mobilenetv3怎么部署到嵌入式系统上
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mobilenetv3怎么部署到嵌入式系统上相关的知识,希望对你有一定的参考价值。
参考技术A 1. 实现MobilenetV3_ssd网络2. 在大型数据集上进行预训练
3. 制作自己的数据集并训练
4. 剪枝
5. 部署 参考技术B 为了追求更高的准确率,自从AlexNet以来,神经网络更加倾向于更深、更复杂的设计结构,这就导致对GPU的需求提高,在现实生活中很难达到,因为在实际生活中,识别任务更需要是在有限的计算环境下实时计算(基本都是在移动端)。
因此,谷歌团队在2017年提出了专注于移动端或嵌入式设备中的轻量级神经网络-MobileNet,到如今已发展了三个版本。
1
MobileNet_V1
MobileNet的基本单元是深度可分离卷积,它是将标准卷积拆解为深度卷积(depthwise convolution) 和逐点卷积(pointwise convolution)。
标准卷积的卷积核是作用在所有输入通道上,而深度卷积是针对每个输入通道采用不同的卷积核,即一个卷积核对应一个通道,而点卷积其实就是普通的卷积,只不过是采用1x1的卷积核, 如图1所示,下面对比一下各自的计算量。

(a) 标准卷积

(b) 深度卷积

(c) 点卷积
图1 标准卷积与深度可分离卷积计算对比
令输入尺寸为DFxDFxM,标准卷积核的尺寸为DKxDKxMxN,若采用标准卷积进行操作,步长为1且存在padding,则计算量为DKxDKxMxNxDFxDF。
采用深度卷积的方式进行卷积,先使用 M个深度卷积核对输入的M个通道分别进行卷积得到的尺寸为 DF x DF x M,这一步的计算量为 DK x DK x M x DF x DF;
再使用N个 1 x 1 x M的卷积核进行逐点卷积得到输出尺寸为 DF x DF x M x N,这一步的计算量为 M x N x DF x DF;故总的计算量为 DK x DK x M x DF x DF + M x N x DF x DF。所以深度可分离卷积与标准卷积相比得:

一般情况下,N取值较大,若采用常用的3x3卷积核,则深度可分离卷积的计算量则是标准卷积的九分之一。
在实际使用深度可分离卷积时,会添加BN层和RELU层(RELU6),其对比结果如图2所示。

(a)带RELU的标准卷积 (b)带BN和RELU的深度可分离卷积
图2 标准卷积与深度可分离卷积机构对比
最终MobileNet_V1的网络结构如图3所示。一共是28层(不包括平均池化层和全连接层,且把深度卷积和逐点卷积分开算),除了第一层采用的是标准卷积核之外,剩下的都是深度可分离卷积层。

图3 MobileNet_V1网络结构
虽然MobileNet_V1的延迟已经比较小了,但更多时候在特定应用下需要更小更快的模型,因此引入了宽度因子,作用是在每层均匀地稀疏网络,为每层通道乘以一定的比例,从而减少各层的通道数,常用值有1、0.75、0.5、0.25。
引入的第二个超参数是分辨率因子,用于控制输入和内部层表示,即控制输入的分辨率,常在(0,1]之间。
值得注意的是,计算量量减少程度与未使用宽度因子之前提高了1/(**2 xρx ρ)倍,参数量没有影响。最终实验结果证明在尺寸、计算量和速度上比许多先进模型都要优秀。
2
MobileNet_V2
MobileNet_V2发表于2018年,是在MobileNet_V1的基础上引入了倒置残差连接和线性瓶颈模块。
残差结构是先用1× 1的卷积实现降维,然后通过3 × 3卷积,最后用 1 × 1 卷积实现升维,即两头大中间小。在MobileNet_V2 中,则是将降维和升维的顺序进行了调换,且中间为3 × 3 深度可分离卷积,即两头小中间大。对比图如图4所示。

