深度解析RabbitMQ集群——超大规模高可用OpenStack平台核心技术深入解析系列高级篇
Posted 开源云中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度解析RabbitMQ集群——超大规模高可用OpenStack平台核心技术深入解析系列高级篇相关的知识,希望对你有一定的参考价值。
编者按:
OpenStack已经在很多大型企业里支撑起核心生产业务,这都源于OpenStack中的核心技术与架构,超大规模高可用OpenStack平台核心技术深入解析系列文章,主要介绍了EasyStack在企业级OpenStack一线实践中的所见所感,将分为消息队列篇,计算篇,存储篇,网络篇等等,每篇中的内容都以基础、高级划分,将OpenStack落地最后一公里实打实所遇到的问题分享给大家。
在上一篇中,我们已经详细介绍了,接下来,我们开始进入高级篇的部分,深入介绍如何搭建RabbitMQ集群,以及在RabbitMQ集群中做插件管理、构建HA方案、如何实现通过RabbitMQ支撑高并发的大规模生产集群,本文中将深入解析RabbitMQ服务器与集群。
一、RabbitMQ 服务器
首先,RabbitMQ是基于Erlang语言编写,RabbitMQ 服务器启动后,erlang框架会启动底层的Erlang node,上层启动Erlang 应用和其它的辅助应用,此架构类似于JVM,在一个节点的应用出问题时,该节点仍继续运行,如上图所示。
如何查看RabbitMQ当前的运行状态?
在部署好的集群当中,您可以通过rabbitmqctl status可以查看到RabbitMQ的状态。
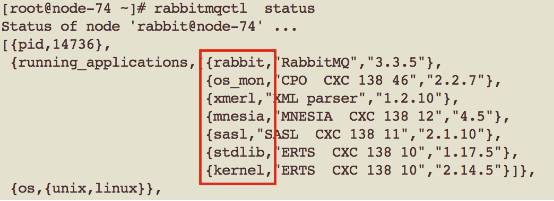
上图中,红框内为运行的应用。 Rabbit即为RabbitMQ 服务器。其余则为Erlang/OTP提供的application。
• os_mon: operating system monitor,操作系统监控
• xmerl: Functions for exporting XML data to an external format,导出XML数据到外部格式
• mnesia: a distributed DataBase Management System (DBMS), appropriate for telecommunications applications and other Erlang applications which require continuous operation and exhibit soft real-time properties. 一个分布式数据库管理系统,适合于电信应用和其他需要持续操作并展示实时信息的应用
• SASL (System Architecture Support Libraries)
• Kernel & stdlib: The Kernel application is the first application started. It is mandatory in the sense that the minimal system based on Erlang/OTP consists of Kernel and STDLIB. 是第一个启动的服务,其作为Erlang框架的核心。
注:以上Erlang/OTP的应用都可以通过 “erl –man <app>”查询它的帮助文档。
如何启动RabbitMQ服务?
RabbitMQ 服务器是通过erl启动,启动时需要进行一系列的应用参数配置:
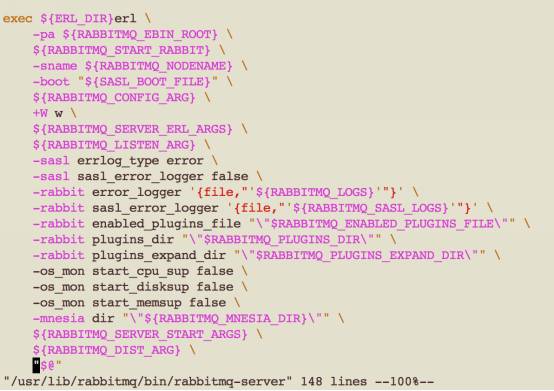
如上图所示,配置的参数包括了节点名称,配置,日志,插件等等
RabbitMQ 服务启动后,会运行哪些进程?
epmd(Erlang Port Mapper Daemon):
• Erlang Port Mapper Daemon (epmd). 当启动分布式的Erlang node时,epmd将记录IP/Port信息。 当使用rabbitmqctl join_cluster将Erlang node连接成集群时,epmd负责节点名称和IP/Port的转换。
Beam.smp:
RabbitMQ创建的众多处理消息的线程。
如何设置防火墙?
