这次,我选RabbitMQ
Posted 占小狼的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这次,我选RabbitMQ相关的知识,希望对你有一定的参考价值。
一般而言,如果你选择RabbitMQ,那肯定就是把可靠性放在第一位。毕竟,RabbitMQ可是金融行业消息队列的标配。如果把性能放在第一位,那毫无疑问,必须是Kafka。但是,可靠性毕竟是相对的,就拿大火的阿里云,AWS云,或者传统的IBM小型机,Oracle数据库,没有谁敢说自己可靠性100%,都是说几个9。
所以,本文的目的很明确,就是尽可能的提高我们RabbitMQ的可靠性,从发送、存储、消费、集群、监控、告警等多个维度给出可行性方案,指导开发者以及运维人员获取更加可靠的消息投递,保障我们的业务系统安全、可靠、稳定的运行。
数据可靠性是和RabbitMQ节点、生产者、消费者以及服务器等息息相关的。本文比较长,大概分为如下几个段落:
-
确认机制 -
生产者 -
消费者 -
队列镜像 -
告警 -
监控和Metrics -
健康检查
如下是一张RabbitMQ架构图,本文对可靠性的分析,会涉及到架构图中的方方面面:
1. 确认机制
当连接出现问题的时候,在客户端和服务端之间的消息可能正在投递中,还没有被Broker接收,它们可能正在被编码或者解码,或者一些其他的情况。在这种场景下,消息并没有被投递,那么它们是需要被重新投递以保障业务稳定性。确认机制让服务端和客户端知道什么时候需要做这些事情,它对于生产者和消费者保障数据安全是非常重要的。
确认机制能被用在两个方向:允许消费者告诉服务器(Broker)它已经收到了消息,也允许服务器告诉生产者它接收到了消息。前者就是我们常说的消费者Ack,后者就是我们常说的生产者Confirm。
1.1 生产者/消费者确认
生产者确认以及消费者确认接下来会单独的段落进行详细的介绍,并且有示例代码,这里就不过多的讲解了。
1.2 确认机制总结
确认机制的使用,能够保证最少一次(at least once)投递。如果没有确认机制,消息就非常可能会丢失,这时候只能保证最多一次(at most once )。至于恰好一次投递,目前还没有哪个中间件可以保证,毕竟分布式系统非常复杂,尤其是网络的不可控,不确定的因素太多太多。
2. 生产者
当使用确认机制的时候,生产者从连接或者channel故障中恢复过来时,会重发没有被Broker确认签收的消息。如此一来,消息就可能被重复发送,因为可能是由于网络故障等原因,Broker发送了确认,但是生产者没有收到而已。亦或者,消息压根就没有发送到Broker那里去。正因为生产者为了可靠性可能会重发消息,所以在消费者消费消息处理业务时,还需要去重,或者对接受到的消息做幂等处理(推荐幂等处理)。
生产者增加确认机制非常简单,channel开启confirm模式,然后增加监听即可:
// 选择确认机制
channel.confirmSelect();
// 确认消息监听
channel.addConfirmListener(new ConfirmListener() {
@Override
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
System.out.println("消息已经ack,tag: " + deliveryTag);
}
@Override
public void handleNack(long deliveryTag, boolean multiple) throws IOException {
// 对于消费者没有ack的消息,可以做一些特殊处理
System.out.println("消息被拒签,tag: " + deliveryTag);
}
});
