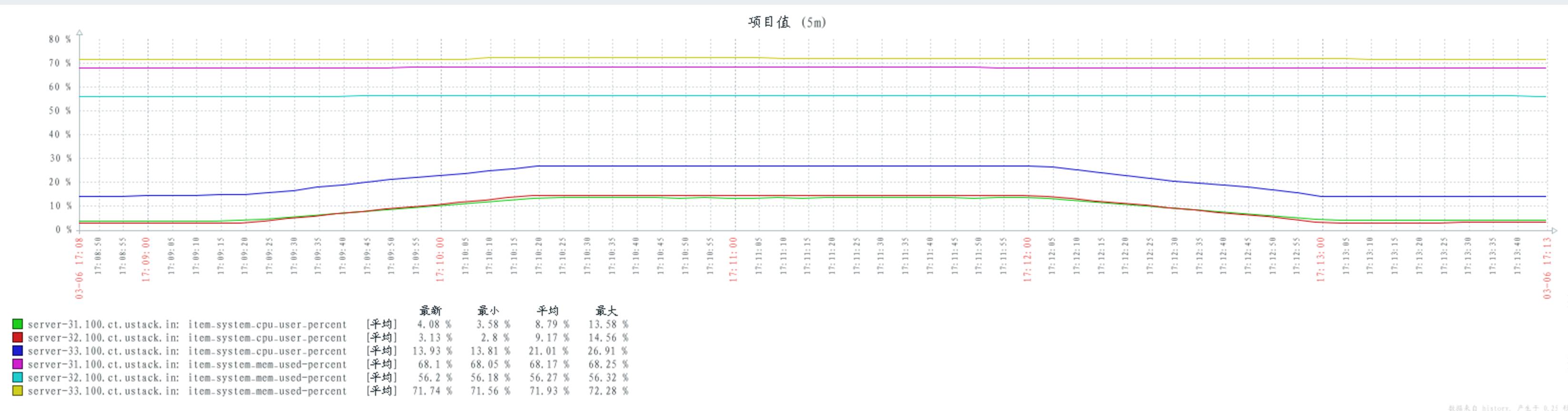
配置 hipe_compile
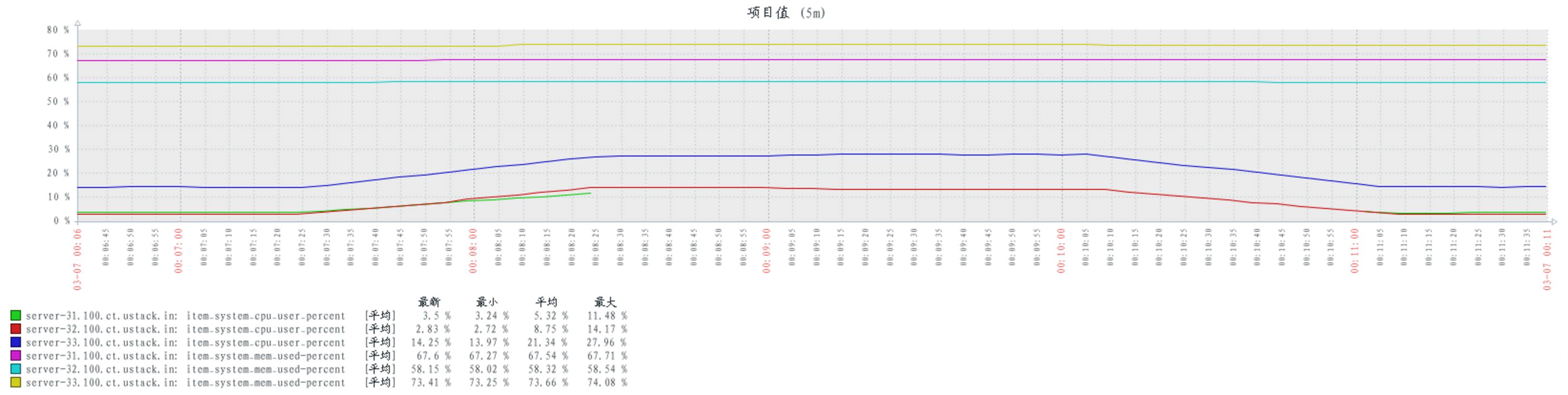
配置 num_tcp_acceptors 数量 10
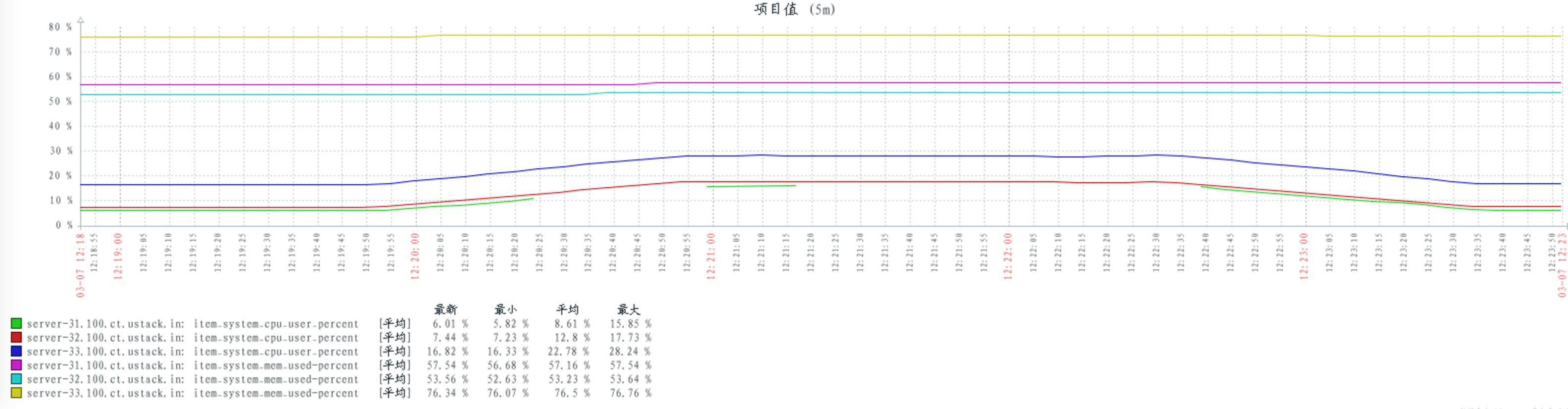
配置 num_tcp_acceptors 数量 20
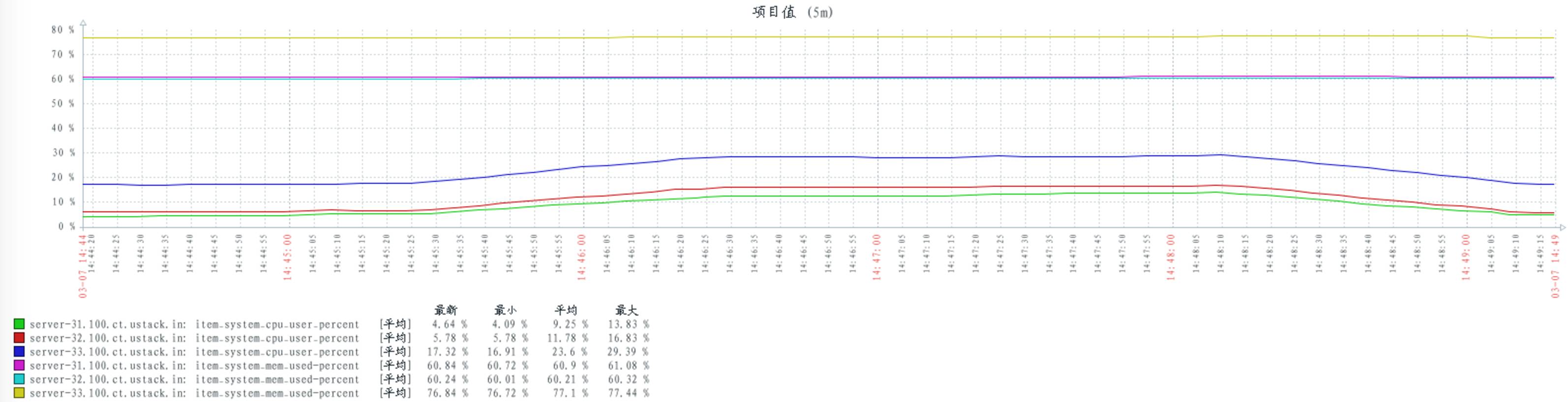
配置 num_tcp_acceptors 数量 40
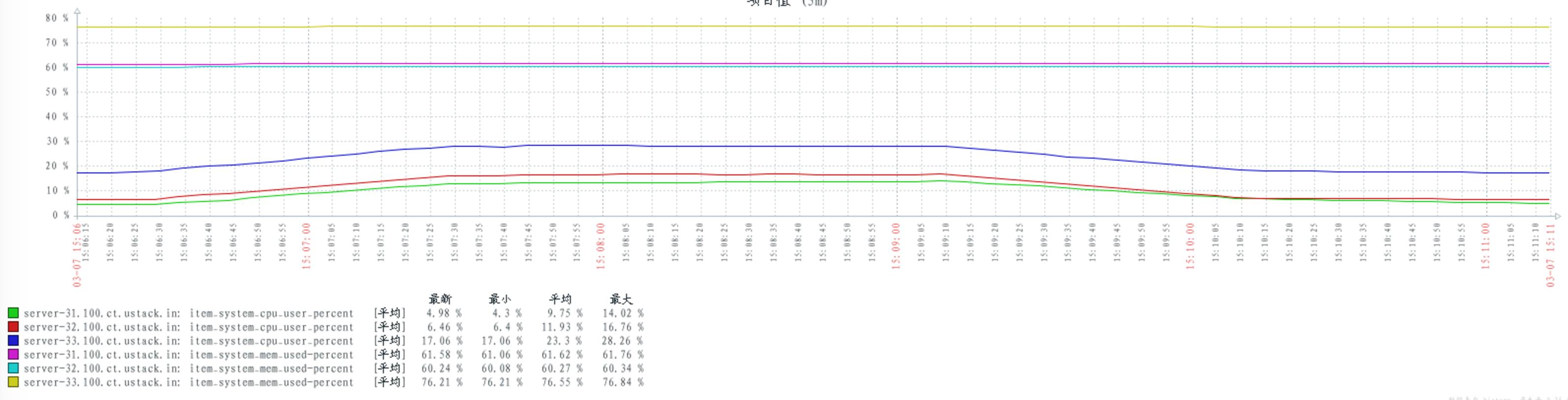
配置 delegate_count 数量 64
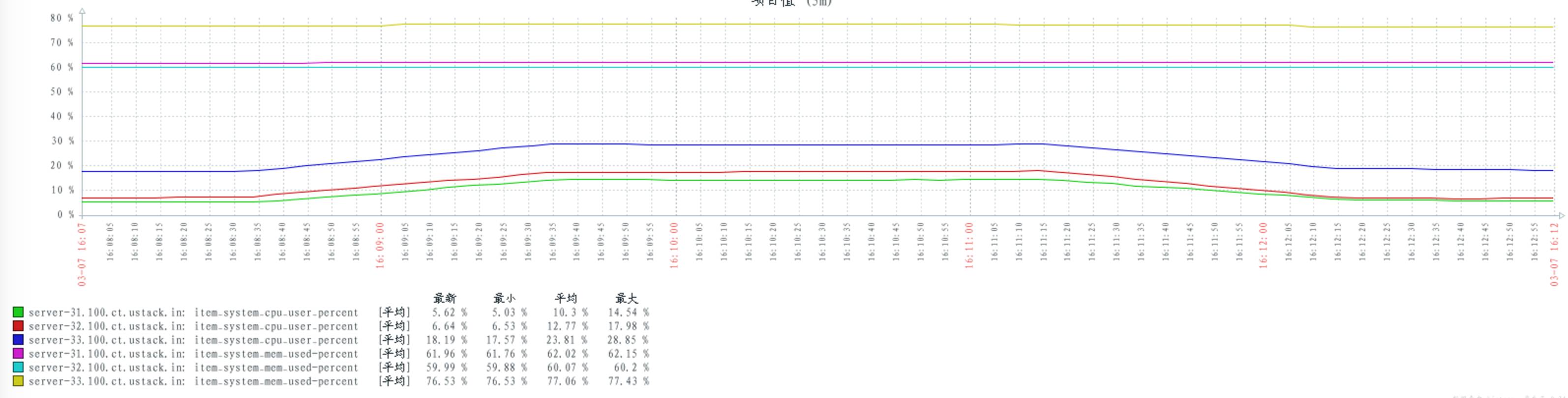
配置 delegate_count 数量 128
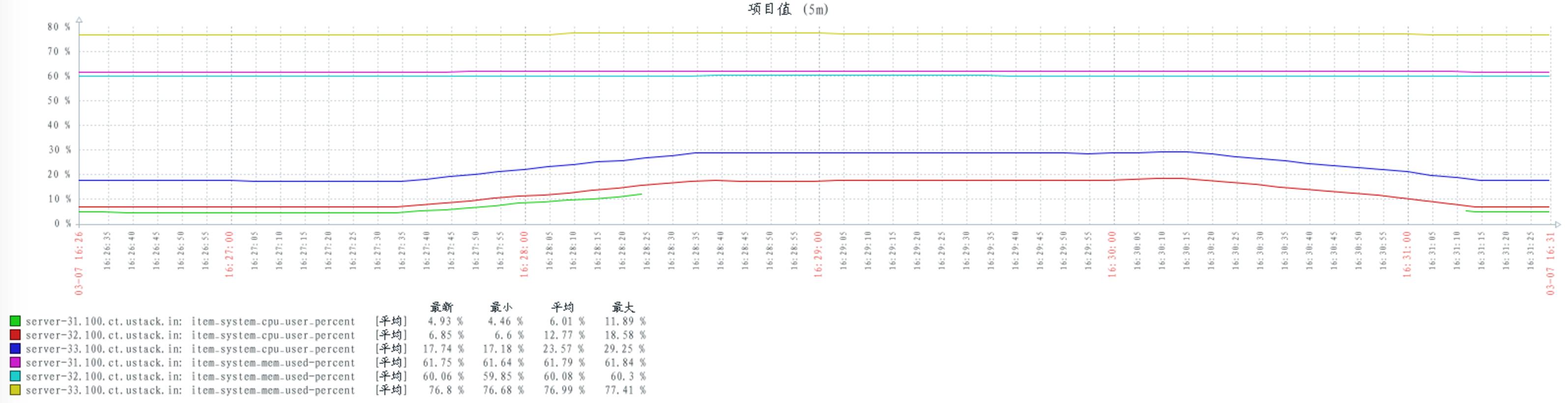
测试结论:

对比以上这些情况,可以看出:
当 consumers 和 publishers 数量不变时,不同的 rabbitmq 配置对 cpu 的消耗基本保持不变。
通过以往的其他测试,发现当 consumers 和 publishers 数量上升时,cpu 的消耗会随之上升。
当 consumers 和 publishers 数量上升(或者下降)时,并不影响 rabbitmq 对内存的消耗。可见 rabbitmq 在启动时,可能已经占有一定内存。
发送接收速率对比
