工作中rabbitmq的使用
Posted 还是那个徐东强
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工作中rabbitmq的使用相关的知识,希望对你有一定的参考价值。
拾人牙慧,将工作中rabbitmq那块的核心代码的枝干抽出,解析一下,主要涉及三个部分
1.生产消费普通模型
将消息发送到exchange中,exchange一边接收消息,一边负责将消息路由到指定的queue中 ,消费端消费
根据(消息发送时候过来的routingkey以及queue和exchange的bindingkey是否匹配)
2.延迟队列的实现
当消息被发送以后,并不想让消费者立即拿到消息,而是等指定时间后,消费者才拿到这个消息进行消费。
3.服务发布双云,有时会有这样的需求,一个服务某方法执行的时要求另一个云也执行
场景1:非同步缓存的清理。当腾讯云缓存的内容发生改变时,除了清理腾讯云的缓存,还需要发布一个消息,指定清理aws云的缓存,否则轮询会有结果不一致的情况。
场景2:由于某些触发条件导致zk值改变,需要同步修改另一个云的zk的值,否则轮询会出现返回的结果不一致的情况。比如开关存在zk上,轮询到一个云,获取的结果是关闭,但是验证的时候,轮到到另一个云,此时结果是打开,那么就怎么样也无法通过校验了。
首先是代码,抽出了枝干,去掉敏感信息截图
spring的配置文件如下:
生产端:(ProdudceTemplate代码如下)

如何使用?只需要通过@Autowired引入ProduceTemplate对象,调用对应的send方法即可。如果希望消息延迟下消费,则指定延迟的时间(单位:分钟)
send方法做的事情比较简单,调用spring提供的amqpTemplate.send,参数包括了routingkey,消息body,消息的properties
消费端:(代码如下)
1.定义MessageConsumer接口,其中方法 指定消息的routingkey 以及如何处理消息的handleMessage
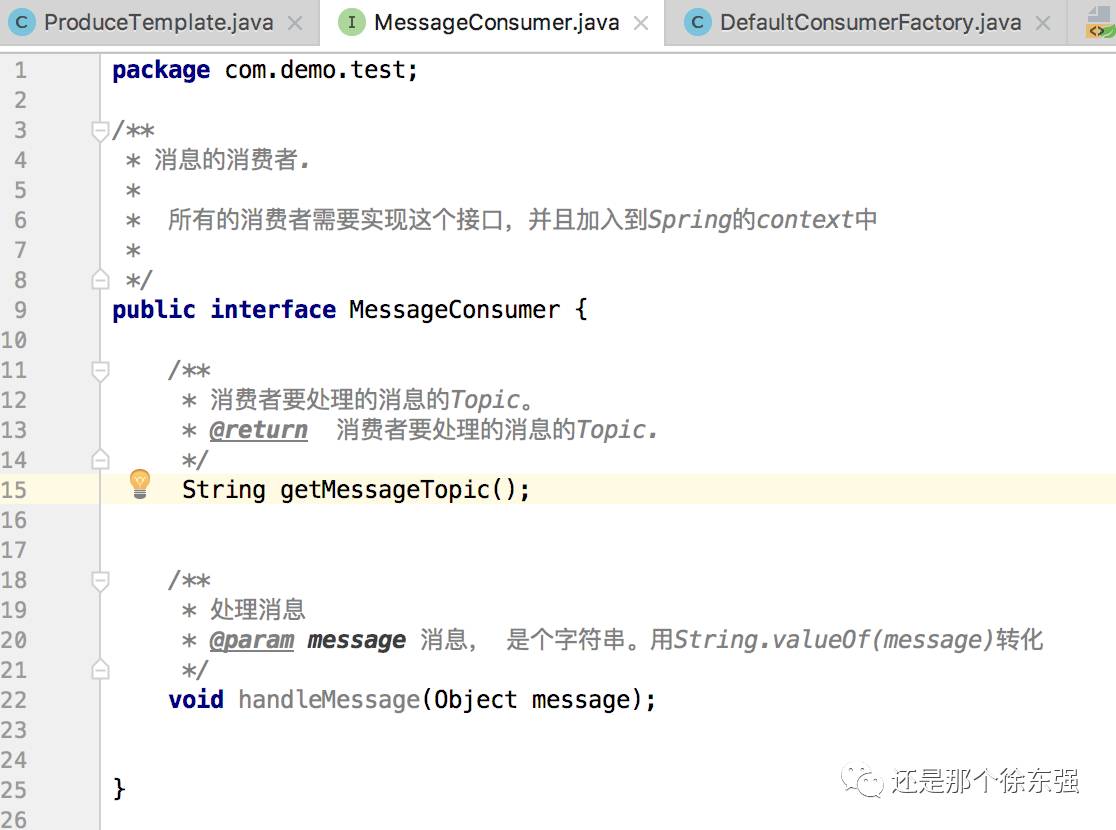
各服务中只需要 实现MessageConsumer接口,指定routingkey,重写handleMessage。并且加入到ApplicationContext中即可轻松通过mq实现生产消费。
为什么能够做到?