说明:RabbitMQ还有事务机制(txSelect、txCommit、txRollback),也能保障消息的发送。不过事务机制是**「同步阻塞」的,所以不推荐使用。而confirm模式是「异步」**机制。如下图所示(图片摘自《Rabbit实战指南》,皮皮厮的书籍,非常值得一看),是事务机制以及confirm方式TPS性能对比,我们可以很明显的看到,事务机制是性能最差的: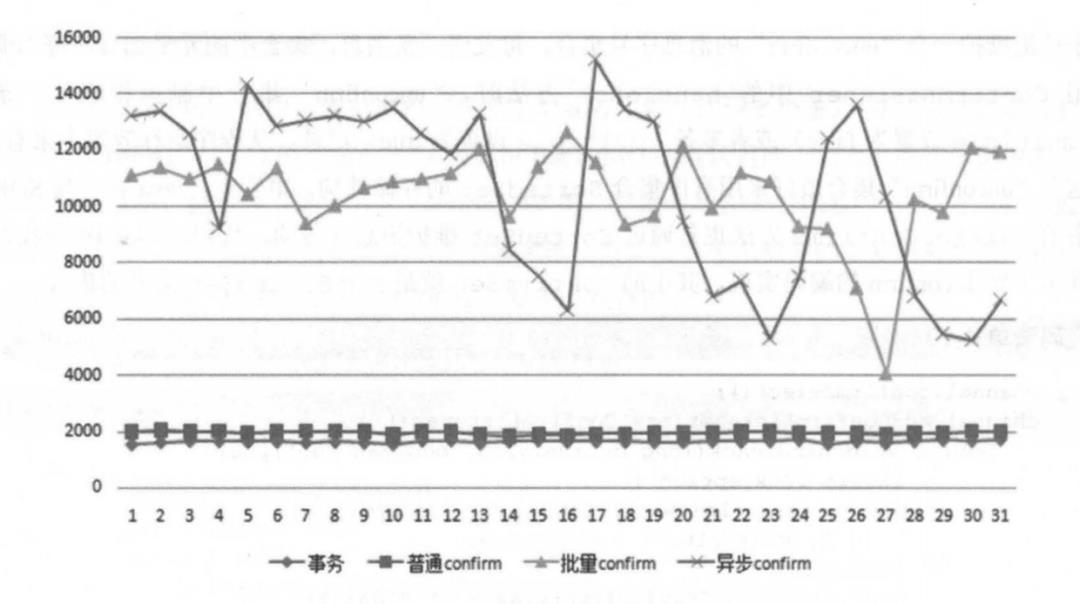
在一些很重要的业务场景,我们还需要确保消息被正确路由到了队列。为了确保消息被正确路由到一个已知的队列,我们需要确保消息被正确的从交换器传递到了队列中,并且还需要确保目标队列至少有一个消费者。我们试想,如果一个队列都没有任何消费者,那发送的消息相当于石沉大海了。
前者,我们可以通过给交换器绑定一个备份交换器解决这个问题。比如一个direct类型的交换器,如果发送消息时路由KEY不匹配,那么这条消息就会进入备份交换器中,而不会被丢失:
Map<String, Object> argsMap = new HashMap<>();
argsMap.put("alternate-exchange", ALTER_EXCHANGE_NAME);
// map参数中alternate-exchange的值,就是申明绑定的备份交换器名称
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT, true, false, argsMap);
❝
RabbitMQ支持的4种交换器类型中,只有fanout是不存在路由不到队列的情况,因为它会自动路由到所有队列中,跟绑定KEY没有任何关系。所以,在满足你业务的前提下,笔者建议,尽可能使用fanout类型交换器。
❞
后者,我们可以通过死信交换器(DLX,也被称为私信队列)来解决这个问题,假设一些消息没有被消费,那么它就会被转移到绑定的死信交换器上,对于这类消息,我们消费并处理死信队列即可:
Map<String, Object> argsMap = new HashMap<>();
// 死信交换器/死信队列
argsMap.put("x-dead-letter-exchange", DLX_EXCHANGE_NAME);
// 设置队列过期时间(第一次设置一个值后,以后不能设置一个更大的值)
argsMap.put("x-message-ttl", 60000);
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT, true);
// 死信的关系一定要在queue申明时指定,而不能在exchange申明时指定
channel.queueDeclare(QUEUE_NAME, true, false, false, argsMap);
3. 消费者
只有消费者确认的消息,RabbitMQ才会删除它,不确认就不会被删除。所以,在消费端,建议关闭自动确认机制。应该在收到消息处理完业务以后,手动确认消息。消费者手动确认实现代码如下:
DefaultConsumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties props, byte[] body){
System.out.println("死信队列接受到的消息:" + new String(body));
// 手动确认消息接受成功
channel.basicAck(envelope.getDeliveryTag(), false);
// channel.basicNack(envelope.getDeliveryTag(), false, false);
}
};
// 推模式,并且关闭自动确认机制,即autoAck=false
channel.basicConsume(QUEUE_NAME, false, consumer);