由于RabbitMQ中上述的应用都在监听不同的端口,如果rabbitmq-server所在的节点需要进行防火墙设置,则需要打开如下端口:
epmd:4369
rabbit:5672(默认值,可通过RABBITMQ_NODE_PORT更改)
rabbit management plugin: 15672
Kernel application: 41055 (在 rabbit.conf 中配置)
如何管理RabbitMQ?
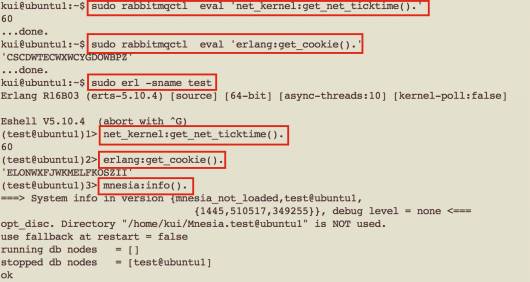
RabbitMQ提供的唯一操作工具就是rabbitmqctl。除了常规的queue/exchange/policy/user/permission等操作外,可以利用它的“eval”子命令,来扩展出很多功能。比如查询net_ticktime / erlang cookie。
如何选择RabbitMQ的消息保存方式?
RabbitMQ对于queue中的message的保存方式有两种方式:disc和ram。如果采用disc,则需要对exchange/queue/delivery mode都要设置成durable模式。Disc方式的好处是当RabbitMQ失效了,message仍然可以在重启之后恢复。而使用ram方式,RabbitMQ处理message的效率要高很多,ram和disc两种方式的效率比大概是3:1。所以如果在有其它HA手段保障的情况下,选用ram方式是可以提高消息队列的工作效率的。
如果使用ram方式,RabbitMQ能够承载的访问量则取决于可用的内存数了。RabbitMQ使用两个参数来限制使用系统的内存,避免系统被自己独占。
[{rabbit, [{vm_memory_high_watermark_paging_ratio, 0.75}, {vm_memory_high_watermark, 0.4}]}].
vm_memory_high_watermark:表示RabbitMQ使用内存的上限为系统内存的40%。也可以通过absolute参数制定具体可用的内存数。当RabbitMQ使用内存超过这个限制时,RabbitMQ 将对消息的发布者进行限流,直到内存占用回到正常值以内。
Vm_memory_high_watermark_paging_ratio:表示当RabbitMQ达到0.4*0.75=30%,系统将对queue中的内容启用paging机制,将message等内容换页到disk 中。
RabbitMQ的内存使用情况可以通过“rabbitmqctl status”或者管理插件中的Web UI查询。
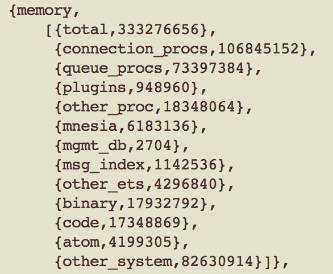
各个内存条目的含义请参照:https://www.rabbitmq.com/memory-use.html
当消息发送的速率超过了RabbitMQ的处理能力时该怎么办?