那是因为定义了一个消息消费工厂类,实现ApplicationContextAware
通过 applicationContext.getBeansOfType可以拿到 项目中用到的所有实现了MessageConsumer接口的实现类,其中key=在applicationContext中的id,value=具体的实例
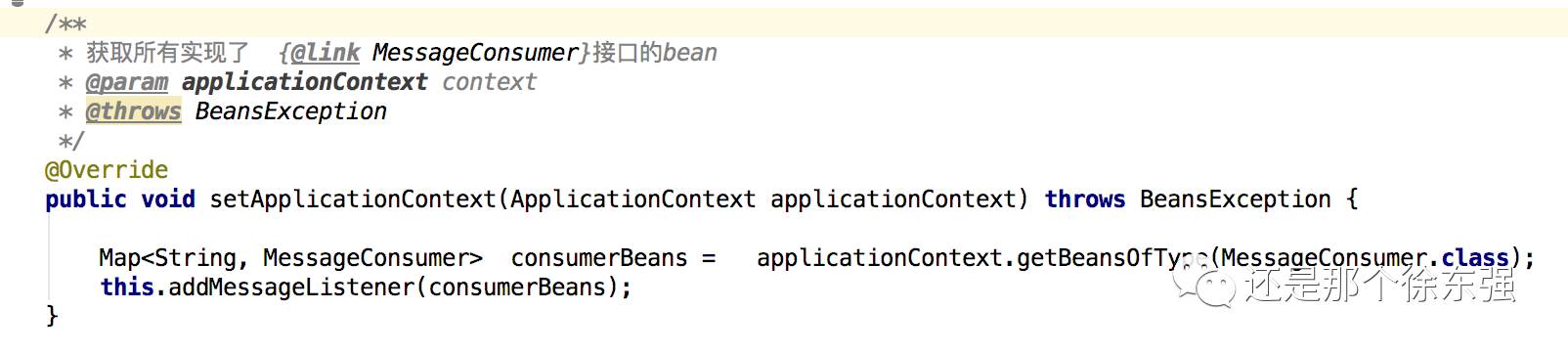
遍历获取的MessageConsumer接口的实现类
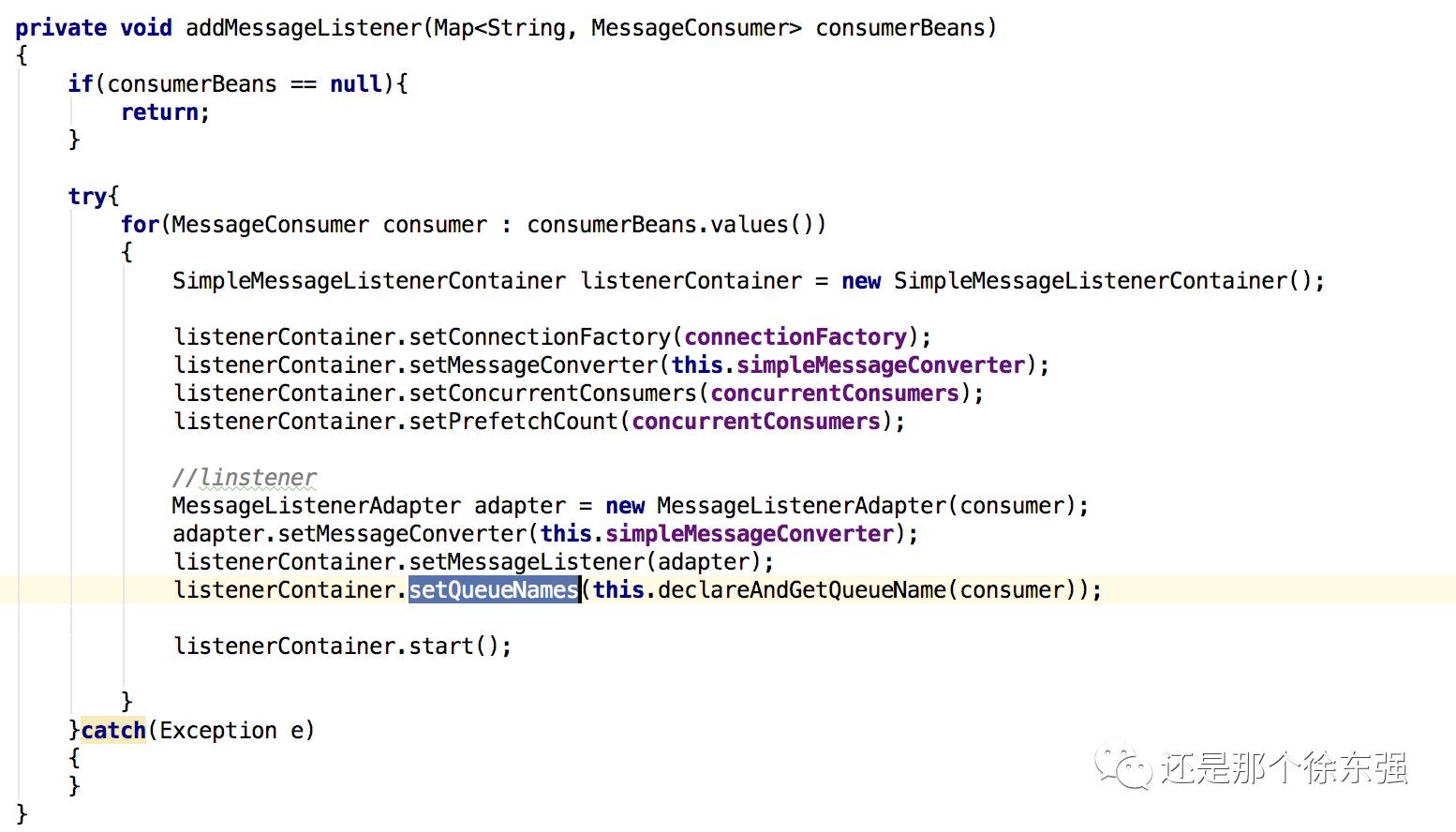
MessageListenerAdapter:消息监听适配器,消息监听器一共有三种:
MessageListener、SessionAwareMessageListener和MessageListenerAdapter
MessageListener是最原始的消息监听器,定义了一个onMessage方法,接收一个message参数
SessionAwareMessageListener是spring为我们提供的,不是标准的JMS的MessageListener,使用的场景,当我们接收到一个消息时,需要回复一个消息的场合使用。它提供了onMessage处理消息方法,接收一个message参数,以及session参数,sesion参数可以发送消息