注意上面的basicAck方法:void basicAck(long deliveryTag, boolean multiple) 第二个参数multiple。要说明这个参数的含义,首先需要讲清楚一个概念**「deliveryTag」,即投递消息唯一标识符,它是一个「单调递增」**的Long类型正整数。假设此次basicAck的tag为123130,如果multiple=false,那么表示只确认签收这一条消息。如果multiple=true,那么表示确认签收tag小于或等于123130的所有消息。
❝
「最大Tag值」:Delivery tag是一个64位长整型值,也就是说它的最大值是9223372036854775807(2^64-1),不过这个tag值是按channel划分的。也就是说,理论上每一个channel都可以发送2^64-1条消息。因此,我们认为在实际情况中,tag基本上不可能达到它的上限值。
❞
前面提到,由于网络等一些原因引起了故障,就会导致消息被重发。因此,消费端一定要做好处理重复消息的准备,强烈建议在消费端实现**「幂等」的业务逻辑。比如以支付送积分为例,那么,消息体中肯定有订单号这个业务属性唯一的ID。那么在消费这个消息送积分的业务代码中,需要根据这个订单号做幂等处理,即「同一个订单号只能送一次积分」**。
在消费端还有一种情况,就是当前消费者认为它不能处理当前消息。因此,它就拒绝签收(basic.reject或者basic.nack)这个消息。那么生产者也需要监听这些消息并做特殊的业务处理。
RabbitMQ中消费者有3种签收消息方式:1、channel.basicAck(long deliveryTag, boolean multiple):确认签收消息;2、channel.basicNack(long deliveryTag, boolean multiple, boolean requeue):不确认签收消息,并设置是否重入队列中,并且可以批量不确定签收tag之前的所有还未ack的消息;3、channel.basicReject(long deliveryTag, boolean requeue):直接拒绝签收这一条消息,并设置是否重入队列中。
4. 队列镜像
为了防止在Broker中丢失消息,交换器、队列和消息都应该设置为持久化。除此以外,队列和消息还应该被复制,为了应对操作系统未及时fsync刷盘、Broker重启、Broker服务器硬件故障、或者Broker crash故障等问题。
集群节点提供了冗余能力,能容忍单节点故障。在RabbitMQ集群中,所有的定义都可以被复制,例如交换器、绑定关系、用户等。但是队列有所不同,默认只存在一个节点上(这一点和kafka很不一样,kafka的Topic可以设置多个副本)。不过,可以通过配置把队列**「镜像」**到多个节点上,从而让队列不会有单点故障的问题:
当节点发生故障时,如果这时候有镜像队列,还会自动发生新的选举,就能选举出新的Master。从而不会因为某个节点故障而导致队列不可用,而且整个过程对业务完全无感知。
不过需要注意的是,镜像并不能保证所有队列的高可用,「排他性队列」(Exclusive Queues)就不行。因为排他性队列生命周期与它的连接绑定在一起,当Broker节点发生故障重启后,排他性队列是会自动删除的,因此不能被镜像(Mirrored)!
5. 告警
这里我们主要说一下磁盘告警以及内存告警。因为出现下面两种情况时,RabbitMQ会停止从客户端网络socket中读数据: 1、内存使用达到配置上限;2、磁盘使用达到配置上限;
内存使用上限有3种设置方式:
## 设置节点可使用RAM百分比,超过这个百分比就会告警
vm_memory_high_watermark.relative = 0.4
## 设置节点可使用RAM的上限,单位为byte即字节
vm_memory_high_watermark.absolute = 1073741824
## RabbitMQ 3.6.0+,设置节点可使用RAM的绝对大小,它的优先级低于relative
vm_memory_high_watermark.absolute = 2GB
磁盘使用上限也有3种设置方式:
## 设置磁盘剩余空间阈值,当可用空间低于这个值就会触发告警
disk_free_limit.absolute = 51200
## with RabbitMQ 3.6.0+.
disk_free_limit.absolute = 500KB
disk_free_limit.absolute = 50MB
disk_free_limit.absolute = 5GB
## 设置磁盘剩余空间为有效RAM的多少倍,比如当前可用RAM为2G,且设定这个参数为2。那么当磁盘可用空间低于2*2=4G时就会触发告警
disk_free_limit.relative = 2.0
❝
由上可知:开启磁盘告警以及内存告警非常简单,需要说明的是,设置绝对值大小时,MB和M是不一样的,M即MiB表示 mebibytes (2^20 ,1,048,576 bytes),而MB表示 megabytes (10^6 ,1,000,000 bytes)。
❞
只要满足这两种情况其中的一种情况,服务器就会临时阻塞连接,并且连接心跳也会断开。这时候我们通过rabbitmqctl或者RabbitMQ管理后台查看,所有网络连接都是**「blocking」**。如果我们是RabbitMQ集群,那么内存和磁盘告警就会影响整个集群。只要其中一个节点内存或者磁盘达到上限,整个集群的所有节点都会阻塞连接。
一些客户端包是支持连接阻塞提醒的,如果你使用的客户端包恰好也支持,建议基于此增加监控告警。此外,运维需要针对RabbitMQ集群服务器增加内存和磁盘使用率告警。假设RabbitMQ磁盘告警是只剩10%,那么运维设置的告警应该要大于10%,比如15%,从而能够提前发现隐患,提前介入处理问题,避免磁盘使用达到上限而引起线上问题,背个P0故障可不好看。
6. 监控和Metrics
生产环境我们应该有完善且合理的监控机制,从而做到防患于未然。监控能在问题还未暴露出来时,就能提前发现问题。监控最重要的事情就是对Metrics的采集和分析。我们把Metrics分为两大类:「RabbitMQ的Metrics」和「基础设施的Metrics」。
6.1 基础设施的Metrics
这块的监控,我们需要收集运行RabbitMQ节点的所有服务器,以及应用的一些metrics,包括但不限于:
-
CPU统计情况; -
内存使用率; -
虚拟内存统计; -
RabbitMQ节点数据目录下磁盘剩余可用空间; -
磁盘IO情况; -
网络吞吐量(接收量、发送量、最大网络吞吐量等); -
网络延迟情况(RabbitMQ集群所有节点以及客户端之间的网络延迟); -
文件描述符;
对基础设施以及系统内核Metrics的监控工具非常多,而且都很成熟。比如:Prometheus、Datadog、Zabbix等。它们都能很好的收集Metrics信息,然后存储并可视化展示,并且可以自定义告警规则。
6.2 RabbitMQ的Metrics
接下来我们说一下对RabbitMQ集群本身的监控。RabbitMQ的管理后台UI暴露了节点很多metrcis信息,并且RabbitMQ还通过HTTP API把这些信息暴露出来方便我们二次开发,自定义监控系统就非常依赖它的HTTP API。HTTP API访问参考:curl -i -u root:root123 'http://localhost:15672/api/overview'。
我们先说RabbitMQ管理后台,这个后台做的还是很不错的。但是如果用于监控的话,就显得有些不足了:
-
强依赖被监控的系统(应该要解耦被监控的系统和监控系统); -
只存储最近一天的数据(超过一天的数据就没有了); -
用户接口不够强大; -
它的权限系统是依赖RabbitMQ权限系统的;
可喜的是,RabbitMQ从3.8版本开始,已经支持Prometheus和Grafana了,也推荐应用在生产环境上。接下来说一下RabbitMQ监控系统需要关注RabbitMQ的哪些metrics。
6.2.1 集群Metrics
我们可以通过 'http://localhost:15672/api/overview' 得到RabbitMQ集群相关信息,。结果(部分字段)如下:
{
... ...
"message_stats": {
"ack": 212,
"ack_details": {
"rate": 0.0
},
"confirm": 143,
"confirm_details": {
"rate": 0.0
},
"publish": 323,
... ...
},
"queue_totals": {
"messages": 197,
"messages_details": {
"rate": 0.0
},
...
},
"object_totals": {
"channels": 2,
"connections": 2,
"consumers": 1,
"exchanges": 24,
"queues": 10
},
... ...