30 个 publishers,30 个consumers,从一个queue 上获取消息(持续 120 s 发送1.5K 包) :
普通:
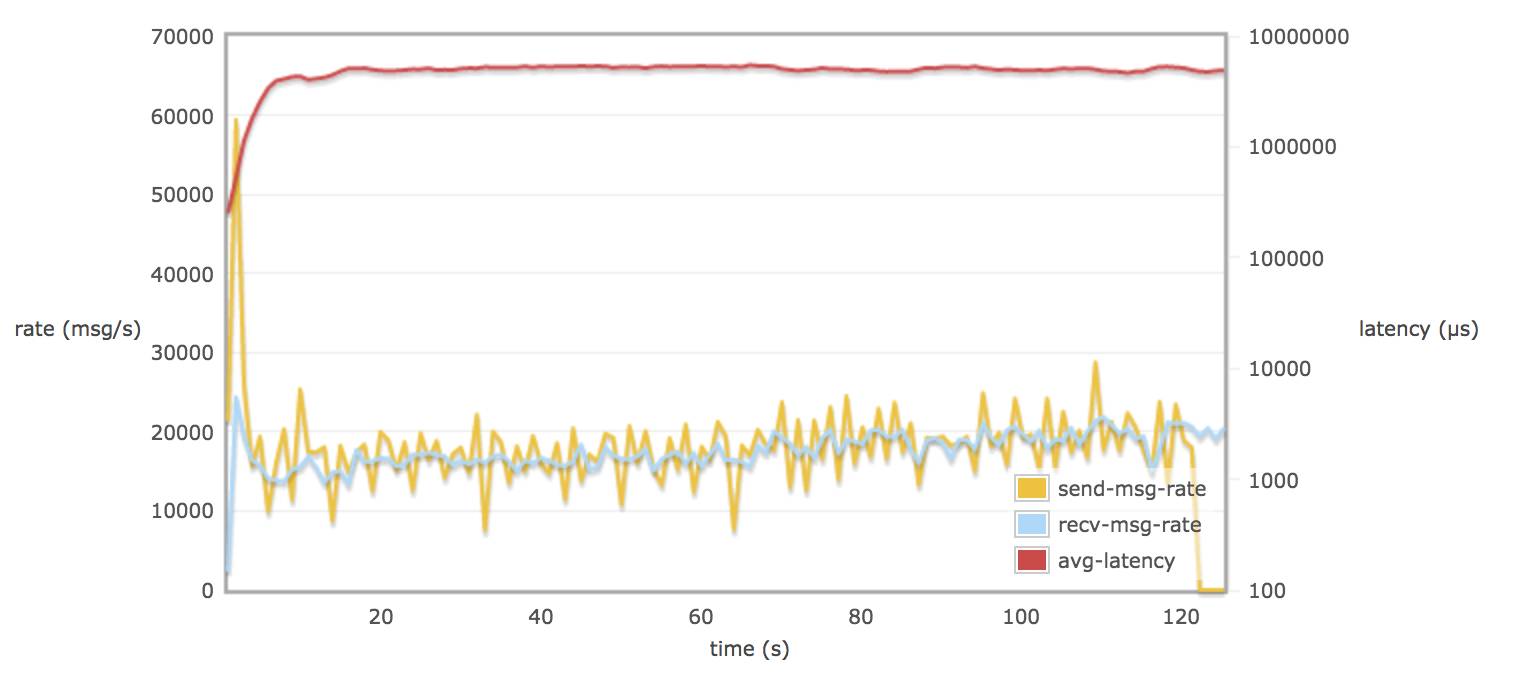
配置 hipe_complie:
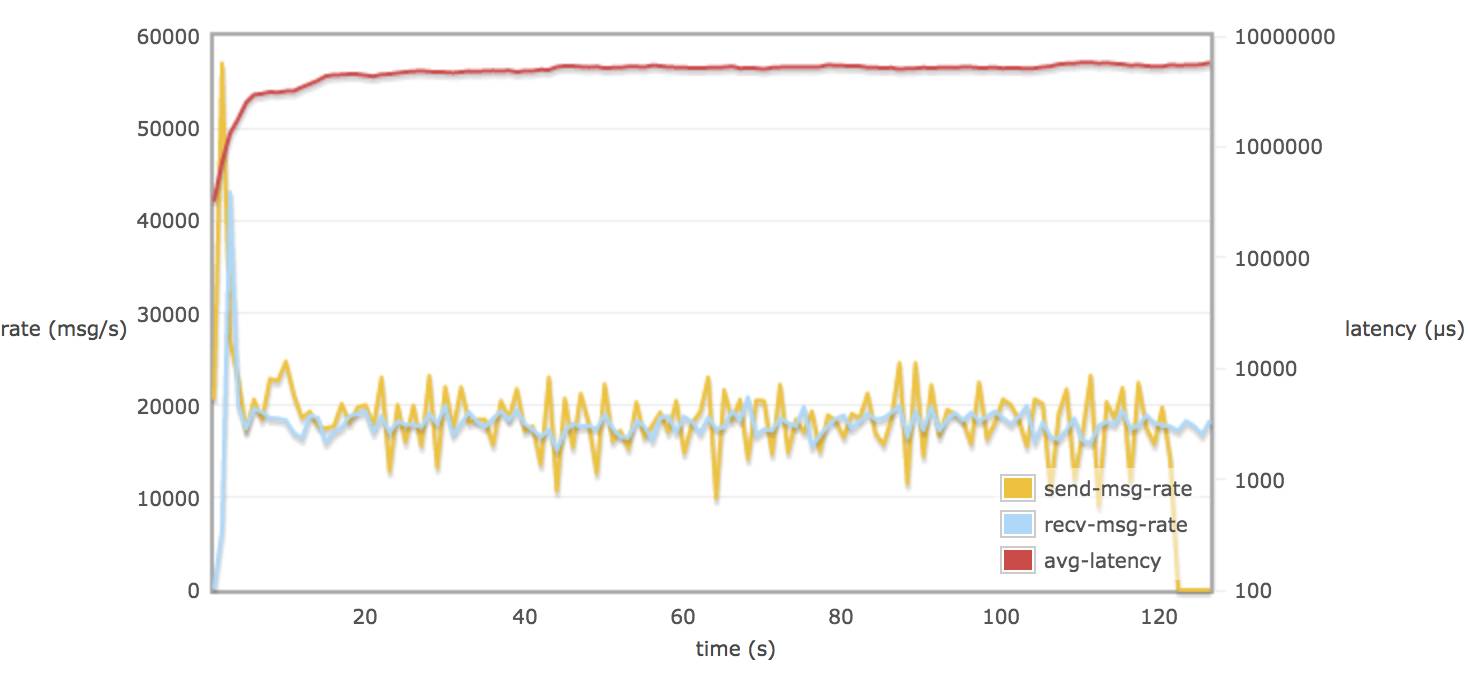
配置 tcp_num_acceptor 10 :
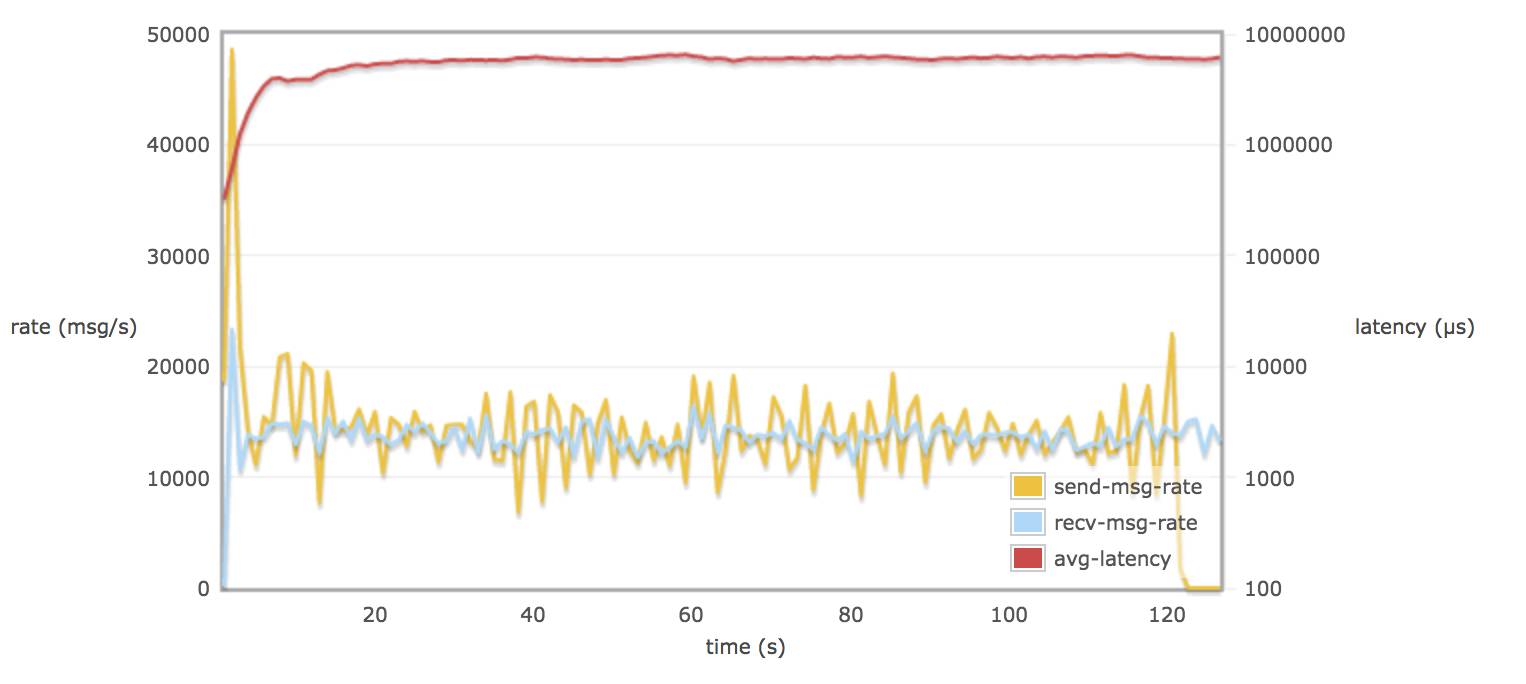
配置 tcp_num_acceptor 20
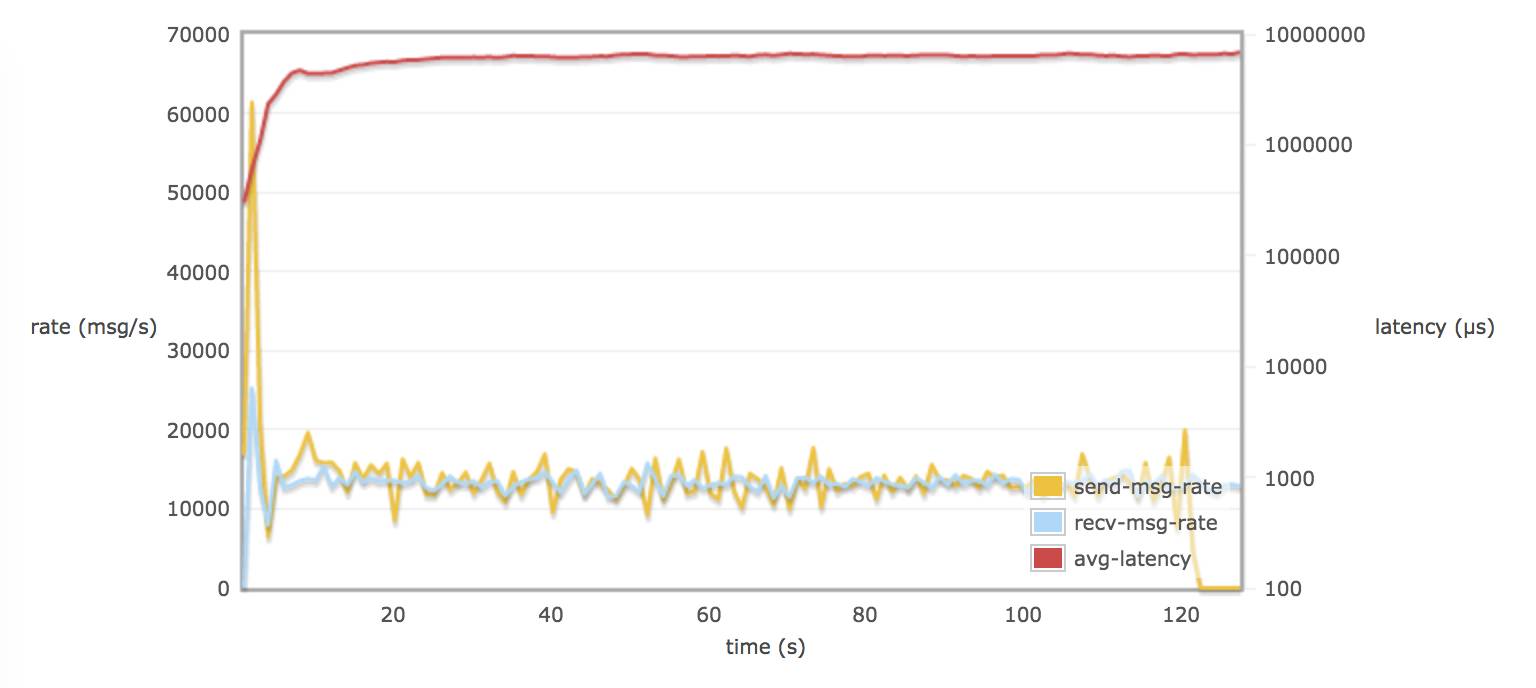
配置 tcp_num_acceptor 40:
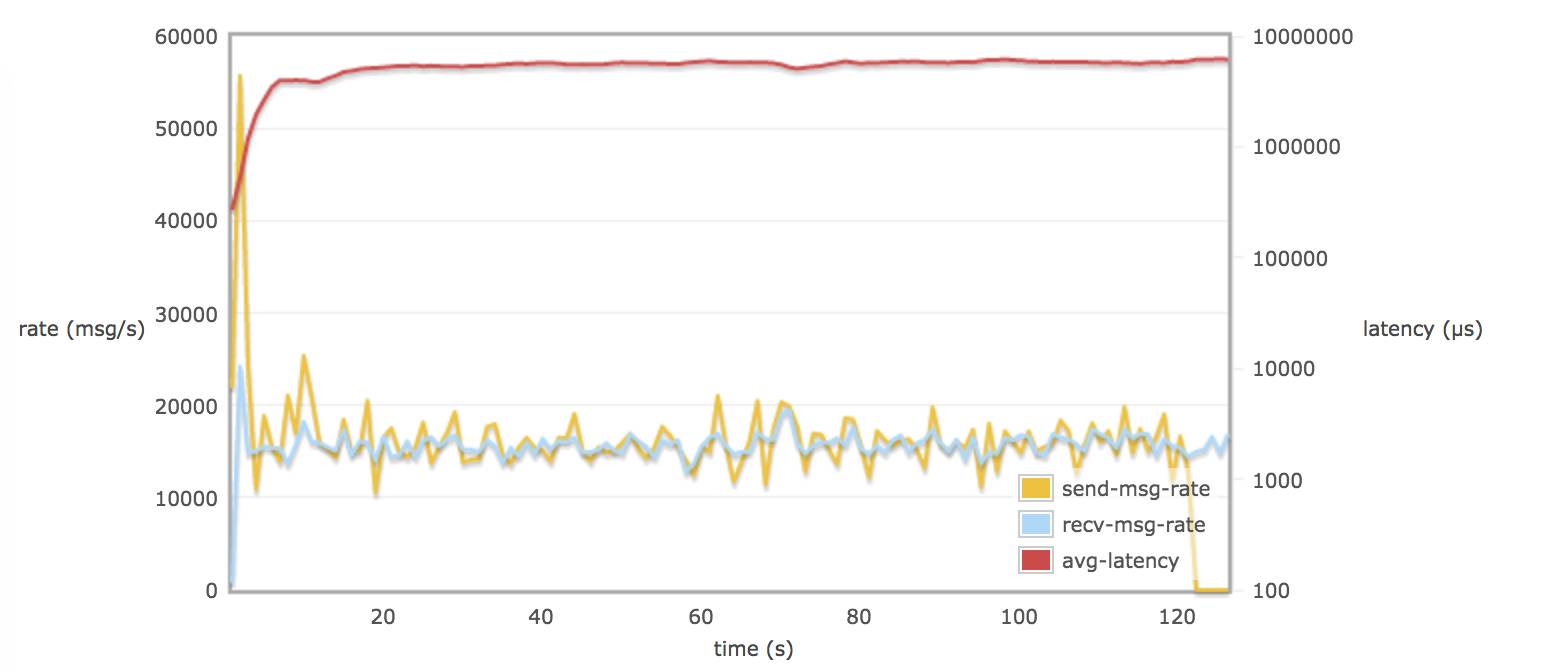
配置 delegate_count 64:
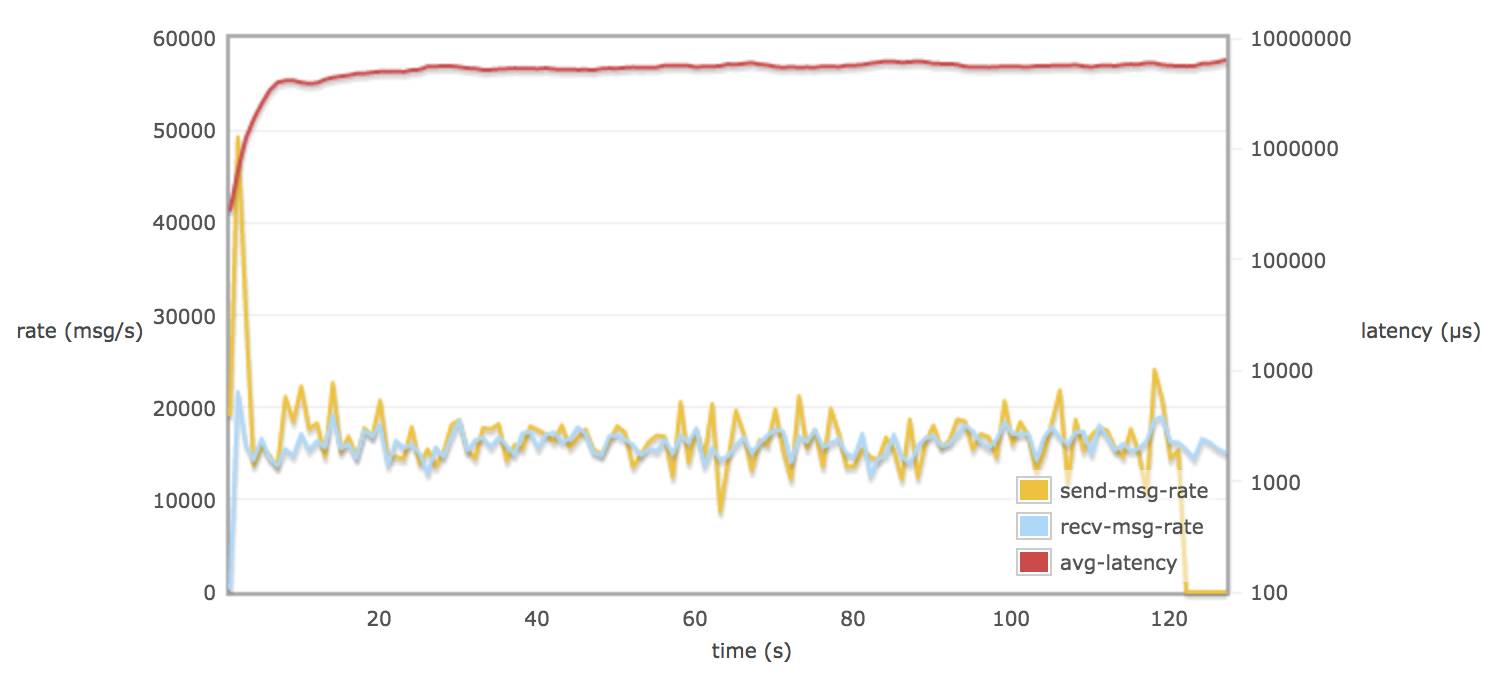
配置 delegate_count 128:
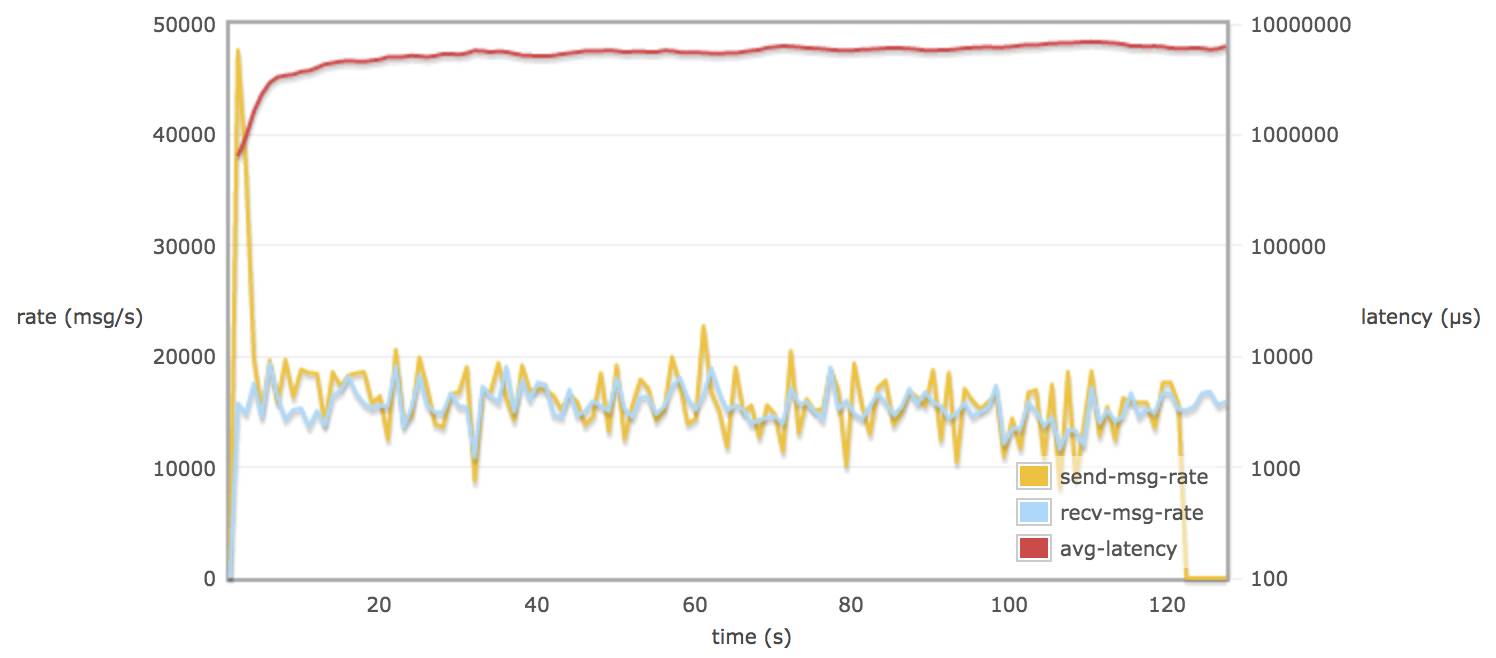
比较以上这些图的结论:
当30个 consumers 和 publishers 从一个queue 取消息时:
当30个 consumers 和 publishers 从一个queue 取消息时,调整 rabbitmq.conf 的参数对延迟(平均每个消息通过 broker 需要的时间)并不会有多大的改变(可能到达一个饱和的状态)。延迟一只保持在 8 - 9 s