(a)残差结构 (b)倒置残差结构
图4 残差与倒置残差结构对比图
那为什么会先升维再降维呢?这是因为倒置残差结构包含深度可分离卷积外,还使用了Expansion layer和 Projection layer。先通过1 × 1 卷积的Expansion layer将低维空间映射到高维空间,之后在用深度可分离卷积来提取特征,然后使用1 × 1卷积的Projection layer把高维特征映射到低维空间进行压缩数据,让网络从新变小。
这里的Expansion layer 和 Projection layer 都是有可以学习的参数,所以整个网络结构可以学习到如何更好的扩展数据和重新压缩数据。
还有一个是线性瓶颈块(linear bottleneck),这是由于当输入一个二维矩阵时,采用不同的矩阵T把它进行升维到更高的维度上,使用激活函数ReLU, 然后再使用T 的逆矩阵对其进行还原。
结果发现,当T的维度为2或者3时,还原回来的特征矩阵会丢失很多信息,但随着维度的增加,丢失的信息越来越少。
可见,ReLU 激活函数对低维特征信息会造成大量损失,所以在倒置残差块最后输出低维特征的激活函数是线性激活函数,同时实验证明,使用 linear bottleneck 可以防止非线性破坏太多信息。整体网络结构如图5所示。

图5 MobileNet_V2网络结构
图5中t表示1 × 1卷积的升维倍率,c是输出特征矩阵的通道数,n表示倒置残差块结构重复的次数,s表示步距。最终实验表明,参数量仅为3.4M,CPU上预测一张图不到0.1秒,几乎是实时!
3
MobileNet_V3
MobileNet_V3发布于2019年,依旧结合了V1的深度可分离卷积、V2的倒置残差和线性瓶颈层,同时采用了注意力机制,利用神经结构搜索进行网络的配置和参数。
V3分为两个版本,分别为MobileNet_V3 Large和MobileNet_V3 Small,分别适用于对资源不同要求的情况。
首先对于模型结构的探索和优化来说,网络搜索是强大的工具。研究人员首先使用了神经网络搜索功能来构建全局的网络结构,随后利用了NetAdapt算法来对每层的核数量进行优化。
对于全局的网络结构搜索,研究人员使用了与Mnasnet中相同的,基于RNN的控制器和分级的搜索空间,并针对特定的硬件平台进行精度-延时平衡优化,在目标延时(~80ms)范围内进行搜索。
随后利用NetAdapt方法来对每一层按照序列的方式进行调优。在尽量优化模型延时的同时保持精度,减小扩充层和每一层中瓶颈的大小。
其次在MobileNet_V3引入了压缩-激励(Squeeze-and-Excitation, SE)注意力结构,如图所示。SE结构通过学习来自动获取到每个特征通道的重要程度,然后依照这一结果去提升有用的特征并抑制对当前任务用处不大的特征。
将SE结构加入核心结构中,作为搜索空间的一部分,得到了更稳定的结构。虽然SE结构会消耗一定的时间,但作者将expansion layer的通道数变为原来的1/4,这样即提高了精度也没有增加时间消耗。

图5 添加SE注意力的倒置残差块
对于尾部结构,原先的V2在平均池化之前存在一个1x1的卷积层,目的是提高特征图的维度,但这带来了一定的计算量,但在V3中,作者为了降低计算量,池化后再接上1x1卷积,同时去掉了原中间3x3和1x1卷积,最终发现精度并没有损失,时间降低了大约15ms。
最后对于激活函数的改进,作者发现swish激活函数能够有效提高网络的精度,但swish的计算量太大了,因此提出h-swish激活函数:

这种非线性在保持精度的情况下带了了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。这一非线性改变将模型的延时增加了15%。
但它带来的网络效应对于精度和延时具有正向促进,剩下的开销可以通过融合非线性与先前层来消除。
最终MobileNet_V3结构如图6所示。
(a) MobileNet_V3 Large (b) MobileNet_V3 Small
图6 MobileNet_V3网络结构
图6中exp size表示倒置残差结构的通道数,out表示输入到线性瓶颈时特征层的通道数。SE表示是否引入注意力机制,NL表示激活函数种类(HS表示h-swish,RE表示RELU),s表示步长。
最终实验结果表明MobileNetV3-Large在ImageNet分类上的准确度与MobileNetV2相比提高了3.2%,同时延迟降低了15%。
4
参考文献
[1] Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861, 2017.
[2] Sandler M, Howard A, Zhu M, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
[3] Howard A, Sandler M, Chen B, et al. Searching for MobileNetV3[C]// 2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2020.
[4] https://zhuanlan.zhihu.com/p/58554116
关注我们,领取10+大礼包~

深蓝前沿教育
深蓝学院是专注于前沿科技的在线教育平台,为广大在校大学生、IT从业者、科研人员提供系统的前沿科技教育和咨询等服务。深蓝学院关注人工智能、机器人、增强现实等黑科技。
8篇原创内容
公众号
阅读至此了,分享、点赞、在看三选一吧
赞
22个金币已到账
金币可兑换现金
立即提现
赶快来领取你的小家电专属优惠吧!