}
这里我们需要关注的一些主要指标有:
-
message_stats.ack:消费者确认接受消息的数量; -
message_stats.confirm:生产者得到Broker已经确认的消息(ConfirmListener中的handleAck); -
message_stats.publish:最近发布的消息总量(它只有最近的数据,没有RabbitMQ集群整个生命周期的数据。前面两个指标ack和confirm一样,也都是最近的数据。如果RabbitMQ闲置一段时间,这几个值都会归零); -
object_totals.channels:channel数量,等价于RabbitMQ管理后台**「Channels」**页面中交换器数量; -
object_totals.connections:连接数量,等价于RabbitMQ管理后台**「Connections」**页面中交换器数量; -
object_totals.consumers:消费者数量; -
object_totals.exchanges:交换器数量,等价于RabbitMQ管理后台**「Exchanges」**页面中交换器数量; -
object_totals.queues:队列数量,等价于RabbitMQ管理后台**「Queues」**页面中队列数量;
说明:object_totals这个节点下几个字段的值,我们也可以在RabbitMQ管理后台**「Overview」页面的「Global counts」**中得到,如下图所示: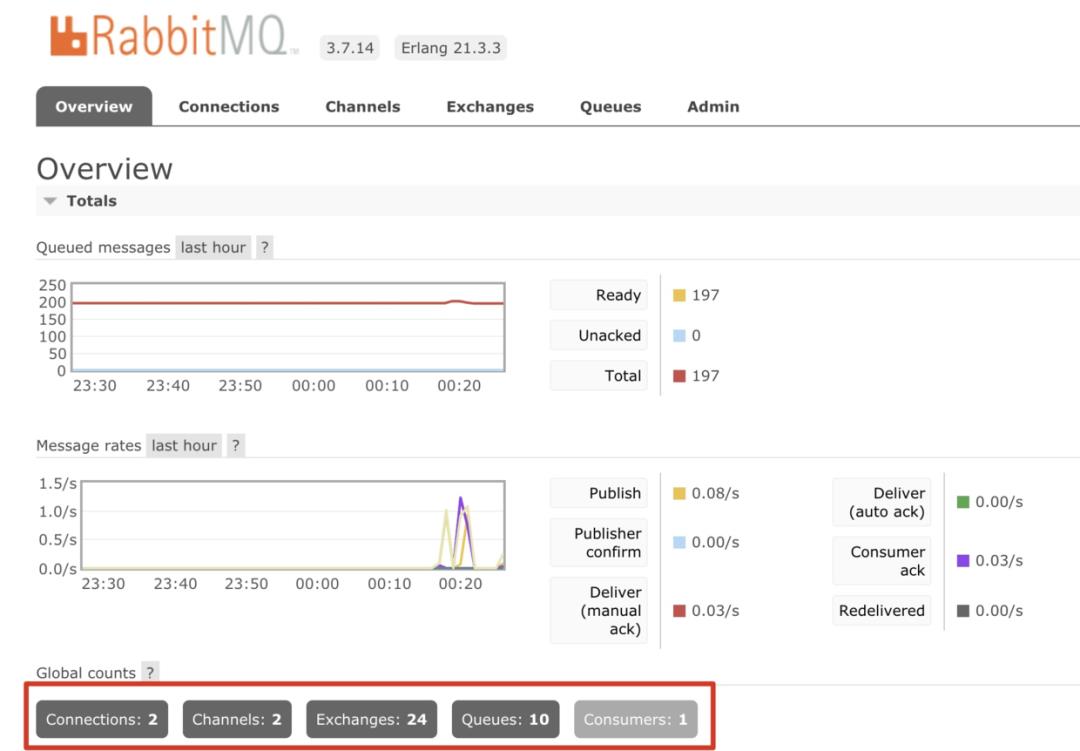
6.2.2. 节点Metrics
首先,我们通过 'http://localhost:15672/api/nodes/' 可以获取到RabbitMQ集群中所有节点的详细信息,它返回的是一个JSON数组。也可以通过 'http://localhost:15672/api/nodes/{nodeName}' 获取某个节点信息(这里的nodeName就是第一个URL结果中字段name的值,例如:"name": "rabbit@afeideMacBook-Pro"),所以这个URL返回的是一个JSON对象。结果(部分字段)如下:
{
"partitions": [],
"os_pid": "36637",
"fd_total": 4864,
"sockets_total": 4285,
"mem_limit": 3435973836,
"mem_alarm": false,
"disk_free_limit": 50000000,
"disk_free_alarm": false,
"proc_total": 1048576,
"rates_mode": "basic",
"uptime": 115368753,
"run_queue": 1,
"processors": 4,
... ...