RabbitMQ会自动减慢这个连接的速率,让client端以为网络带宽变小了,发送消息的速率会受限,从而达到流控的目的。 使用”rabbitmqctl list_connections”查看连接,如果状态为“flow”,则说明这个连接处于flow-control 状态。
RabbitMQ集群
RabbitMQ基于Erlang编写,天然支持clustering。集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐能力的目的。
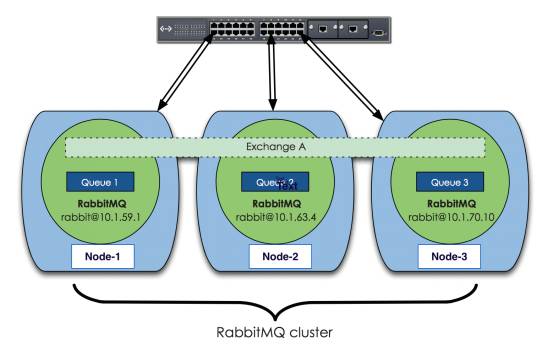
上图中是三个节点的RabbitMQ集群,Exchange A的metadata信息在所有节点上是一致的,queue的完整信息则只在它创建的那个节点上。每个RabbitMQ节点通常以“rabbit@<hostname>”表示,所以hostname在运行RabbitMQ的节点中很重要。注意:如果更改了hostname,需要重置RabbitMQ内部的数据库,否则服务无法工作。
如何构建集群?
单个rabbitmq-server启动之后,在确保Erlang cookie相同的情况下,可以通过
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@<hostname>
rabbitmqctl start_app
如果单纯做试验,也可以在一个虚拟机上启动三个RabbitMQ的实例,只要在启动时通过设置RABBITMQ_NODE_PORT让三个实例监听不同端口即可。
RabbitMQ维护着四种类型的metadata: queue/exchange/binding/vhost,在集群中这些信息被同步到每个节点,因此当用户访问任何一个节点时,通过rabbitmqctl查询到的queue/user/exchange等信息都是相同的。
通常我们将这些信息保存到磁盘上,也就是查询RabbitMQ状态时的“disc”方式,以便集群重启时可以根据保存的metadata信息重建exchange等。
对于exchange来讲,它的所有信息就是一个exchange名字加上一个查询表。查询表中记录了所有的queue binding。当message被发送到exchange时,client连接的channel对routing key进行比对,根据binding进行正确的转发。
对于Queue来讲,虽然它的metadata在每个节点上都有,但只有在它被创建的那个RabbitMQ 节点上才具有完整的信息:比如state/contents等,这个node被称为此queue的owner node。其他节点只知道这个queue的metadata信息和一个指向queue的owner node的指针。
如果一个client访问RabbitMQ的节点上没有需要的queue的完整信息,RabbitMQ将根据这个指针将请求转发到owner node。
这张图上可以看到,Exchange的所有信息被复制到集群中的所有节点,“Queue 1”的metadata被复制到每个节点,但它的完整信息(content)只存在于一个节点上,也就是这个queue的owner node。
Mnesia是RabbitMQ中的数据库,它是内嵌在Erlang中的no-SQL数据库。Exchange/Queue/Binding等的metadata信息都保存在mnesia的数据库文件中。关于RabbitMQ的集群信息也保存在这里。Rabbitmqctl的reset操作实际上就是清空了mnesia数据库所在目录的内容。
RabbitMQ集群模式
除了上面讲到的RabbitMQ 内嵌的clustering方式进行分布式的消息处理,RabbitMQ还有federation/shovel两种分布式方式,这两种方式以RabbitMQ plugin的形式存在。RabbitMQ对网络延迟很敏感,在单个数据中心中使用clustering方式。在WAN环境中,则使用Federation或Shovel。
以Shovel为例,在rabbitmq.conf中定义rabbitmq_shovel的配置,主要是对两个独立RabbitMQ 节点中,定义源和目的节点中exchange/queue的replication关系。当一个请求发送到源RabbitMQ节点时,先响应请求,之后根据replication关系,shovel会异步的将message传送到目的RabbitMQ节点进行处理。
这里对federation/shovel联邦模式跟clustering集群模式一个简单的对比。
相关链接:
第一篇:
第二篇:
参考文献:
《RabbitMQ in Action》书
RabbitMQ官方网站
Tryrabbitmq.com
以上是关于深度解析RabbitMQ集群——超大规模高可用OpenStack平台核心技术深入解析系列高级篇的主要内容,如果未能解决你的问题,请参考以下文章