京东商城
打开京东
广告
郭明錤爆料:苹果iPhone 15 Pro将取消实体键
PChome电脑之家
图像分类实战:mobilenetv2从训练到TensorRT部署(pytorch)
文章目录
摘要
本例提取了植物幼苗数据集中的部分数据做数据集,数据集共有12种类别,演示如何使用pytorch版本的mobilenetv2图像分类模型实现分类任务。将训练的模型转为onnx,实现onnx的推理,然后再将onnx转为TensorRT,并实现推理。
通过本文你和学到:
1、如何从torchvision.models调用mobilenetv2模型?
2、如何自定义数据集加载方式?
3、如何使用Cutout数据增强?
4、如何使用Mixup数据增强。
5、如何实现训练和验证。
6、如何使用余弦退火调整学习率。
7、如何载入训练的模型进行预测。
8、pytorch转onnx,并实现onnx推理。
9、onnx转TensorRT,并实现TensorRT的推理。
希望通过这篇文章,能让大家对图像的分类和模型的部署有个清晰的认识。
mobilenetv2简介
mobileNetV2是对mobileNetV1的改进,是一种轻量级的神经网络。mobileNetV2保留了V1版本的深度可分离卷积,增加了线性瓶颈(Linear Bottleneck)和倒残差(Inverted Residual)。
MobileNetV2的模型如下图所示,其中t为瓶颈层内部升维的倍数,c为特征的维数,n为该瓶颈层重复的次数,s为瓶颈层第一个conv的步幅。
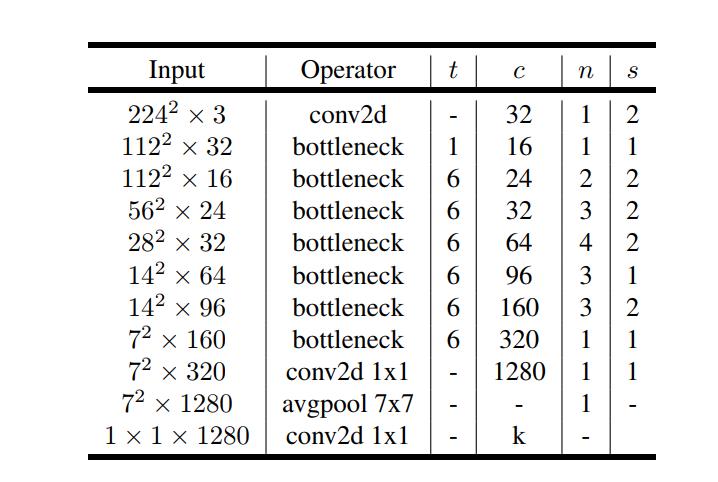
除第一层外,整个网络中使用恒定的扩展率。 在实验中,发现在 5 到 10 之间的扩展率会导致几乎相同的性能曲线,较小的网络在扩展率稍低的情况下效果更好,而较大的网络在扩展率较大的情况下性能稍好。
MobileNetV2主要使用 6 的扩展因子应用于输入张量的大小。 例如,对于采用 64 通道输入张量并产生具有 128 通道的张量的瓶颈层,则中间扩展层为 64×6 = 384 通道。
线性瓶颈
对于mobileNetV1的深度可分离卷积而言, 宽度乘数压缩后的M维空间后会通过一个非线性变换ReLU,根据ReLU的性质,输入特征若为负数,该通道的特征会被清零,本来特征已经经过压缩,这会进一步损失特征信息;若输入特征是正数,经过激活层输出特征是还原始的输入值,则相当于线性变换。
瓶颈层的具体结构如下表所示。输入通过1的conv+ReLU层将维度从k维增加到tk维,之后通过3×3conv+ReLU可分离卷积对图像进行降采样(stride>1时),此时特征维度已经为tk维度,最后通过1*1conv(无ReLU)进行降维,维度从tk降低到k维。