}
这里我们需要关注的一些主要指标有:
-
mem_used:已经使用的内存; -
mem_limit:限制最大允许使用的内存; -
mem_alarm:bool类型值,是否开启了内存告警; -
disk_free_limit:磁盘还剩下多少空间告警阈值,也就是说当磁盘可用空间小于这个值时就会告警; -
disk_free_alarm:bool类型值,是否开启了磁盘告警; -
fd_total:总计可用文件描述符数量; -
fd_used:已经使用的文件描述符数量; -
sockets_total:总计可用sockets数量; -
sockets_used:已经使用sockets数量;
6.2.3 队列Metrics
队列的metrics都可以通过'http://localhost:15672/api/queues/afei/queue-normal-afei'获取。得到的json结果如下:
{
"consumer_details": [],
"arguments": {
"x-dead-letter-exchange": "exchange-dlx-afei",
"x-message-ttl": 3000
},
"auto_delete": false,
... ...
"idle_since": "2020-05-05 7:45:58",
"incoming": [],
"memory": 19900,
"message_bytes": 0,
... ...
"state": "running",
"vhost": "/afei"
}
我们需要关注的一些主要指标有:
-
memory:使用的内存; -
messages:未被确认的消息总数 + 准备投递的消息总数; -
messages_ready:准备投递的消息总数; -
messages_unacknowledged:未被确认的消息总数; -
state:当前队列的状态,running状态表示正常; -
idle_since:表示当前队列有多久没有被消费者消费了,如果这个时间相比当前时间是很久以前,很有可能说明当前队列没有生产者已经废弃。
6.2.4 应用Metrics
现在大部分系统都是分布式的,在这样的系统中,当某个组件出问题时,通常很难立即定位问题。所以,系统的每个部分,包括应用本身,都应该被监控起来。
一些基础设施级别和RabbitMQ的Metrics能看出系统当前有异常行为和问题,但是,还不能定位根据原因。例如,通过监控我们很容易知道某个节点磁盘空间不足,但是很难麻烦就知道为什么不足。所以,我们需要应用Metris信息来协助我们排查这样的问题:区分哪个消息生产者速度异常、哪个消息者出现重复性的失败、消费者速度赶不上消息产生的速度等。
应用程序跟踪的Metrics可能是特定系统的,但是也有一些Metrics与大多数系统都是有关联的,例如:Connection opening rate、Channel opening rate、Connection failure (recovery) rate、Publishing rate、Delivery rate、Positive delivery acknowledgement rate、Negative delivery acknowledgement rate、Mean/95th percentile delivery processing latency... ...
7. 健康检查
下面推荐一些RabbitMQ监控检查的命令:
-
rabbitmq-diagnostics -q ping:如果节点没有任何问题,那么返回Ping succeeded。 -
rabbitmq-diagnostics -q status:会显示当前RabbitMQ节点即broker的很多信息,例如内存信息、磁盘信息、虚拟内存信息、告警信息、文件描述符等。 -
rabbitmq-diagnostics -q alarms:该命令可以检查RabbitMQ本地以及集群节点是否有告警信息,如果没有,那么返回这样的信息:Node rabbit@afeideMacBook-Pro reported no alarms, local or clusterwide;
说明:**「rabbitmq-diagnostics」**这个命令还有很多其他的用法,我们可以通过rabbitmq-diagnostics --help查看它还能监控和检查哪些Metrics。
最后推荐一些第三方监控工具,如下表格所示,按照字母排序,排名不分先后。这些工具能力上各有千秋,不过一般都是既能收集基础设施级别的Metrics,也能收集RabbitMQ的Metrics。当然,笔者能力有限,可能还有其他一些好用的工具并没有列举出来:
以上是关于这次,我选RabbitMQ的主要内容,如果未能解决你的问题,请参考以下文章