MessageListenerAdapter类,主要把接收到的消息进行一个类型转换,然后利用反射把他交个真正的消息处理器。如果它真正的消息处理器是上面的二者任一,则直接调用onMessage方法,而不会去反射调用。
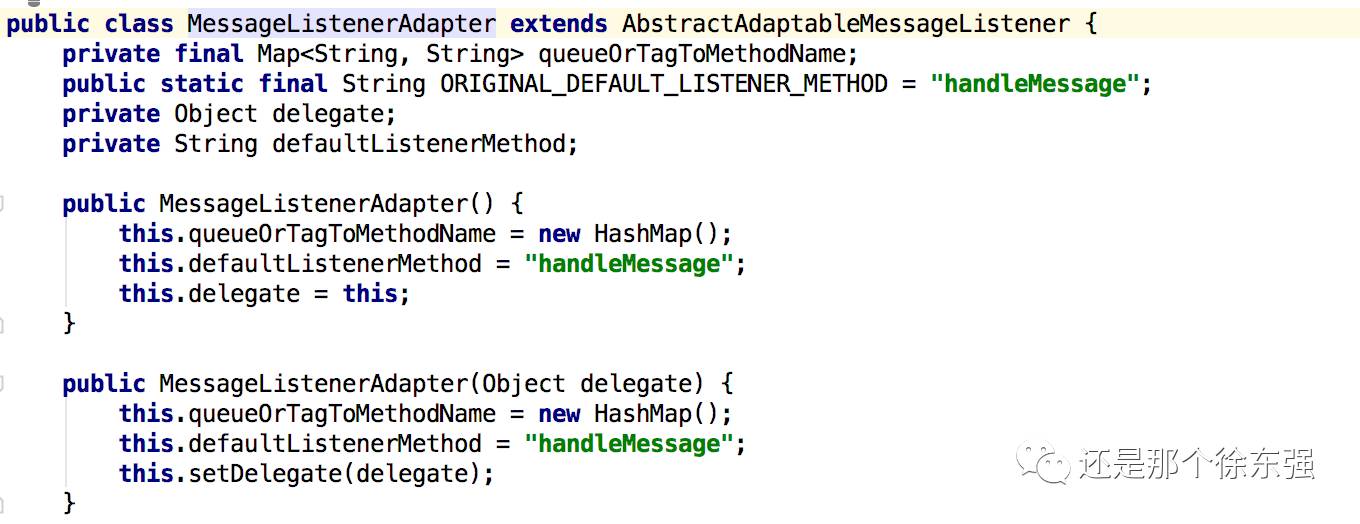
当我们自定义消息处理器的时候,可以在MessageListenerAdapter中指定两个参数
delegate:我们自定义的真正的消息处理器
defaultListenerMethod: 消息处理其中处理消息的方法,不指定默认是handleMessage
SimpleMessageListenerContainer: 有了messageListener消息监听器,我们还需要定义消息监听适配器对应的监听容器。
指定以下的参数:
指定哪台rabbitmq主机? setConnectionFactory
指定消息转换器? setMessageConverter
指定消费端消息的并发能力? setConcurrentConsumers setPrefetchCount
指定消息监听器 setMessageListener(自定义的消息处理器)
指定监听哪个队列? setQueueNames
下面以服务A中发布一个消息demoMessage,服务B中消费消息画图