倒残差
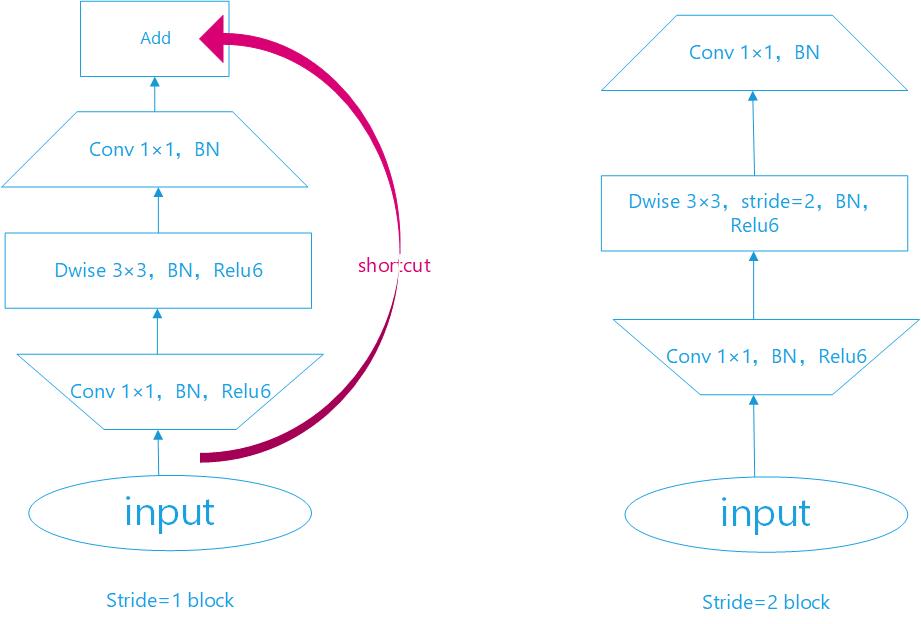
残差块已经在ResNet中得到证明,有助于提高精度构建更深的网络,所以mobileNetV2也引入了类似的块。经典的残差块(residual block)的过程是:1x1(降维)–>3x3(卷积)–>1x1(升维), 但深度卷积层(Depthwise convolution layer)提取特征限制于输入特征维度,若采用残差块,先经过1x1的逐点卷积(Pointwise convolution)操作先将输入特征图压缩,再经过深度卷积后,提取的特征会更少。所以mobileNetV2是先经过1x1的逐点卷积操作将特征图的通道进行扩张,丰富特征数量,进而提高精度。这一过程刚好和残差块的顺序颠倒,这也就是倒残差的由来:1x1(升维)–>3x3(dw conv+relu)–>1x1(降维+线性变换)。
结合上面对线性瓶颈和倒残差的理解,我绘制了Block的结构图。如下图:
ONNX
ONNX,全称:Open Neural Network Exchange(ONNX,开放神经网络交换),是一个用于表示深度学习模型的标准,可使模型在不同框架之间进行转移。
ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存储模型数据并交互。 ONNX的规范及代码主要由微软,亚马逊 ,Facebook 和 IBM 等公司共同开发,以开放源代码的方式托管在Github上。目前官方支持加载ONNX模型并进行推理的深度学习框架有: Caffe2, PyTorch, MXNet,ML.NET,TensorRT 和 Microsoft CNTK,并且 TensorFlow 也非官方的支持ONNX。—维基百科
onnx模型可以看作是模型转化之间的中间模型,同时也是支持做推理的。一般来说,onnx的推理速度要比pytorch快上一倍。
TensorRT
TensorRT是英伟达推出的一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
TensorRT 是一个C++库,从 TensorRT 3 开始提供C++ API和Python API,主要用来针对 NVIDIA GPU进行 高性能推理(Inference)加速。
项目结构
MobileNetV2_demo
├─data
│ ├─test
│ └─train
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
├─dataset
│ └─dataset.py
├─train.py
├─test_torch.py
├─torch2onnx.py
├─test_onnx.py
├─onnx2trt.py
└─test_trt.py
训练
数据增强Cutout和Mixup
为了提高成绩我在代码中加入Cutout和Mixup这两种增强方式。实现这两种增强需要安装torchtoolbox。安装命令:
pip install torchtoolbox
Cutout实现,在transforms中。
from torchtoolbox.transform import Cutout
# 数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
Cutout(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
Mixup实现,在train方法中。需要导入包:from torchtoolbox.tools import mixup_data, mixup_criterion
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)
data, labels_a, labels_b, lam = mixup_data(data, target, alpha)
optimizer.zero_grad()
output = model(data)
loss = mixup_criterion(criterion, output, labels_a, labels_b, lam)
loss.backward()
optimizer.step()
print_loss = loss.data.item()
导入包
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from dataset.dataset import SeedlingData
from torch.autograd import Variable
from torchvision.models import mobilenet_v2
from torchtoolbox.tools import mixup_data, mixup_criterion
from torchtoolbox.transform import Cutout
设置全局参数
设置学习率、BatchSize、epoch等参数,判断环境中是否存在GPU,如果没有则使用CPU。建议使用GPU,CPU太慢了。由于mobilenetv2模型很小,4G显存的GPU就可以设置BatchSize为16。
# 设置全局参数
modellr = 1e-4
BATCH_SIZE = 16
EPOCHS = 300
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
图像预处理与增强
数据处理比较简单,加入了Cutout、做了Resize和归一化。对于Normalize和std的值,这个一般是通用的设置,而且在后面的测试中要保持一致。