在不配置 hipe_compile 时,消息的发送率和消息的接受率相似。(接近 13000 msg/s)15000 msg/s X 1.5 K/msg = 22.5 M/s
当配置了 hipe_compile 时,发送率和接受率平均值略接近 19000 msg/s (28.5 M/s)。
在不配置 hipe_compile 时,rabbitmq 发送率峰值可能达到 50000 msg/s (75 M/s)左右。
在配置了 hipe_compile,和 tcp_num_acceptor > 10 时,rabbitmq 发送率峰值可能达到 60000 msg/s(90M/s)左右。
30 个 publishers,30 个consumers,分别从 30 个 queue 上获取消息(持续 120s发送1.5K 包)
普通:
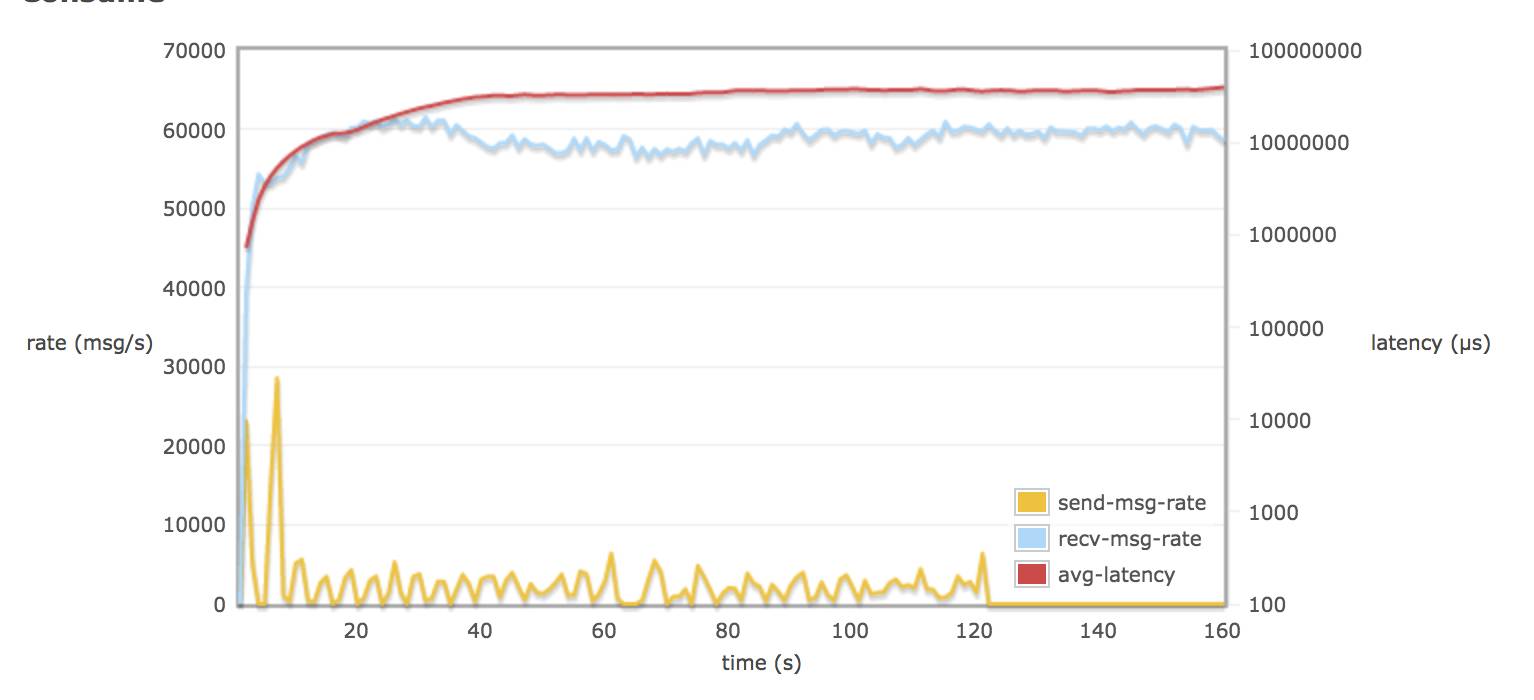
配置 hipe_complie:
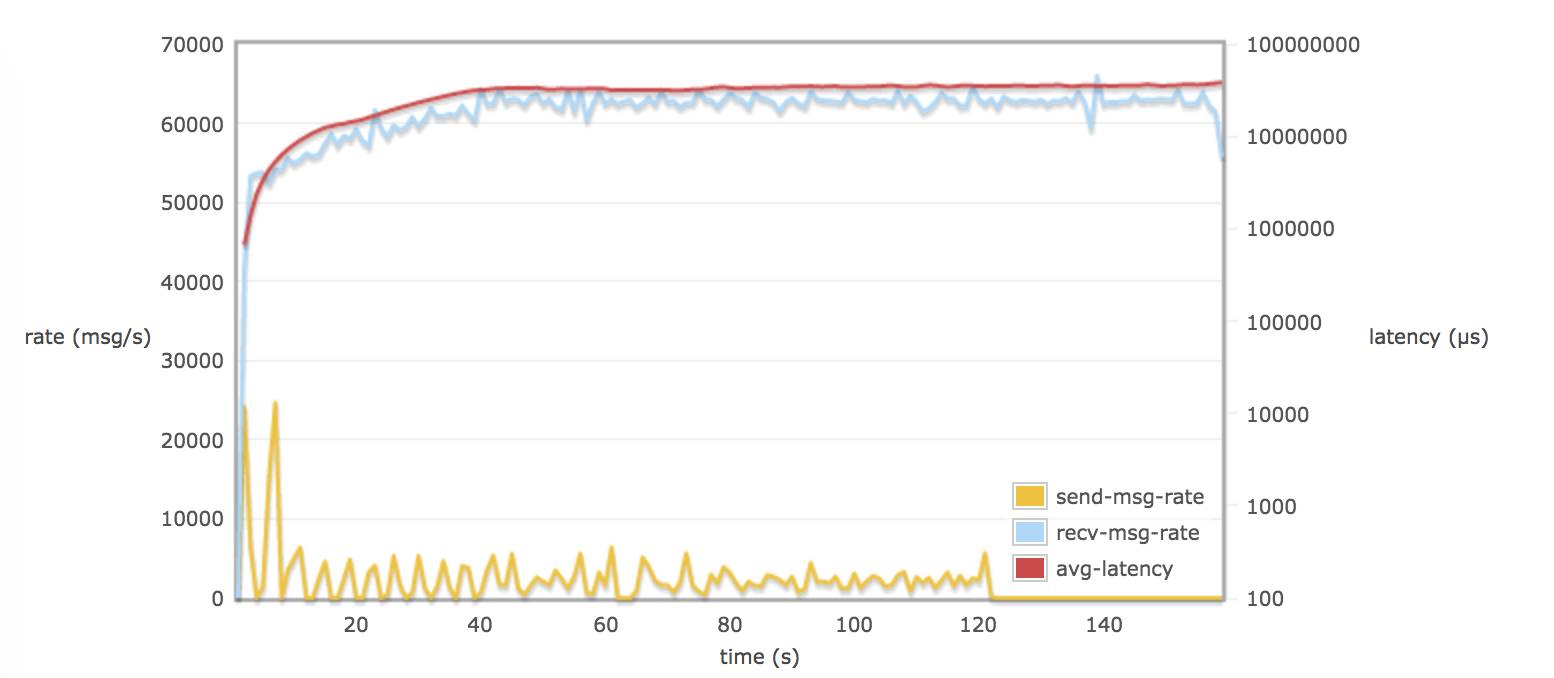
配置 tcp_num_acceptor 10 :
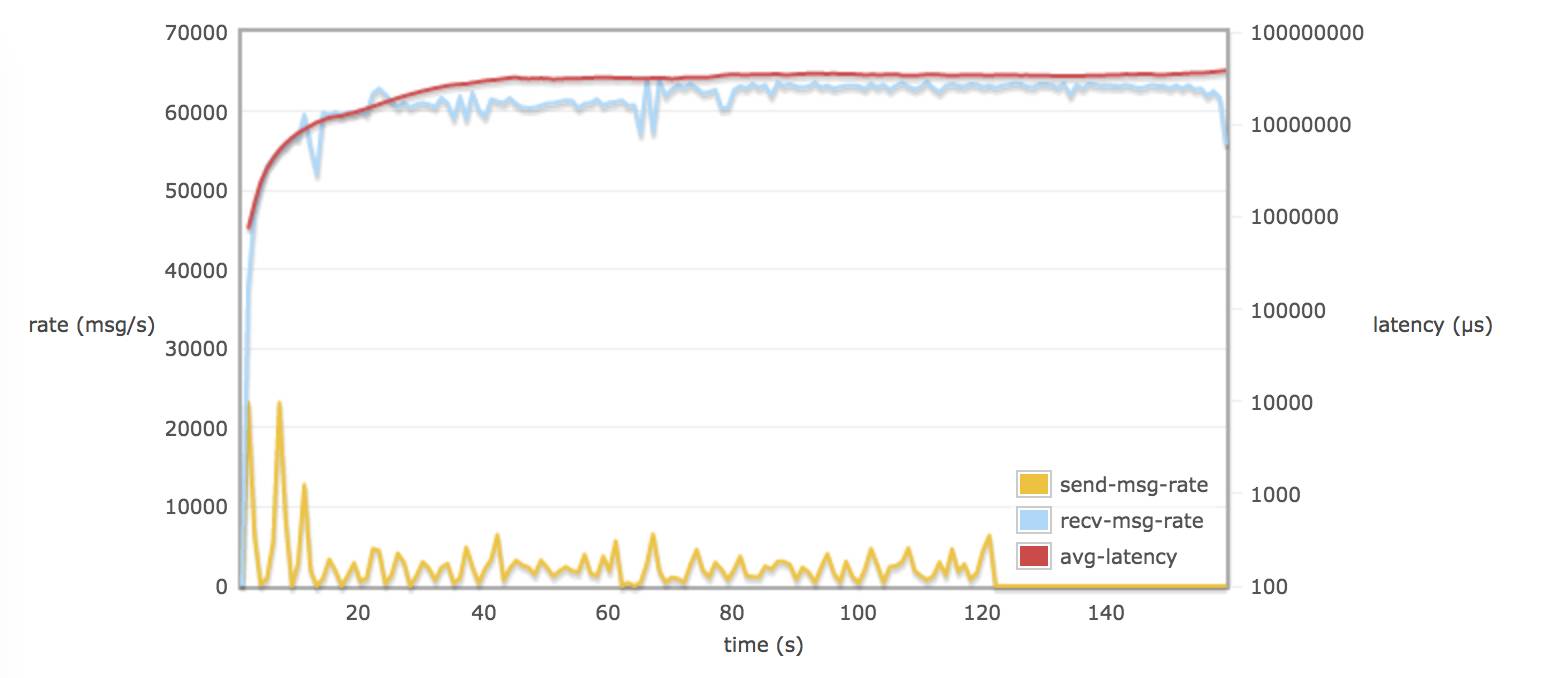
配置 tcp_num_acceptor 20 :
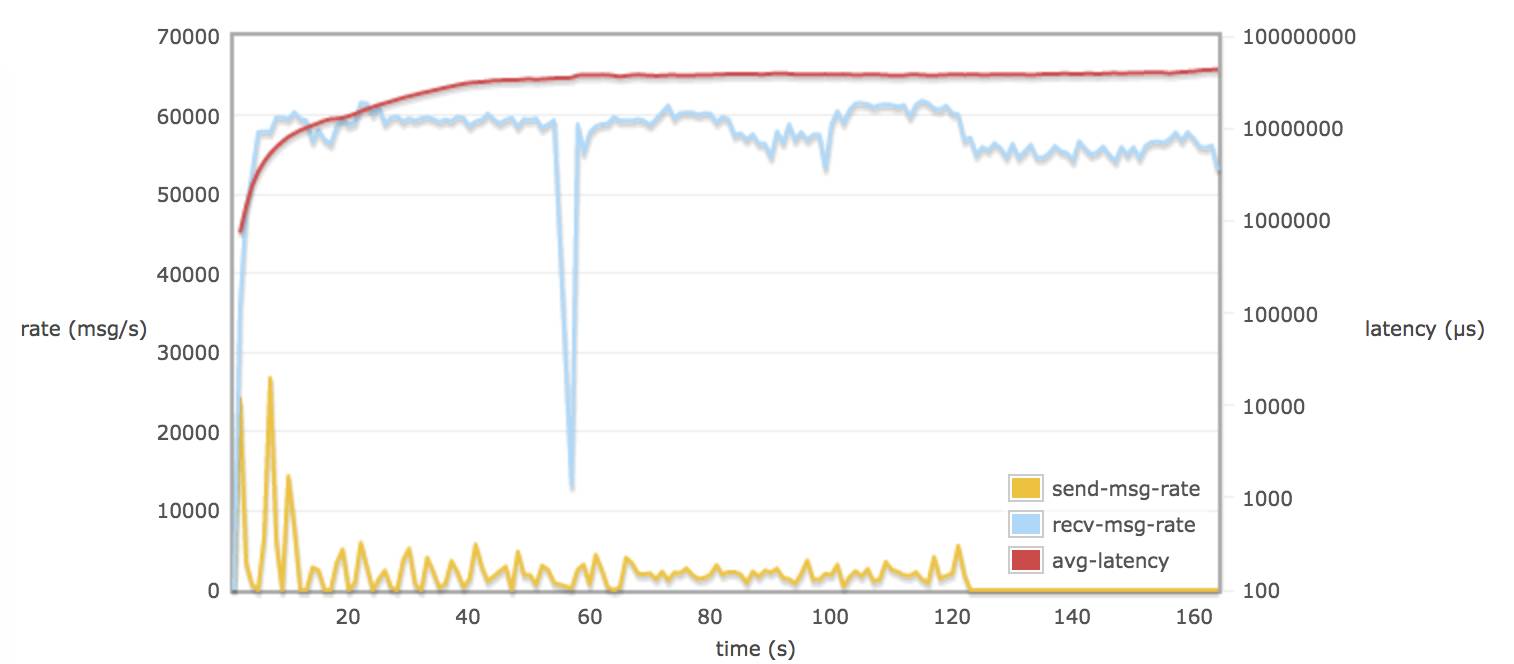
配置 tcp_num_acceptor 40 :
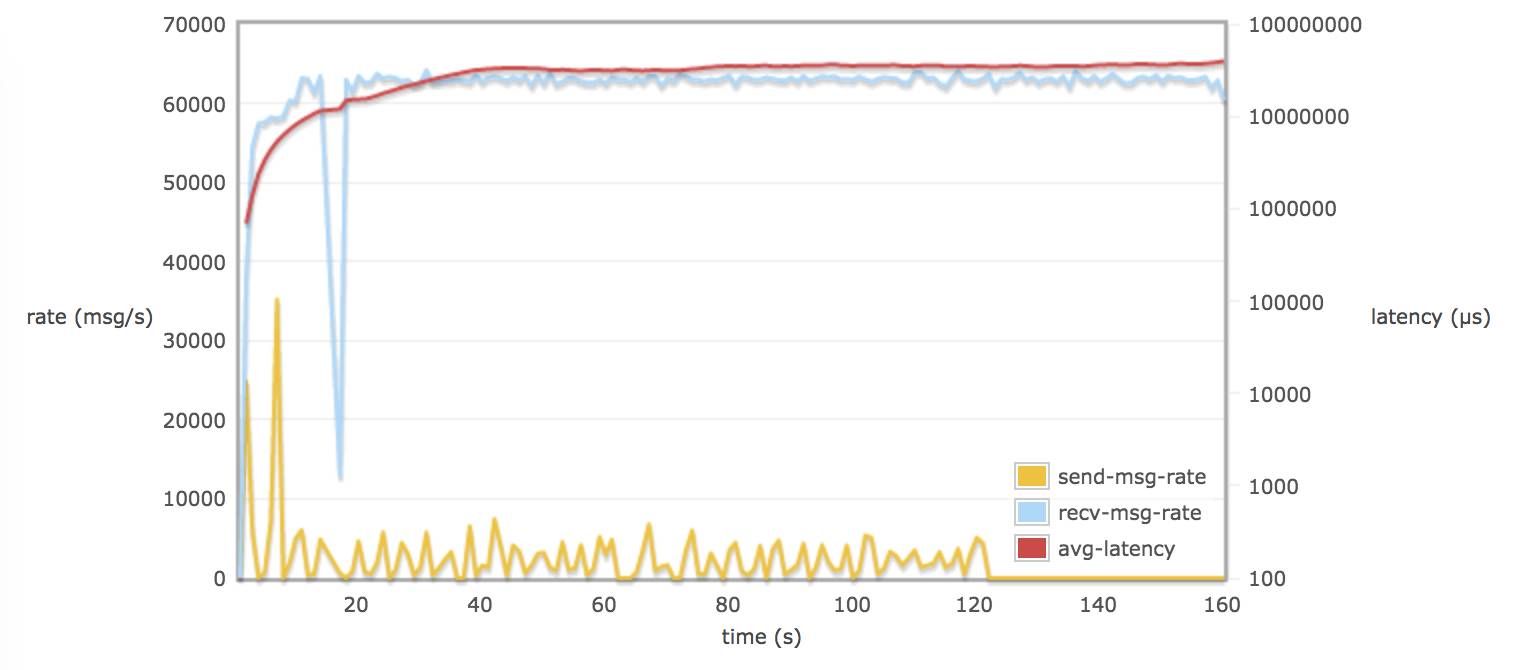
配置 delegate_count 64:
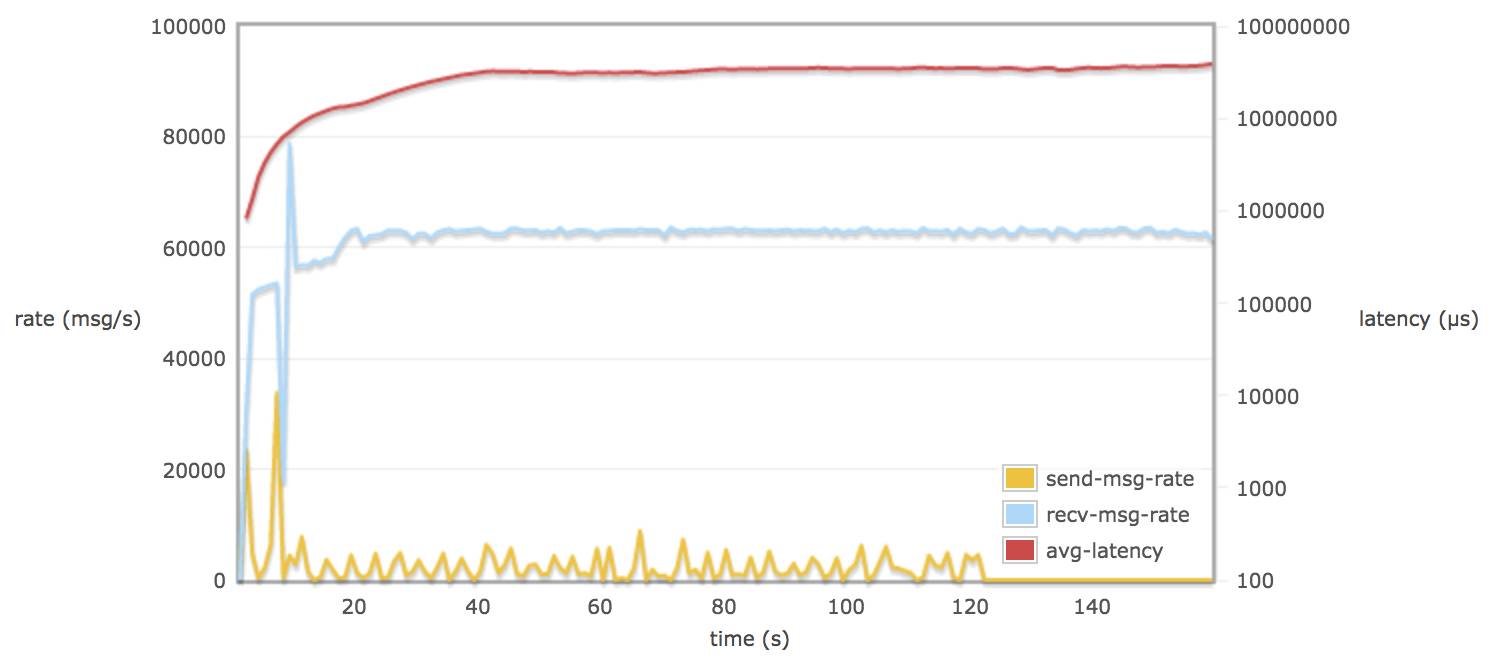