1.不管是服务A还是服务B都指定 connectionFactory 指向同一个
2.服务A 直接通过@Autowired注入ProduceTemplate,掉用send方法,指定routingkey=mian.test, message=demoMessage对象
3.服务B 消费者实现接口MessageConsumer,通过getMessageTopic指定routingkey=mian.test,实现handleMessage方法=处理消息。下面是消息监听的queue的由来
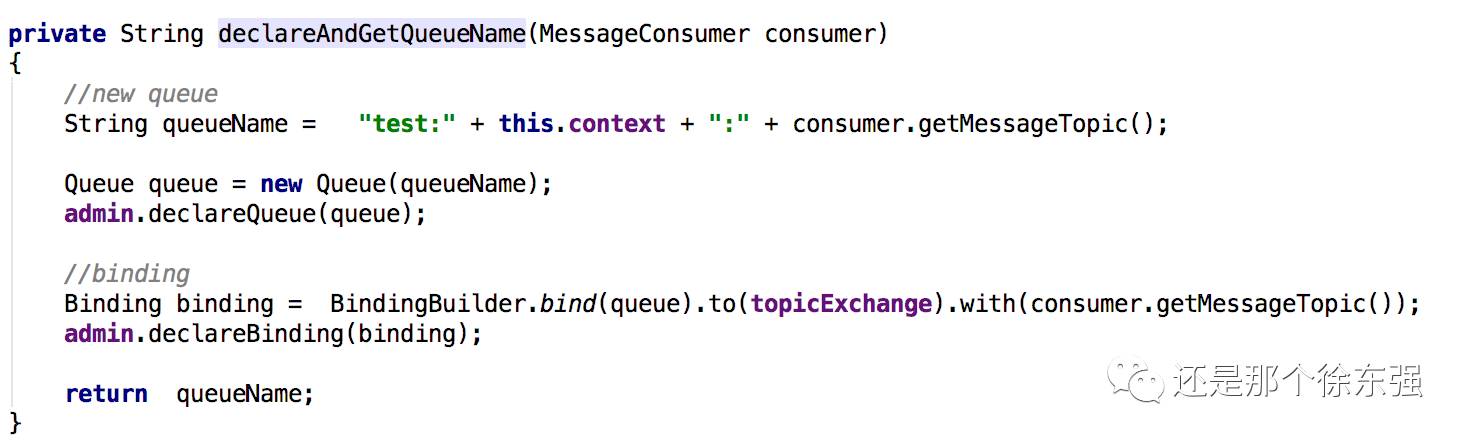
生产端,发送消息时指定的routingkey=mian.test。
消费端,queue的名称通过代码指定为test:服务B:mian.test,并且将名为amp.topic的exchange和queue通过bindingkey=mian.test绑定起来。
这样一条消息到了amp.topic会被路由到图中的queue1中,从而被服务B的消费者消费。
延迟队列
生产端:(代码如下)
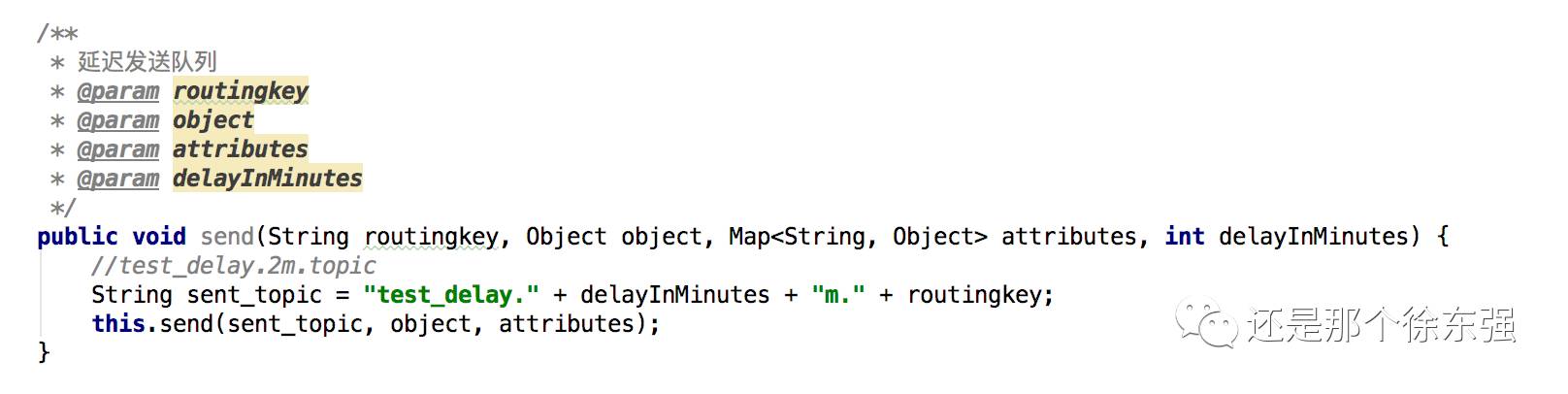
消费端:(代码如下)
1.定义DelayMessageConsumer接口,其中有三个方法,指定消息的routingkey,消息对象,延迟时间