# 数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
Cutout(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
读取数据
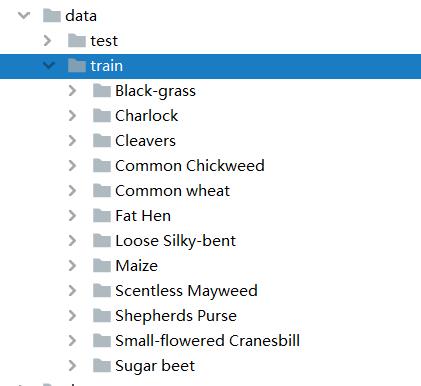
将数据集解压后放到data文件夹下面,如图:
然后我们在dataset文件夹下面新建 init.py和dataset.py,在datasets.py文件夹写入下面的代码:
# coding:utf8
import os
from PIL import Image
from torch.utils import data
from torchvision import transforms as T
from sklearn.model_selection import train_test_split
Labels = 'Black-grass': 0, 'Charlock': 1, 'Cleavers': 2, 'Common Chickweed': 3,
'Common wheat': 4, 'Fat Hen': 5, 'Loose Silky-bent': 6, 'Maize': 7, 'Scentless Mayweed': 8,
'Shepherds Purse': 9, 'Small-flowered Cranesbill': 10, 'Sugar beet': 11
class SeedlingData (data.Dataset):
def __init__(self, root, transforms=None, train=True, test=False):
"""
主要目标: 获取所有图片的地址,并根据训练,验证,测试划分数据
"""
self.test = test
self.transforms = transforms
if self.test:
imgs = [os.path.join(root, img) for img in os.listdir(root)]
self.imgs = imgs
else:
imgs_labels = [os.path.join(root, img) for img in os.listdir(root)]
imgs = []
for imglable in imgs_labels:
for imgname in os.listdir(imglable):
imgpath = os.path.join(imglable, imgname)
imgs.append(imgpath)
trainval_files, val_files = train_test_split(imgs, test_size=0.3, random_state=42)
if train:
self.imgs = trainval_files
else:
self.imgs = val_files
def __getitem__(self, index):
"""
一次返回一张图片的数据
"""
img_path = self.imgs[index]
img_path=img_path.replace("\\\\",'/')
if self.test:
label = -1
else:
labelname = img_path.split('/')[-2]
label = Labels[labelname]
data = Image.open(img_path).convert('RGB')
data = self.transforms(data)
return data, label
def __len__(self):
return len(self.imgs)
说一下代码的核心逻辑:
第一步 建立字典,定义类别对应的ID,用数字代替类别。
第二步 在__init__里面编写获取图片路径的方法。测试集只有一层路径直接读取,训练集在train文件夹下面是类别文件夹,先获取到类别,再获取到具体的图片路径。然后使用sklearn中切分数据集的方法,按照7:3的比例切分训练集和验证集。
第三步 在__getitem__方法中定义读取单个图片和类别的方法,由于图像中有位深度32位的,所以我在读取图像的时候做了转换。
然后我们在train.py调用SeedlingData读取数据 ,记着导入刚才写的dataset.py(from dataset.dataset import SeedlingData)
dataset_train = SeedlingData('data/train', transforms=transform, train=True)
dataset_test = SeedlingData("data/train", transforms=transform_test, train=False)
# 读取数据
print(dataset_train.imgs)
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
设置模型
- 设置loss函数为nn.CrossEntropyLoss()。
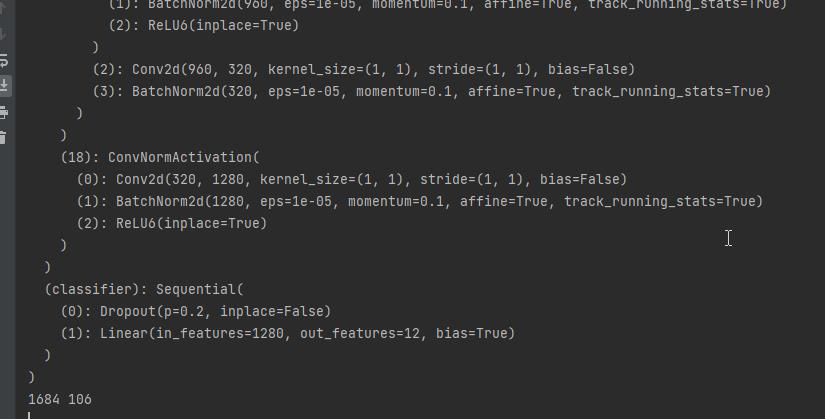
- 设置模型为mobilenet_v3_large,预训练设置为true,num_classes设置为12。
- 优化器设置为adam。
- 学习率调整策略选择为余弦退火。
# 实例化模型并且移动到GPU
criterion = nn.CrossEntropyLoss()
#criterion = SoftTargetCrossEntropy()
model_ft = mobilenet_v2(pretrained=True)