配置 delegate_count 128:
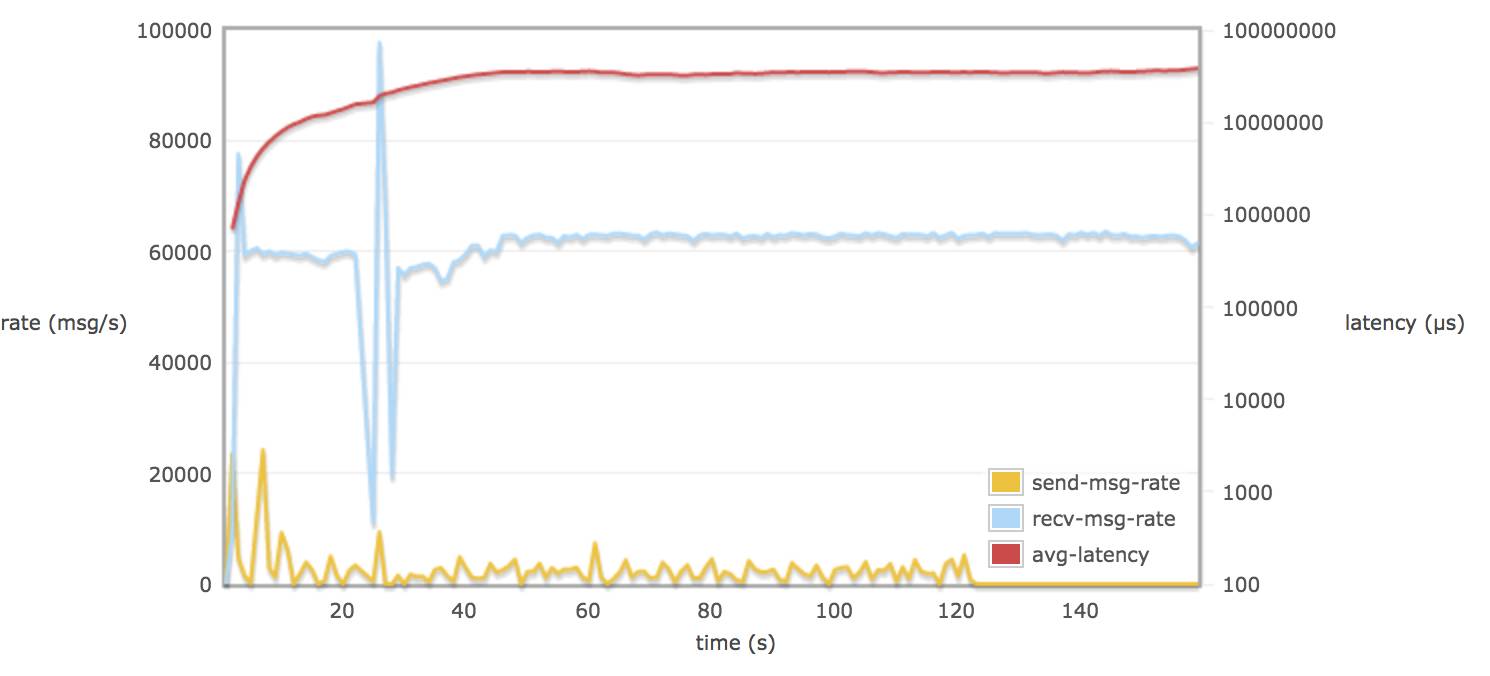
比较以上这些图的结论:
当30个 consumers 和 publishers 分别从 30 个 queue 取消息时:
调整 rabbitmq.conf 的参数对延迟(平均每个消息通过 broker 需要的时间)并不会有多大的改变(可能到达一个饱和的状态)。延迟一只保持在 60 - 70 s (为什么会有这么大延迟,可能是因为程序规定只跑 120s,不同 queue 上的数据在 120s 后仍然没有被消费掉,所以计算出延迟较大)。
接受速率比发送速率平均相差 60000 msg/s (90 M/s)左右,发送速率低是 rabbitmq server 进行了 flow control。
当配置 hipe_compile true, delegate_count > default 值, tcp_num_acceptor > default 值, 消息接收率的平均值都略微超过 60000 msg/s 。
当配置 delegate_count 和 tcp_num_acceptor,可能会导致消息接收率有较大波动。
对比 30 个 publishers,30 个consumers,从一个queue 上获取消息(持续 120 s 发送1.5K 包)和 30 个 publishers,30 个consumers,分别从 30 个 queue 上获取消息(持续 120s发送1.5K 包)两组