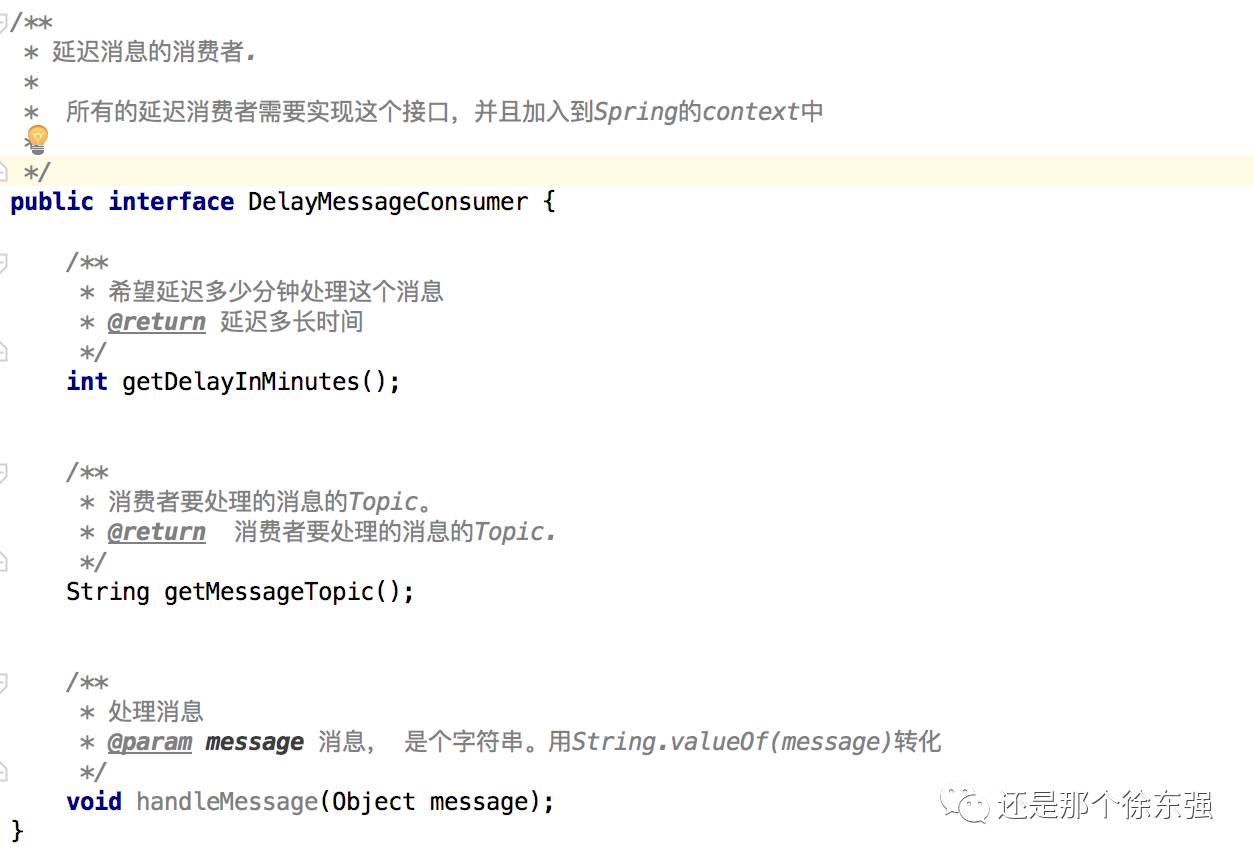
消息消费工厂类的实现
略有不同,消息监听的并非生产端exchage路由到的queue,生产端将消息路由到一个dead letter queue。
这个dead letter queue有啥特点呢?dead letter queue中的消息一旦过了指定的时间没有被消费,则成为dead letter,然后会转发到其他的exchange。
rabbitmq可以针对queue和message设置x-message-ttl来控制消息的生存时间,如果超时,则消息变成dead letter
rabbitmq的queue可以配置x-dead-letter-exchange和x-dead-letter-routing-key(可选),如果队列中出现dead letter,则按照这两个参数重新路由
x-dead-letter-exchange: 出现dead letter之后将dead letter发送到指定的exchange
x-dead-letter-routing-key: 指定routing-key发送
下面以延时2分钟,routingkey为mian.test的消息为例,画图
由上面的发送代码可以看出来,消息的routingkey=test_delay.2m.mian.test
消费者工厂类中定义了上面的两个队列并且指定了bindingkey, 消费端消息监听queue2中,当生产端一条消息到amp.topic的exchange中的时候,会被路由到queue1中,但是由于该队列没有消费者监听,所以一旦过了两分钟,该队列中的消息会成为dead letter,根据x-dead-letter-exchange会被转发到test.expire的exchang中,消息的routingkey=test_delay.2m.mian.test,根据bindingkey=test.delay.*.mian.test,消息会被路由到queue2中,从而会被服务B的消费者消费
指定被另一个云消费
之前没理解过来,同一个服务中相对于同一个routingkey,既有生产者代码,也有消费者代码,发送的消息怎么就能保证不被自己云的消费者消费掉呢。
问题的关键是rabbitmq也是双云的,如果下面的rabbitmq是同一个,那么queue就是同一个,那么消息可能被监听在其上的任意一个消费者消费掉。
但是由于rabbitmq也是双云,aws上的queue1仅仅被腾讯云上面的消费者监听着,腾讯云执行清理不同步缓存也好,执行写zk也好,自然执行的是腾讯云上的redis以及zk。
以上是关于工作中rabbitmq的使用的主要内容,如果未能解决你的问题,请参考以下文章