print(model_ft)
num_ftrs = model_ft.classifier[1].in_features
model_ft.classifier[1] = nn.Linear(num_ftrs, 12,bias=True)
model_ft.to(DEVICE)
print(model_ft)
# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.Adam(model_ft.parameters(), lr=modellr)
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer,T_max=20,eta_min=1e-9)
#model_ft=torch.load("model_33_0.952.pth")
定义训练和验证函数
# 定义训练过程
alpha=0.2
def train(model, device, train_loader, optimizer, epoch):
model.train()
sum_loss = 0
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)
data, labels_a, labels_b, lam = mixup_data(data, target, alpha)
optimizer.zero_grad()
output = model(data)
loss = mixup_criterion(criterion, output, labels_a, labels_b, lam)
loss.backward()
optimizer.step()
lr = optimizer.state_dict()['param_groups'][0]['lr']
print_loss = loss.data.item()
sum_loss += print_loss
if (batch_idx + 1) % 10 == 0:
print('Train Epoch: [/ (:.0f%)]\\tLoss: :.6f\\tLR::.9f'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item(),lr))
ave_loss = sum_loss / len(train_loader)
print('epoch:,loss:'.format(epoch, ave_loss))
ACC=0
# 验证过程
def val(model, device, test_loader):
global ACC
model.eval()
test_loss = 0
correct = 0
total_num = len(test_loader.dataset)
print(total_num, len(test_loader))
with torch.no_grad():
for data, target in test_loader:
data, target = Variable(data).to(device), Variable(target).to(device)
output = model(data)
loss = criterion(output, target)
_, pred = torch.max(output.data, 1)
correct += torch.sum(pred == target)
print_loss = loss.data.item()
test_loss += print_loss
correct = correct.data.item()
acc = correct / total_num
avgloss = test_loss / len(test_loader)
print('\\nVal set: Average loss: :.4f, Accuracy: / (:.0f%)\\n'.format(
avgloss, correct, len(test_loader.dataset), 100 * acc))
if acc > ACC:
torch.save(model_ft, 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')
ACC = acc
# 训练
for epoch in range(1, EPOCHS + 1):
train(model_ft, DEVICE, train_loader, optimizer, epoch)
cosine_schedule.step()
val(model_ft, DEVICE, test_loader)
完成上面的代码就可以运行了!待训练完成后,我们就可以进行下一步测试的工作了。
测试
这里介绍一种通用的测试方法,通过自己手动加载数据集然后做预测,具体操作如下:
测试集存放的目录如下图:
第一步 定义类别,这个类别的顺序和训练时的类别顺序对应,一定不要改变顺序!!!!
第二步 定义transforms,transforms和验证集的transforms一样即可,别做数据增强。
第三步 加载model,并将模型放在DEVICE里,
第四步 读取图片并预测图片的类别,在这里注意,读取图片用PIL库的Image。不要用cv2,transforms不支持。
import torch.utils.data.distributed
import torchvision.transforms as transforms
from PIL import Image
from torch.autograd import Variable
import os