一个 queue 和多个 queue的两组图中,延迟都会到达一个饱和状态,到达这个饱和状态后,延迟就不在改变。且多个 queue 可能会使延迟增加(这可能和统计工具计算的方式有关,当延迟平均到每个 queue 上时,延迟就会变小)。
当在一个 queue 的情况下,消息发送率和接受率是类似的。但是当在多个 queue 的情况下,消息发送率明显低于消息的接受率。且不管是在一个 queue 还是多个 queue 的情况下发送率基本保持不变 接近 15000 msg/s。由此可见,限制 rabbitmq 的平静瓶颈很可能是在消息发送速率上。
配置 hipe_compile 可以略微提高效率 0.2 左右。
配置 delegate_count > default值 和 tcp_num_acceptor > default值 可能可以略微提高效。但是,可能会导致消息接受率波动较大。
rabbimq 对 cpu 消耗较大,对 mem 消耗有限制。
消息发送速率 VS 延迟
通过比较以上数据得出消息发送率是rabbitmq 效率的瓶颈。由此加了两个测试,看看消息发送率和延迟的关系。
测试样本:
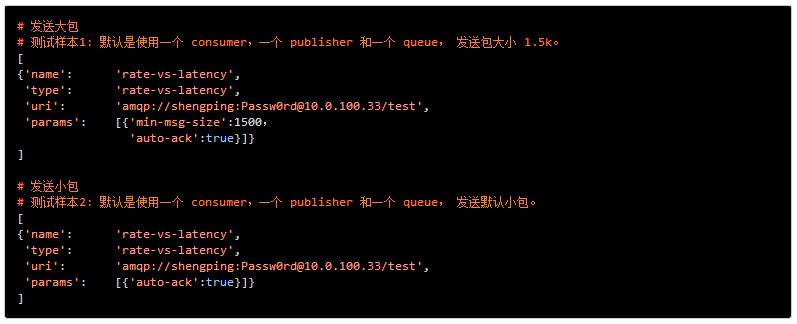
测试结果:
样本1测试结果 (发送 1.5K 包):
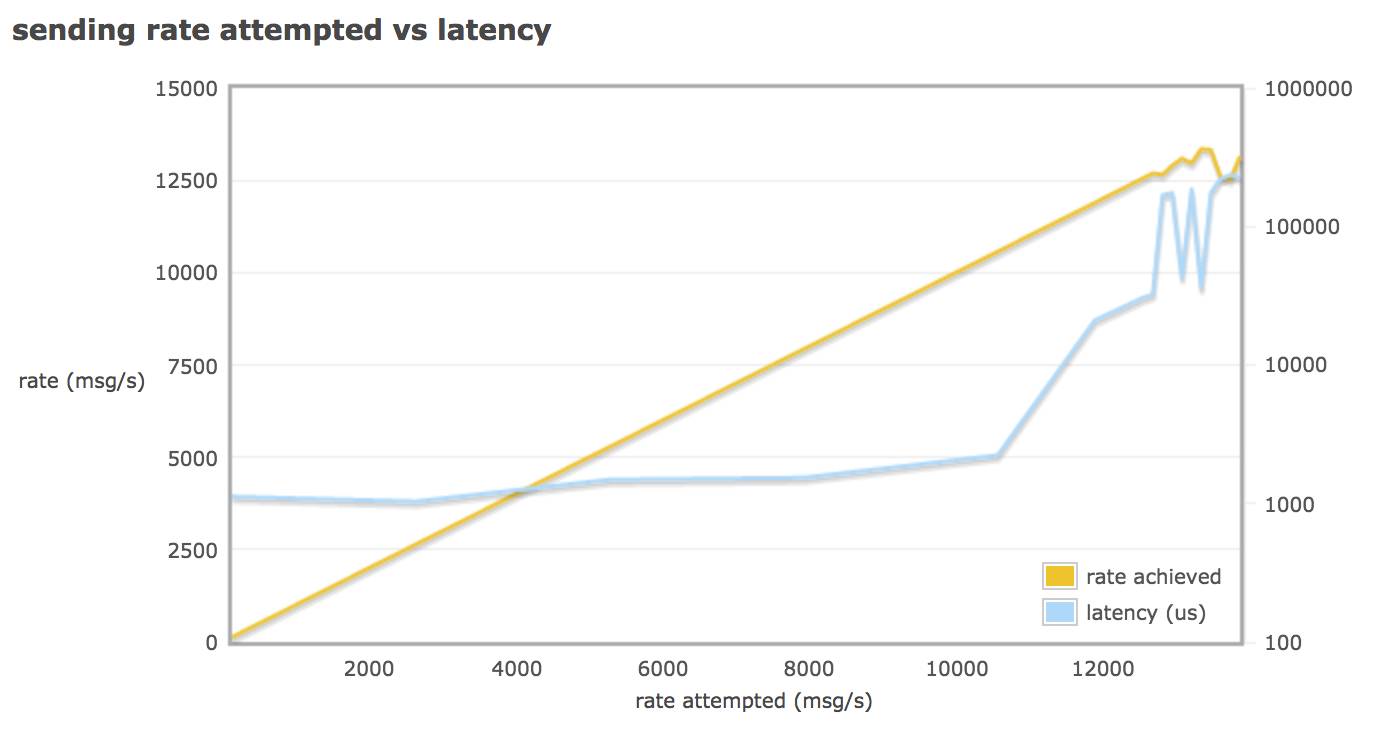
样本2测试结果:(发送小包)
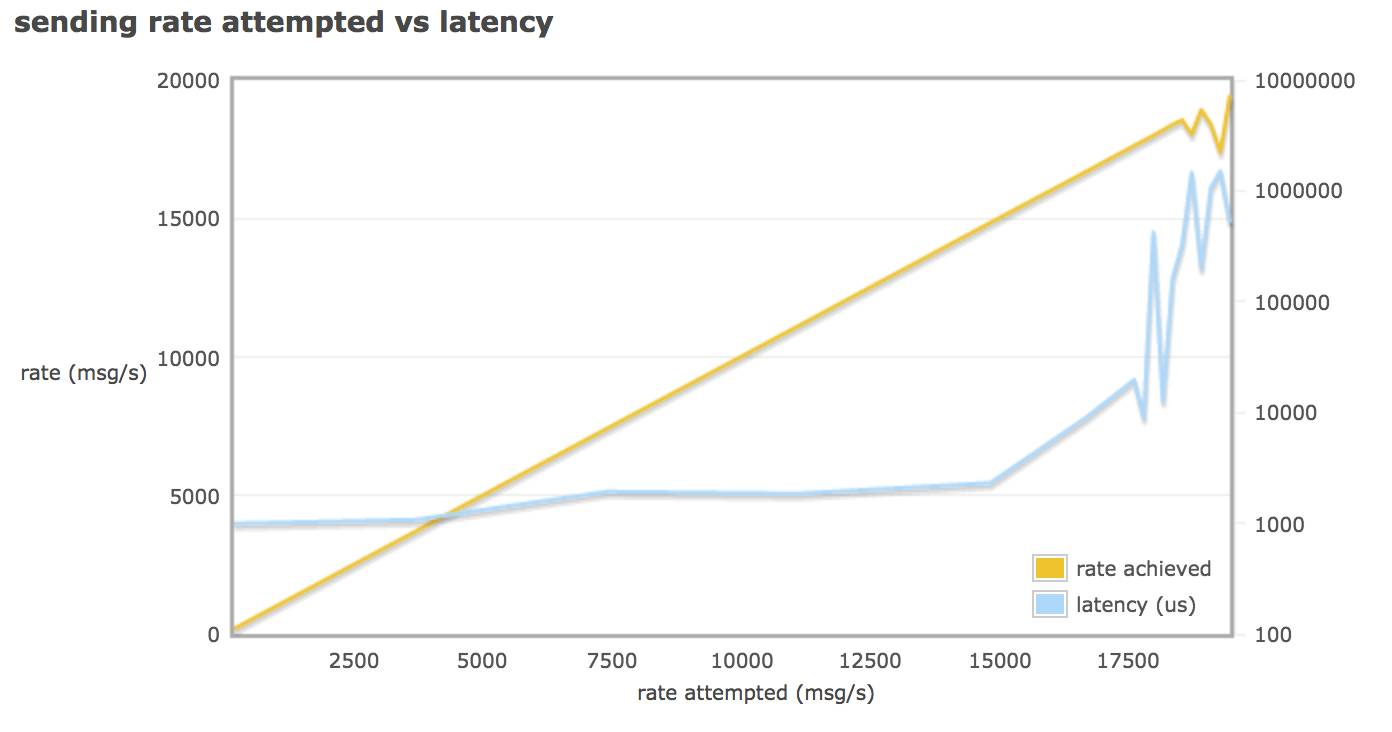
从以上两张图中可以看出:
当一个 publisher 一个 consumer 一个 queue 时:
1.5K 包发送率到达 10000 msg/s (15 M/s)时,蓝色的延迟线有明显上升。第二张图发送小包到 15000 msg/s (推测可能也是 15 M/s)时延迟线也是有明显的上升。所以如果可以最好保证每个 queue 发送率在 15 M/s 以下。
一个 queue 的最高发送率在 12500 msg/s X 1.5 K = 18.75 M/s 左右。当达到最高发送率,一个 queue 的延迟会在 0.5 s (如果多个 queue 延迟可能累积)。
导致 rabbitmq 发送率低的原因:
rabbitmq 发送率较低,是由于 flow control 限制。flow control 限制 rabbitmq client 的链接数。flow control 控制 rabbitmq 消息输入速率,让 server 有时间来处理输入的消息。
flow control 状态表示某个 publishing 是受限的,在 client 端则表现出网络带宽收到限制(比如之前的 28.5M/s,15M/s )。flow control 状态可以表现在:connection, channel,queue 中。
当一个 message 传入 rabbitmq 到被保存下来经历了:
Network
↓
Connection process - AMQP parsing, channel multiplexing
↓
Channel process - routing, security, coordination
↓
Queue process - in-memory messages, persistent queue indexing
↓
Message store - message persistence
当 flow control 状态只出现在 connection 中,而没有出现在 channel 中,说明 channel 处可能遇到瓶颈。 原因可能是服务器受 CPU 限制,或者路由逻辑有问题。
当 flow control 状态出现在 connection 和 channel 中,而 queue 中没。说明 queue 中可能出现瓶颈,原因可能是服务器受 CPU 限制导致接受消息变慢,或者 I/O 限制保存消息变慢。
当 flow control 状态出现在 connection,channel,queue 中。 说明消息储存是瓶颈。原因可能是 I/O效率较低。
结合以上结论分析下我们自己的环境:
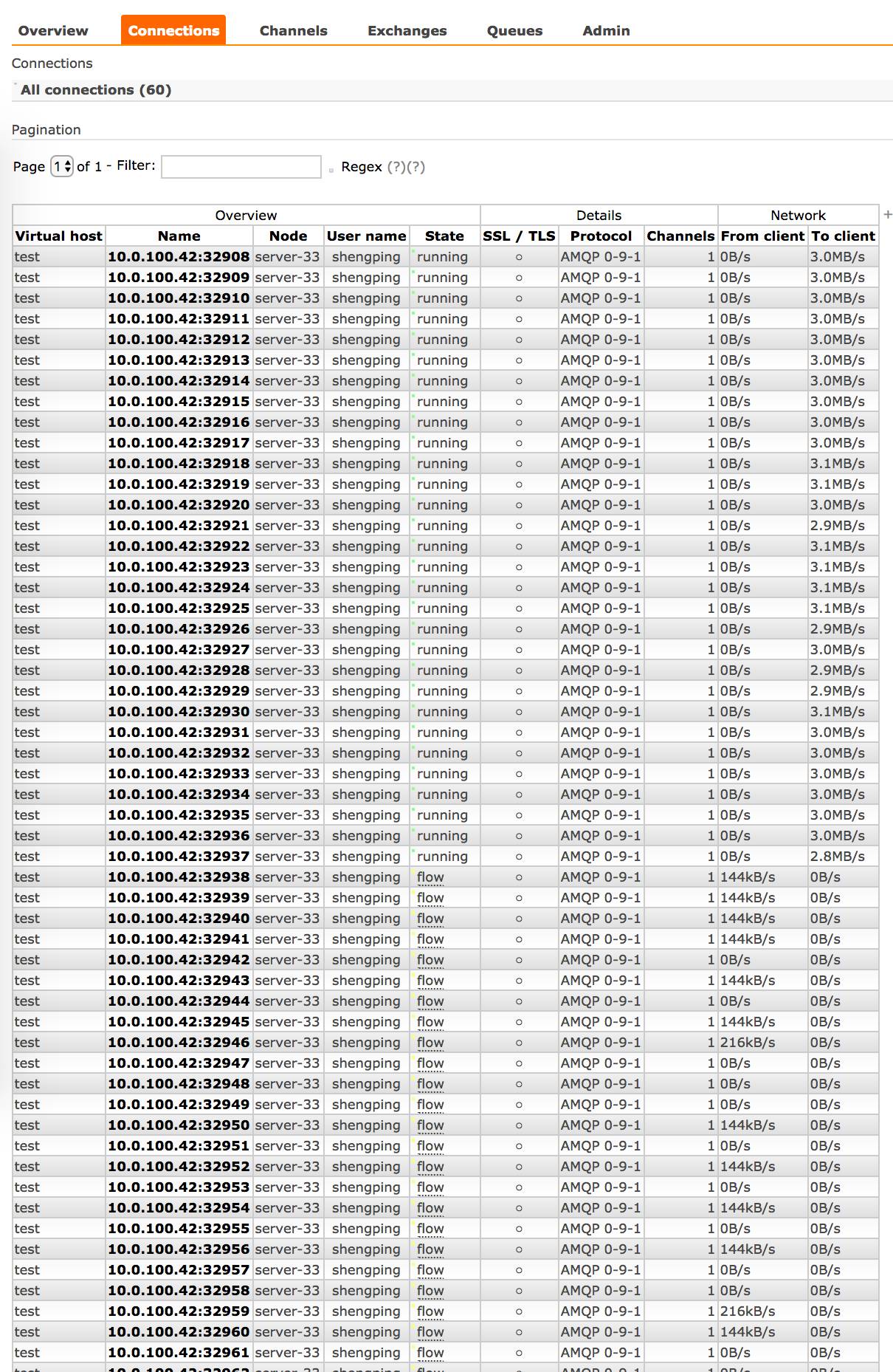
当发送 30 个 publishers, 30 个 consumers, 30 个queue,连续 120s 发送 1.5 K 包时 (以上任何配置下):
connection 中 30 个 publisher 状态都是处于flow:
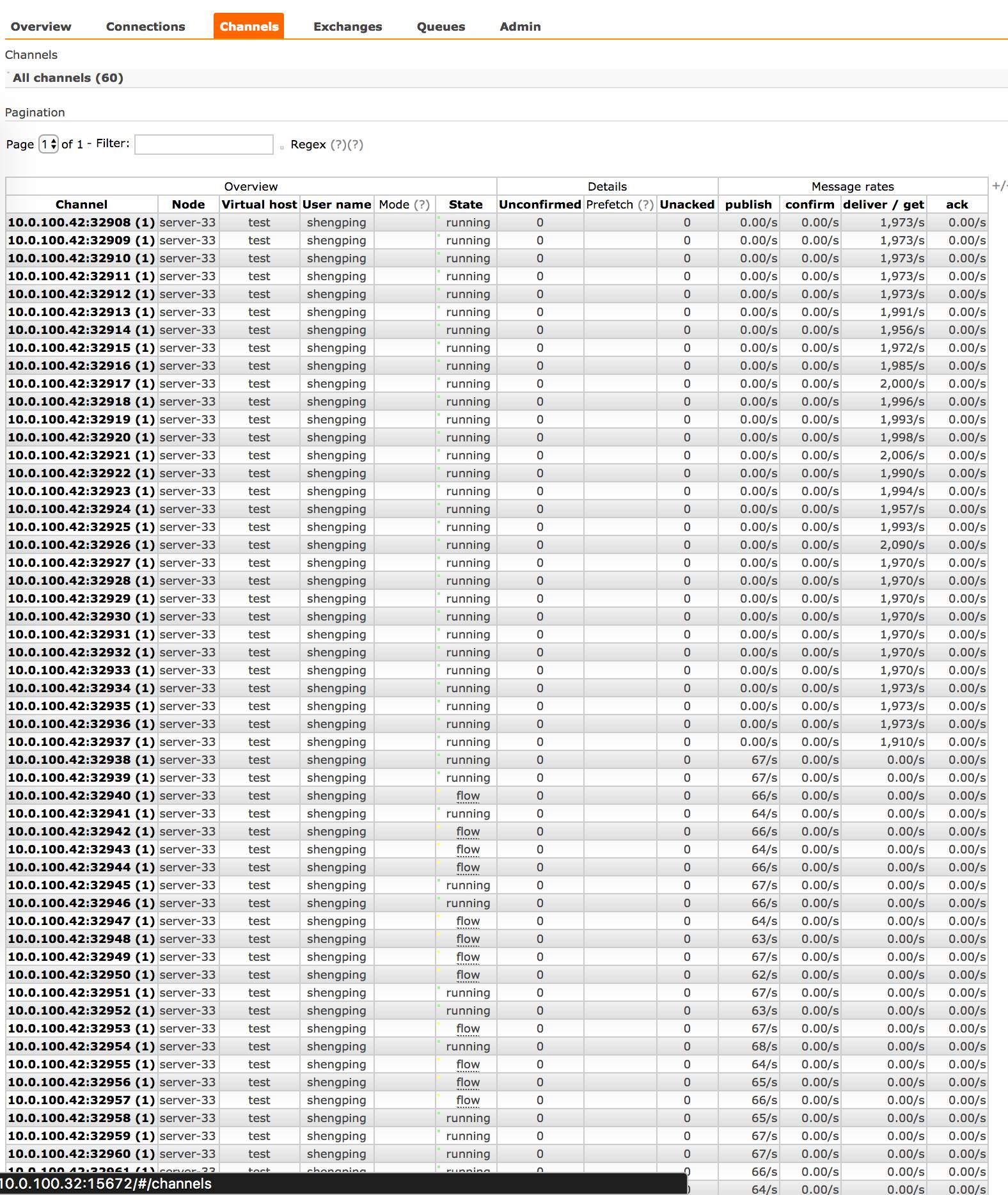
channel 中 30 个 publisher 的 channel 也是处于 flow 状态:
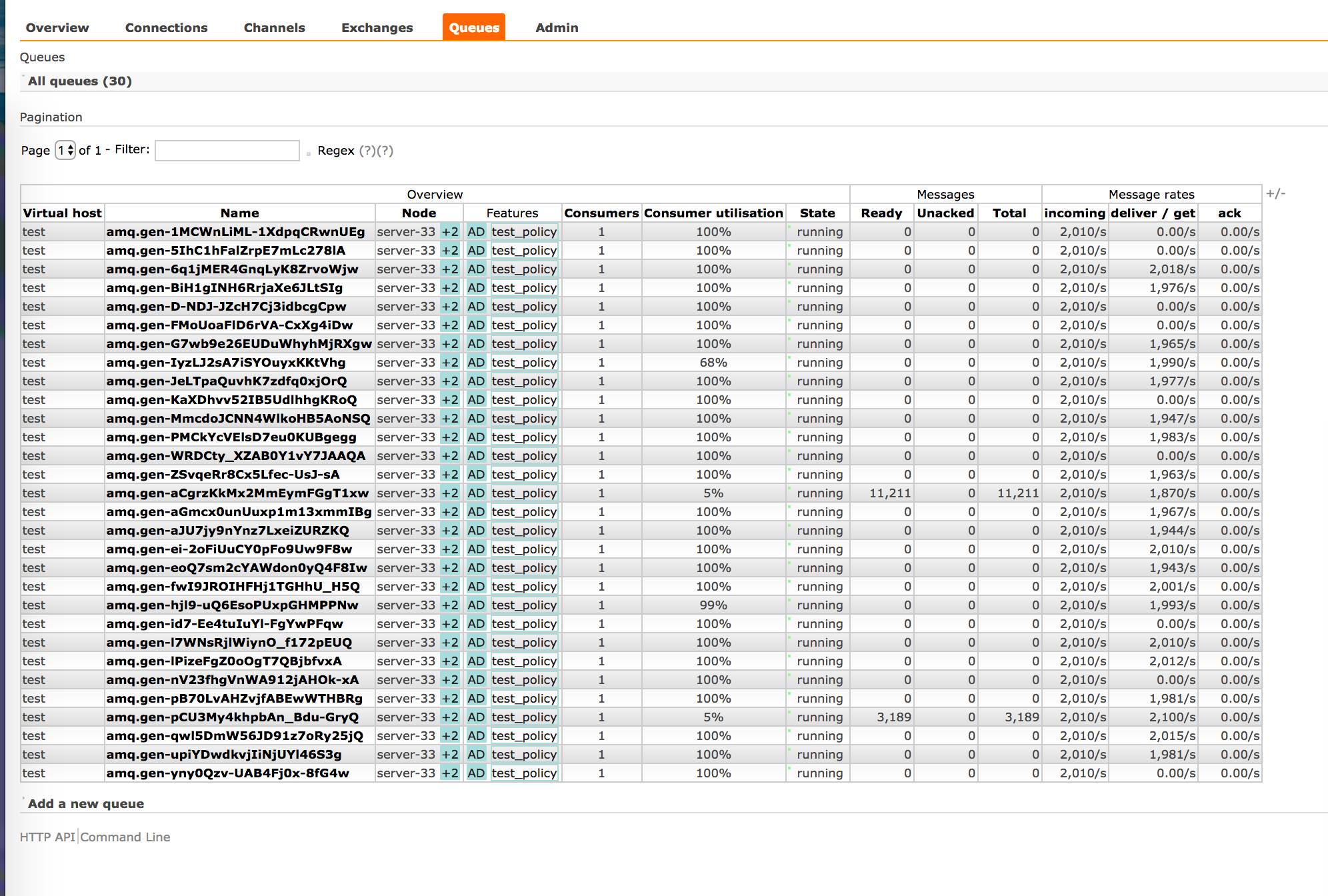
queue 都是正常的 running 状态。
CPU 利用率