classes = ('Black-grass', 'Charlock', 'Cleavers', 'Common Chickweed',
'Common wheat','Fat Hen', 'Loose Silky-bent',
'Maize','Scentless Mayweed','Shepherds Purse','Small-flowered Cranesbill','Sugar beet')
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = torch.load("model.pth")
model.eval()
model.to(DEVICE)
path='data/test/'
testList=os.listdir(path)
for file in testList:
img=Image.open(path+file)
img=transform_test(img)
img.unsqueeze_(0)
img = Variable(img).to(DEVICE)
out=model(img)
# Predict
_, pred = torch.max(out.data, 1)
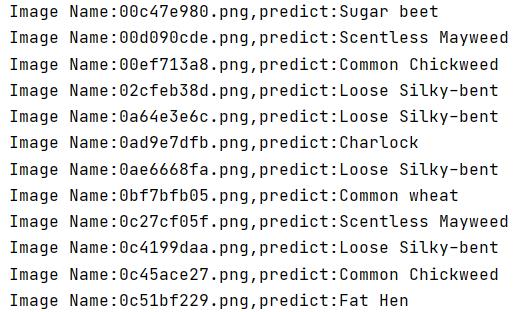
print('Image Name:,predict:'.format(file,classes[pred.data.item()]))
运行结果:
模型转化及推理
转onnx
模型可视化使用了netron,安装命令:
pip install netron
新建torch2onnx.py脚本,插入代码:
import torch
import torchvision
from torch.autograd import Variable
import netron
print(torch.__version__)
# torch --> onnx
input_name = ['input']
output_name = ['output']
input = Variable(torch.randn(1, 3, 224, 224)).cuda()
model = torch.load('model_59_0.938.pth', map_location="cuda:0")
torch.onnx.export(model, input, 'model_onnx.onnx',opset_version=12, input_names=input_name, output_names=output_name, verbose=True)
# 模型可视化
netron.start('model_onnx.onnx')
导入需要的包。
打印pytorch版本。
定义input_name和output_name变量。
定义输入格式。
加载pytorch模型。
导出onnx模型,这里注意一下参数opset_version在8.X版本中设置为13,在7.X版本中设置为12。
onnx推理
onnx推理需要安装onnx包文件,命令如下:
pip install onnx
pip install onnxruntime-gpu
新建test_onnx.py,插入下面的代码:
import os, sys
import time
sys.path.append(os.getcwd())
import onnxruntime
import numpy as np
import torchvision.transforms as transforms
from PIL import Image
导入包
def get_test_transform():
return transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = Image.open('11.jpg') # 289
img = get_test_transform()(image)
img = img.unsqueeze_(0) # -> NCHW, 1,3,224,224
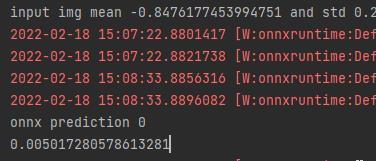
print("input img mean and std ".format(img.mean(), img.std()))
img = np.array(img)
定义get_test_transform函数,实现图像的归一化和resize。
读取图像。
对图像做resize和归一化。
增加一维batchsize。
将图片转为数组。
onnx_model_path = "model_onnx.onnx"
##onnx测试
session = onnxruntime.InferenceSession(onnx_model_path,providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider'])
#compute ONNX Runtime output prediction
inputs = session.get_inputs()[0].name: img
time3=time.time()
outs = session.run(None, inputs)[0]
y_pred_binary = np.argmax(outs, axis=1)
print("onnx prediction", y_pred_binary[0])
time4=time.time()
print(time4-time3)
定义onnx_model_path模型的路径。
加载onnx模型。
定义输入。
执行推理。
获取预测结果。
到这里onnx推理就完成了,是不是很简单!!!