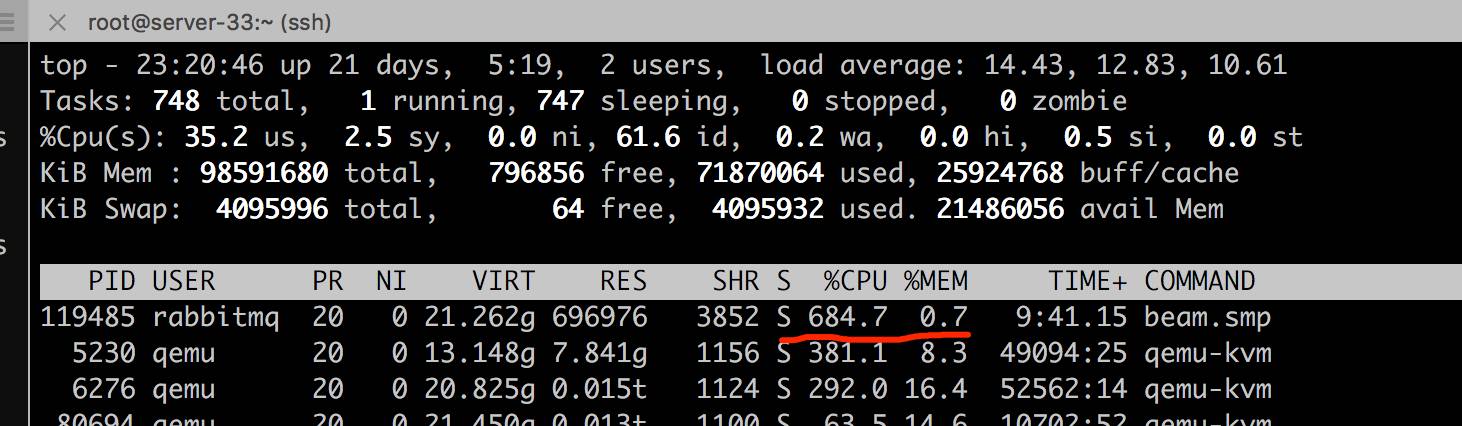
结论分析
可见环境中的情况是:queue 中可能出现瓶颈,原因可能是服务器受 CPU 限制导致接受消息变慢,或者 I/O 限制保存消息变慢。
这里必须提到 rabbitmq 中的另一个重要的概念 credit_flow, 这在很大程度上也影响着 rabbitmq 的吞吐量。然而我们很少情况下去调整 credit_flow 大小,通常情况下用默认给定的保守值(200,50)。
而且当一个节点在一段时间内承受压力较大时,可能会使该节点 rabbimq 暂时处于”假死“状态。
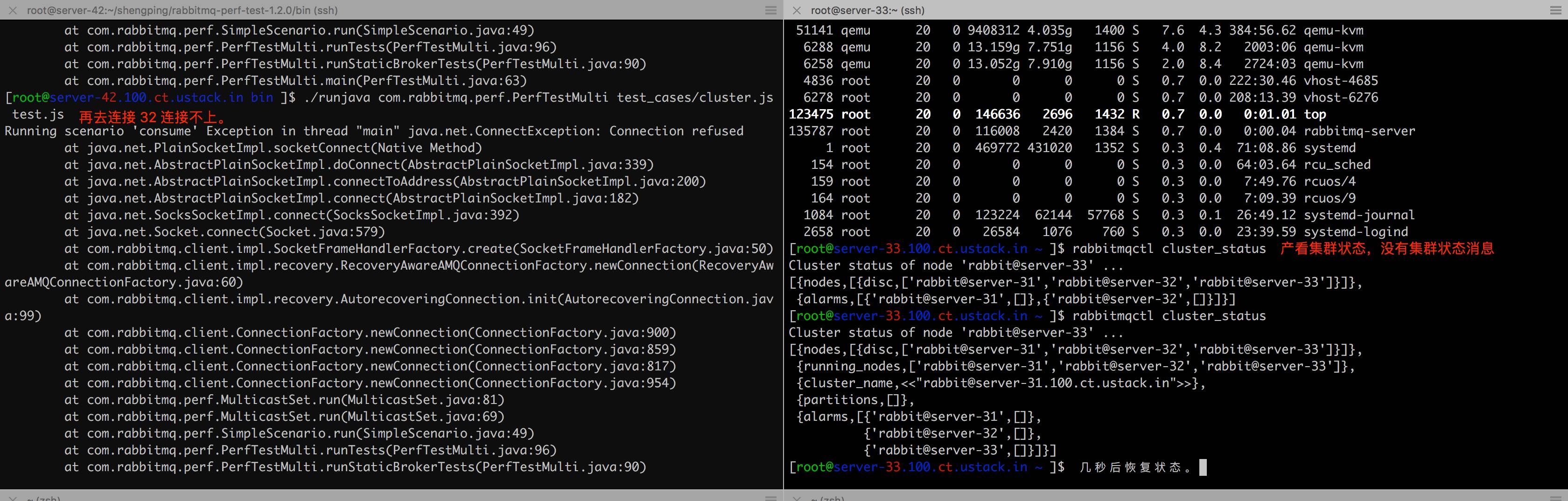
总结:
通过总结以上个小节结论的图和现象中可得下几点:
hipe_compile 会增加 0.2 的效率。
delegate_count 和 tcp_num_acceptor配置较大,可能会导致消息接收率有较大波动。
一个节点压力过大,可能会“假死”。
对 erlang 和 rabbitmq 了解有限,其他地方可能得后续观察总结。
以上是关于UOS 4.0 - RabbitMQ 参数调优分析的主要内容,如果未能解决你的问题,请参考以下文章
UOS 4.0 - Role-Based Access Control(RBAC)
(转)linux IO 内核参数调优 之 参数调节和场景分析
R语言使用caret包对GBM模型参数调优SVM模型自定义参数调优RDF模型自定义参数调优(例如,ROC)重采样对多个模型的性能差异进行统计描述可视化多模型在多指标下的性能对比分析